@twein89
2016-06-27T05:35:28.000000Z
字数 6021
阅读 785
Spark Tutorial:Learning Apache Spark
spark python pyspark
 +
+ 
Spark Tutorial: Learning Apache Spark
This tutorial will teach you how to use Apache Spark, a framework for large-scale data processing, within a notebook. Many traditional frameworks were designed to be run on a single computer. However, many datasets today are too large to be stored on a single computer, and even when a dataset can be stored on one computer (such as the datasets in this tutorial), the dataset can often be processed much more quickly using multiple computers.
Spark has efficient implementations of a number of transformations and actions that can be composed together to perform data processing and analysis. Spark excels at distributing these operations across a cluster while abstracting away many of the underlying implementation details. Spark has been designed with a focus on scalability and efficiency. With Spark you can begin developing your solution on your laptop, using a small dataset, and then use that same code to process terabytes or even petabytes across a distributed cluster.
During this tutorial we will cover:
- Part 1: Basic notebook usage and Python integration
- Part 2: An introduction to using Apache Spark with the PySpark SQL API running in a notebook
- Part 3: Using DataFrames and chaining together transformations and actions
- Part 4: Python Lambda functions and User Defined Functions
- Part 5: Additional DataFrame actions
- Part 6: Additional DataFrame transformations
- Part 7: Caching DataFrames and storage options
- Part 8: Debugging Spark applications and lazy evaluation
The following transformations will be covered:
select(),filter(),distinct(),dropDuplicates(),orderBy(),groupBy()
The following actions will be covered:
first(),take(),count(),collect(),show()
Also covered:
cache(),unpersist()
Note that, for reference, you can look up the details of these methods in the Spark's PySpark SQL API
Part 1: Basic notebook usage and Python integration
(1a) Notebook usage
A notebook is comprised of a linear sequence of cells. These cells can contain either markdown or code, but we won't mix both in one cell. When a markdown cell is executed it renders formatted text, images, and links just like HTML in a normal webpage. The text you are reading right now is part of a markdown cell. Python code cells allow you to execute arbitrary Python commands just like in any Python shell. Place your cursor inside the cell below, and press "Shift" + "Enter" to execute the code and advance to the next cell. You can also press "Ctrl" + "Enter" to execute the code and remain in the cell. These commands work the same in both markdown and code cells.
# This is a Python cell. You can run normal Python code here...print 'The sum of 1 and 1 is {0}'.format(1+1)The sum of 1 and 1 is 2
# Here is another Python cell, this time with a variable (x) declaration and an if statement:x = 42if x > 40:print 'The sum of 1 and 2 is {0}'.format(1+2)The sum of 1 and 2 is 3
(1b) Notebook state
As you work through a notebook it is important that you run all of the code cells. The notebook is stateful, which means that variables and their values are retained until the notebook is detached (in Databricks) or the kernel is restarted (in Jupyter notebooks). If you do not run all of the code cells as you proceed through the notebook, your variables will not be properly initialized and later code might fail. You will also need to rerun any cells that you have modified in order for the changes to be available to other cells.
# This cell relies on x being defined already.# If we didn't run the cells from part (1a) this code would fail.print x * 284
(1c) Library imports
We can import standard Python libraries (modules) the usual way. An import statement will import the specified module. In this tutorial and future labs, we will provide any imports that are necessary.
# Import the regular expression libraryimport rem = re.search('(?<=abc)def', 'abcdef')m.group(0)Out[5]: 'def'
# Import the datetime libraryimport datetimeprint 'This was last run on: {0}'.format(datetime.datetime.now())This was last run on: 2016-06-27 02:29:31.772457
Part 2: An introduction to using Apache Spark with the PySpark SQL API running in a notebook
Spark Context
In Spark, communication occurs between a driver and executors. The driver has Spark jobs that it needs to run and these jobs are split into tasks that are submitted to the executors for completion. The results from these tasks are delivered back to the driver.
In part 1, we saw that normal Python code can be executed via cells. When using Databricks this code gets executed in the Spark driver's Java Virtual Machine (JVM) and not in an executor's JVM, and when using an Jupyter notebook it is executed within the kernel associated with the notebook. Since no Spark functionality is actually being used, no tasks are launched on the executors.
In order to use Spark and its DataFrame API we will need to use a SQLContext. When running Spark, you start a new Spark application by creating a SparkContext. You can then create a SQLContext from the SparkContext. When the SparkContext is created, it asks the master for some cores to use to do work. The master sets these cores aside just for you; they won't be used for other applications. When using Databricks, both a SparkContext and a SQLContext are created for you automatically. sc is your SparkContext, and sqlContext is your SQLContext.
