@twoer2
2020-01-26T10:00:30.000000Z
字数 28752
阅读 805
Modelling and Visualization of High Dimensional Data
course
Curse of Dimensionality and Dimension Reduction
Facts:
- When the number of dimensions grows, the number of examples required to maintain a given sampling density grows exponentially.
- Humans have an extraordinary capacity to discern patterns and clusters in 1, 2 and 3-dimensions, but these capabilities degrade drastically for 4 or higher dimensions.
In practice, the curse of dimensionality means that, for a given sample size, there is a maximum number of features above which the performance of our classifier will degrade rather than improve:
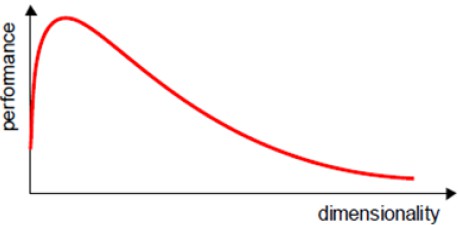
In most cases, the additional information that is lost by discarding some features is (more than) compensated by a more accurate mapping in the lower-dimensional space.
To conquer the curse of dimensionality, we often need dimension reduction. In fact, data in high dimensional space is not uniformly distributed. Often data is distributed in a lower dimension but presented in the high dimension. Recovering such a low-dimensional structure is a key to modelling high dimensional data in its very nature.
There are two methodologies of dimensionality reduction:
- Feature selection: choosing a subset of all the features.
- Feature extraction: creating a subset of new features by combinations.
However, reducing dimension leads to the problem of losing information.
PCA
Basic Algorithm
The goal of PCA (Principal Component Analysis) is to project the high-dimensional data onto a group of orthogonal unit vectors, where the variance of the projections is maximized. These vectors are called principal components.
Given a dataset of data points in a -dimensional space, .
- Subtract mean from data (where ), denote the centralized data with .
- Define projection of centred data point onto unit length vector :
- Choose to maximize variance of
where . Since is centralized, . Let ,
where is the empirical covariance matrix. (or for unbiased estimation)
- Optimize Lagrangian imposing constraint
where is the Lagrange multiplier.
- Setting the gradient w.r.t. to zero gives optimality condition
- We say that is an eigenvetor of with eigenvalue .
- Multiplying by on the left we get
so we should choose the eigenvector with the largest eigenvalue as to maximize the variance.
- The choice of is the 1st principal component.
- To derive the 2nd principal component, define the projection of the centred data onto another unit vector
Let . If is the 2nd principal component, it should follow the constraints that and are orthogonal, i.e. .
- is to maximize the variance of
- Optimize Lagrangian imposing constraints
where and are Lagrange multipliers.
- Setting the gradient w.r.t. to zero gives optimality condition
By Multiplying on the left, we get
Note that
and
Therefore,
- is also an eigenvector of with eigenvalue .
- Multiplying by on the left we get
so we could choose the eigenvector with the second largest eigenvalue as to maximize the variance. The choice of is the 2nd principal component.
- By repeating these steps, we could get the 3nd, 4th, ..., m-th principal components, which are the unit eigenvectors of with the 3nd, 4th, ..., m-th largest eigenvalues.
Summary:
- For a given dataset , subtracting the mean vector for all the instances in to achieve the centralized dataset denoted by .
- Calculate , finding out all eigenvalues, ranking them so that , and their corresponing eigenvectors, .
- Selecting top () largest eigenvectors of to form a project matrix .
- Encoding data point: , is a -dimensional vector encoding for the data point .
- Decoding (Reconstructing) data point: , is a -dimensional vector for the data point .
Dual Algorithm
For a () matrix, , is a matrix. It is often computationally infeasible in solve its eigenvalue problem. We can construct a matrix , which has
Then, we apply SVD (Singular Value Decomposition) on
Then transform into
It is obvious to see that
Since is an diagonal matrix, the column vectors of are eigenvectors of . Select first () columns of (which is the first principal components) to form a project matrix .
