@twein89
2017-05-23T03:44:37.000000Z
字数 1273
阅读 836
pyspider介绍
爬虫,python
框架结构
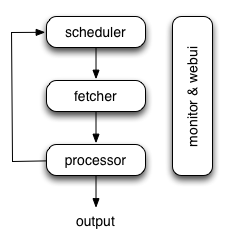
组件:
Scheduler
Scheduler从新任务队列里获取任务,决定哪些是新任务,哪些需要重新抓取,按优先级把任务排序并发送给Fetcher。并负责定时任务和失败任务重试Fetcher
Fetcher抓取页面然后发送给Processor,可以设置 Fetch method, headers, cookies, proxy, etag etcProcessor
执行脚本,进行页面解析和信息抽取(pyquery)
开发须知
抓取脚本编写
- BaseHandler
- TenderHandler
BaseHandler是框架的基类,TenderHandler继承了BaseHandler,重写on_result方法用来统一保存数据到数据库,实现在spider_tender/tdlib/tender_handler.py
几个常用的api
self.crawl(url, **kwargs)
self.crawl 是主要接口, 告诉框架 pyspider 哪些url(s) 需要抓取.
def on_start(self):self.crawl('http://scrapy.org/', callback=self.index_page)
age
控制任务的有效期。
@config(age=10 * 24 * 60 * 60)def index_page(self, response):...
@every(minutes=0, seconds=0)
method will been called every minutes or seconds
@every(minutes=24 * 60)def on_start(self):for url in urllist:self.crawl(url, callback=self.index_page)
save
用来在callback中传递参数
def on_start(self):self.crawl('http://www.example.org/', callback=self.callback,save={'a': 123})def callback(self, response):return response.save['a']
fetch_type
设为js可以抓取需要js渲染的页面
js_script
用来在页面中执行一段js脚本
def on_start(self):self.crawl('http://www.example.org/', callback=self.callback,fetch_type='js', js_script='''function() {window.scrollTo(0,document.body.scrollHeight);return 123;}''')
参考api文档
页面解析器pyquery文档
框架作者博客里有pyspider中文系列教程,可以先看这个
调试
想要调试一个项目比如zj_huzhou.py这个脚本
可以在本地用pyspider one命令调试,例如pyspider one zhejiang/zj_huzhou.py