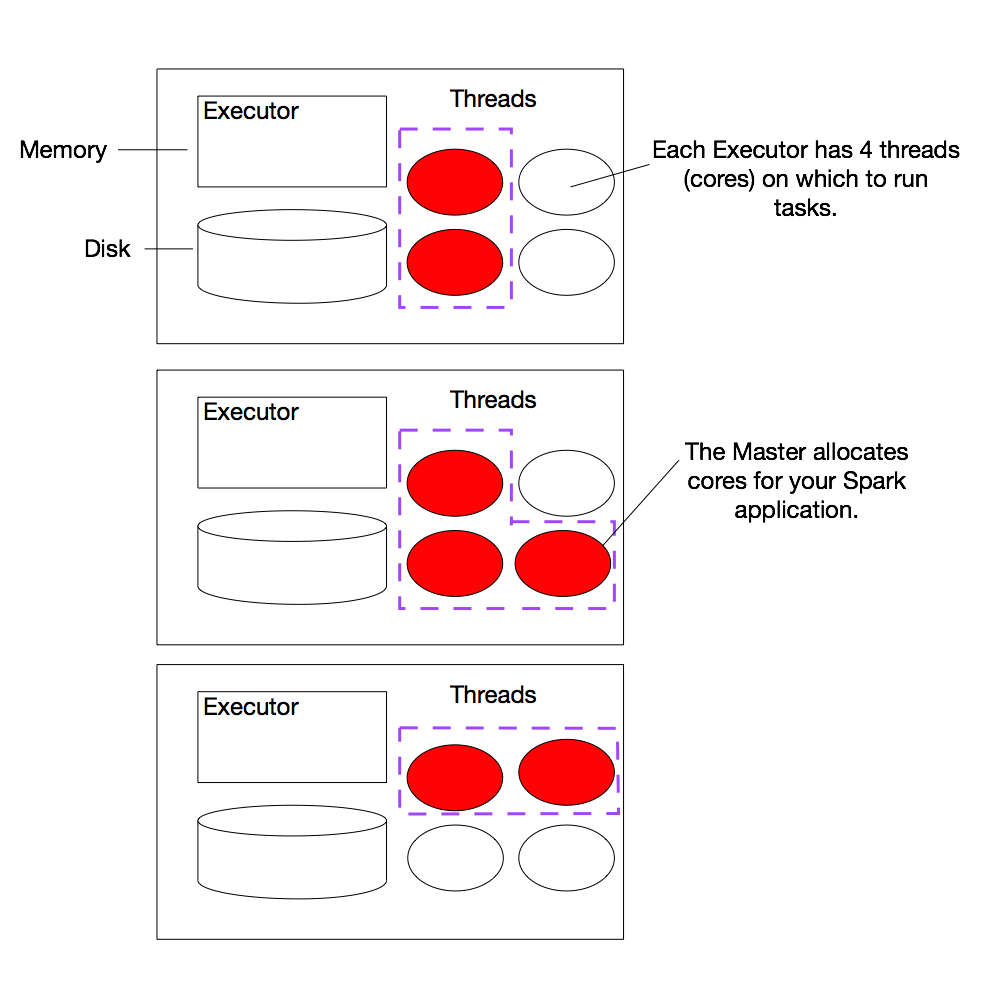
(2a) Example Cluster
The diagram shows an example cluster, where the slots allocated for an application are outlined in purple. (Note: We're using the term slots here to indicate threads available to perform parallel work for Spark.
Spark documentation often refers to these threads as cores, which is a confusing term, as the number of slots available on a particular machine does not necessarily have any relationship to the number of physical CPU
cores on that machine.)
You can view the details of your Spark application in the Spark web UI. The web UI is accessible in Databricks by going to "Clusters" and then clicking on the "Spark UI" link for your cluster. In the web UI, under the "Jobs" tab, you can see a list of jobs that have been scheduled or run. It's likely there isn't any thing interesting here yet because we haven't run any jobs, but we'll return to this page later.
At a high level, every Spark application consists of a driver program that launches various parallel operations on executor Java Virtual Machines (JVMs) running either in a cluster or locally on the same machine. In Databricks, "Databricks Shell" is the driver program. When running locally, pyspark is the driver program. In all cases, this driver program contains the main loop for the program and creates distributed datasets on the cluster, then applies operations (transformations & actions) to those datasets.
Driver programs access Spark through a SparkContext object, which represents a connection to a computing cluster. A Spark SQL context object (sqlContext) is the main entry point for Spark DataFrame and SQL functionality. A SQLContext can be used to create DataFrames, which allows you to direct the operations on your data.
Try printing out sqlContext to see its type.