Summary:
- For a given dataset , subtracting the mean vector for all the instances in to achieve the centralized dataset denoted by .
- Calculate and apply SVD to . Then we achieve a matrix (i.e., ).
- Selecting first () columns of to form a project matrix .
Proportion of Variance
In practice, we can use Proportion of Variance (PoV) to determine an appropriate dimensionality in the PCA space:
When PoV >= 90%, the corresponding will be assigned to be .
Limitations of the standard PCA
- The dimensions of maximum data variance are not always the relevant dimensions for preservation. (RCA, LDA, ...)
- Sometimes it is better to find independent rather than pair-wise uncorrelated/orthogonal dimensions. (ICA, ...)
- The reduction of dimensions for complex distributions may need nonlinear processing. (Nonlinear PCA extension)
LDA
Linear Discriminant Analysis (LDA) is a method for high-dimensional analysis in the supervised learning paradigm as class labels are available in a dataset. The objective of LDA is to perform dimensionality reduction while maximizing the difference between the projected means of different classes and minimizing the variance of projections of each class.
Two Classes
Assume we have a set of -dimensional sample . of which belong to class , and to class . We seek to obtain a scalar by projecting the samples onto a line
The mean vector of each class in and feature space is
The difference between the projected means is
The matrix is called the between-class scatter. Similarly, the variance of each class (called the scatter) is
where
The matrix is called the within-class scatter.
The criterion function (Fisher criterion) is defined as
To find the maximum of , we derive and equate to zero
is an eigenvector of .
Note that and are scalars, so and are in the same direction. As well, the scaling of does not affect, so we can set
Summary:
- Estimate the within-class scatter matrix
where
- Compute the optimal projection vector
- Apply the projection to samples
Multiple Class
Denote the number of classes as . LDA can only produce at most feature projections. The projection matrix
The generalization of the within-class scatter is
where and
The generalization for the between-class scatter is
where
The total scatter matrix is defined as
Since , we can get
Similarly, we can get
Therefore,
(However, is not important is the algorithm of multiple class LDA. You can omit it)
Similarly, we define the mean vector and scatter matrices for the projected samples as
Since the projection is no long a scalar (it has dimensions), we then use the determinant of the scatter matrices to obtain a scalar objective function:
It can be shown that the optimal projection matrix is the one whose columns are the eigenvectors corresponding to the largest eigenvalues of the following generalized eigenvalue problem
Note that in , each is the product of two vectors, so is the sum of matrices of rank one or less, and therefore .
Ref: Rank Wiki. , .
At the mean time, , are linearly dependent, at least one could be represented by the others.
Note that , where , . Therefore,
where is the rank of . Since it has at most linearly independent columns, its rank is at most . Therefore, . This means that at most of the eigenvalues will be non-zero, and therefore LDA could reduce the samples to at most dimensions.
Summary:
- Estimate the within-class and between-class scatter scatter matrices
where
where
Compute the optimal projection matrix , where is the k-th eigenvector of .
Apply the projection to samples
Limitations of LDA
- LDA produces at most feature projections.
- LDA is a parametric method since it assumes unimodal Gaussian likelihoods. If the distributions are significantly non-Gaussian, the LDA projections will not be able to preserve any complex structure of the data, which may be needed for classification.
SOM
Self-Organizing Map (SOM) is a biologically inspired unsupervised neural network that approximates an unlimited number of input data by a finite set of nodes arranged in a low-dimensional grid (one or two-dimensional), where neighbor nodes correspond to more similar input data.
Each neuron in a SOM (an one or two-dimensional grid) is assigned a weight vector with the same dimensionality as the input space (or, weight space). What we do is like updating these weights to make this grid "cover" all samples. The updating strategy is as following:
- Initialize weights randomly.
- For each sample, find the closest weight vector, and call the corresponding neuron winner (Best Matching Unit, BMU).
- "Pull" weights towards the sample. Weights of neurons that are closer to the winner (on the map space, which is one or two-dimensional. The distance between neurons is defined as the Manhattan distance of them on the grid and "neighborhood" is dtermined on the lattice topology) will adapt more heavily than neurons that are further away. The following figure shows an adaptation on two-dimensional weight space:
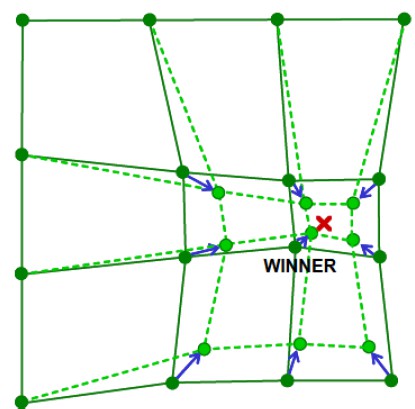
- After a number of iterations, the weights cover samples in an appropriate way. Note that during the iteration, we should decrease the learning rate and the neighborhood size (the parameter measures how much a neuron could affect other neurons) continuously to perform better training.
Summary:
- Initialize weights to some small, random values. is the number of neurons.
Repeat until convergence
- Select the next input sample
- Find the weight that best matches . The corresponding neuron of is the winner. The is the distance function.
- Update the weights of the winner and all its neightbors
where is the learning rate related to the number of iteration : . The is the neighborhood kernel function, where is the Manhattan distance between neurons and and is the neighborhood size. are hyper-parameters.
U-Matrix
For weight space of dimension less than 4, neurons could be visualized by their corresponding weight vectors. For high-dimensional data, a unified distance matrix (U-matrix) is constructed to facilitate the visualization. The shape of one kind of U-matrix is the same as the SOM network. The corresponding value in the U-matrix of the neuron is as the following:
where is the set of neighbors of . Distance between the weights of neighboring neurons gives an approximation of the distance between different parts of the underlying data. Dipict U-matrix in an image (heat map), similar colors depict the closely spaced nodes and distinct colors indicate the more distant nodes. Groups of similar colors can be considered as clusters, and the contrast parts as the boundary regions.
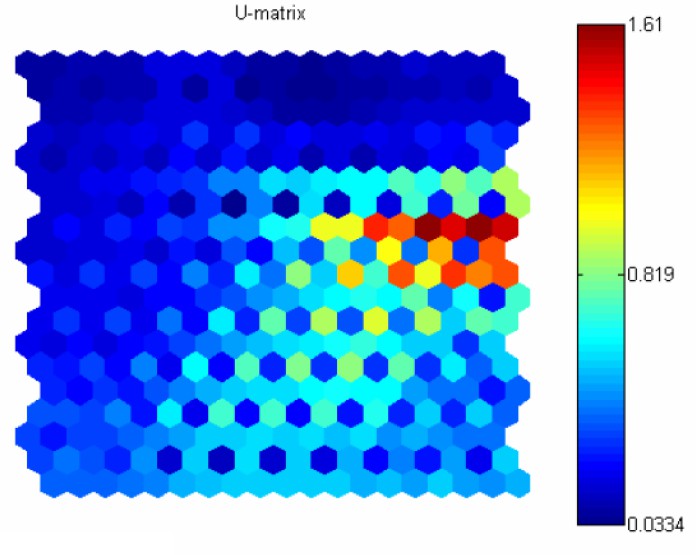
MDS
Multi-dimensional scaling (MDS) maps the distance between observations in a high dimensional space into a lower dimensional space. The goal is to find a configuration of points in the low dimensional space whose inter-point distance preserves dissimilarities of corresponding points in the higher dimension.
Iterative
Given points in dimensions, the distance between points and is . We want to find points in 2 (or 3) dimensions s.t. the distance between and is close to . We can look for by minimizing an objective function. The following are three possible objective functions (Stress):
Note that the s are constant. penalizes large absolute errors. penalizes large relative errors. is a compromise between the two before.
For each low dimensional point , update it by:
Summary:
- Determine the dimension of and initialize them randomly.
- Calculate the distance of samples in the original space .
- Repeat:
- Calculate the distance of samples in the target space , disparities (i.e. ) and the Stress.
- If , update each . Otherwise, break.
Analytic
Given the distance matrix in the high dimensional space, denote the low dimensional embeddings as and the low dimensional distance . It is expected that . Therefore,
where the matrix is the inner product matrix of embeddings. To simplify, we can centralize the embeddings , i.e. . Obviously, . Therefore,
where is the trace of , i.e. . So, we can get
If we let , we can derive that , where and .
After we derive the matrix , what we need next is to apply eigenvalue decomposition on : . Suppose there are non-zero eigenvalues in , they form the diagnoal matrix , and let denotes the corresponding eigenvectors, then can be represented as:
If we do not need strictly and expect to reduce dimensionality effectively, we can select a to construct .
Summary:
- Get the distance matrix in the high dimensional space.
- Compute the inner product matrix .
- Apply eigenvalue decomposition on .
- Select biggest eigenvalues and corresponding eigenvectors to construct the low dimensional embeddings .
MDS Family
- Metric-based MDS algorithms differ in
- Dissimilarity (distance) or similarity metrics in high dimensional space.
- Stress (objective) functions.
- Optimization procedure. The linear MDS are analytic solvable but cannot model complex (nonlinear) low dimensional manifold well. The nonlinear MDS often needs to use an iterative algorithm (e.g. Gradient Descent).
- The Nonmetric MDS (nMDS) only maintains the same ranking order in the low dimensional space as those in the high dimensional space.
ISOMAP
Isometric feature mapping (ISOMAP) is a non-linear MDS method for modelling manifold structure appearing in a high dimensional space. The ISOMAP preserves the geodesic distances between points, while the (normal) MDS preserves the Euclidean distances.
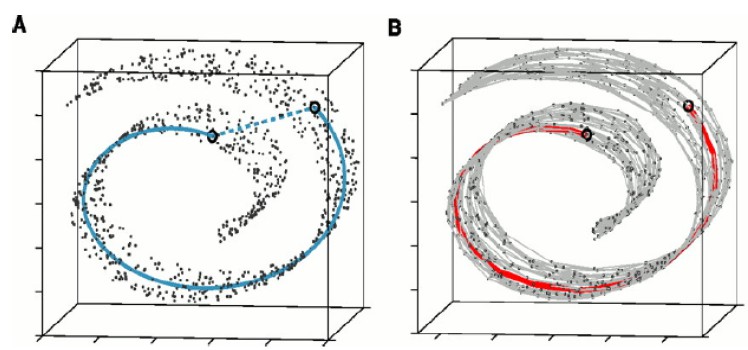
(The left figure depicts the Euclidean distance of two points, while the right figure depicts the geodesic distance between them (the red line))
For neighboring samples, the Euclidean distance provides a good approximation to geodesic distance. For distant points, the geodesic distance can be approximated with a sequence of steps between clusters of neighboring points. Therefore, the first step of the algorithm is to determine which points are neighbors in the manifold, based on the distance in the input space . The set of neighbors can be determined in two different ways:
- Connect each point to all points within a fixed radius .
- Connect each point to all of its nearest neighbors.
The first method may cause problems if the samples are sparse. The second one might be affected by outliers. These neighborhood relations are represented as a weighted graph . Then, we can estimate the geodesic distances between all pair of points on the maniford by computing their shortest path distances in the graph . This can be performed, e.g. using Dijkstra's Algorithm, Floyd–Warshall algorithm. The distance matrix is then inputted to the classical MDS algorithm (analytical solution).
Summary:
- Construct a neighborhood graph and compute the distance matrix (shortest path).
- Apply classical MDS algorithm to construct the low-dimensional embeddings .
Limitations of ISOMAP
- ISOMAP is guaranteed asymptotically to recover the true dimensionality and geometric structure of manifolds whose intrinsic geometry is that of a convex region of Euclidean space, but it may fail if the intrinsic parameter space is not convex.
- Points need to be sampled uniformly (densely) from a noiseless manifold to do geodesic approximation.
- There might not exist an isometric emdedding (i.e. the output of MDS might not be ideal).
- Suffer from a high computational cost and sensitive to noise.
- ISOMAP does not provide a mapping function .
LLE
Locally Linear Embedding (LLE) is another non-linear method for modelling manifold structure. It models the local geometry of samples in the high dimensional space, and expects that after projecting to the low dimensional space they can keep the local geometry. The local geometry is modeled by linear weights that reconstruct each data point as a linear combination of its neighbors.
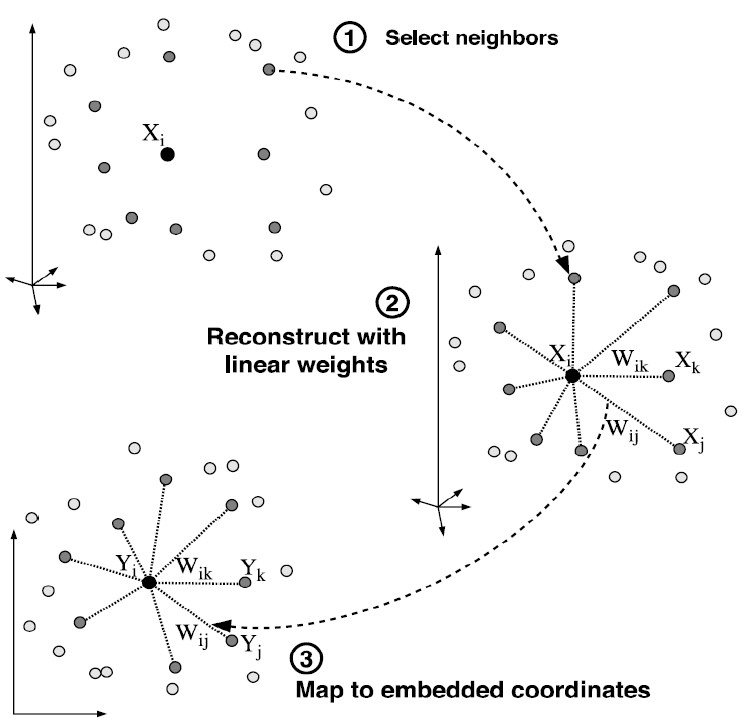
For each points
where the weight measures the contribution of the j-th sample to the reconstruction of the i-th sample. If is not the neighbor of , . These weights are computed by minimizing the reconstruction error
The reconstruction error is equivalent to
where , . using a Lagrange multiplier to enforce the constraint that :
Compute the derivative w.r.t :
Since , we can set and then
(Be careful that is a column vector. However, in the weight matrix , those weights related to are at the i-th row, because it is that denotes the weight of to , but not ).
The embedding vectors preserves the local geometry:
The cost is equivalent to
where
and is 1 if and 0 otherwise. It can be shown that
Since coordinates can be translated without affecting the cost function, we remove this degree of freedom by imposing that they are centered, i.e. . To avoid degenerate solutions, we constraint the embedding vectors to have unit covariance matrix, i.e. . According to the Rayleitz-Ritz theorem, the optimal embedding is found by computing the bottom eigenvectors. The bottom eigenvector is discarded and the remained eigenvectors form the embedding coordinates.
Summary:
- For each sample , Determine it neibhbors, and compute the weights for neighbors.
- Compute the matrix .
- Apply eigenvalues decomposition to . The bottom eigenvectors (the bottom one is discarded) form the embeddings.
Limitations of LLE
- Sensitive to noise
- Sensitive to non-uniform sampling of the manifold
- Unlike ISOMAP, no robust method to compute the intrinsic dimensionality
- No robust method to define the neighbourhood size K
- Does not provide a mapping, out-of-sample, though one can be learned in a supervised fashion from the pairs
