@rianusr
2019-08-13T02:07:11.000000Z
字数 1161
阅读 3632
第六章:机器学习01:特征工程--04特征选择
06-机器学习
1 特征选择
1.1 特征选择与降维的差异

1.2 为什么要进行特征选择

1.3 特征选择的方法
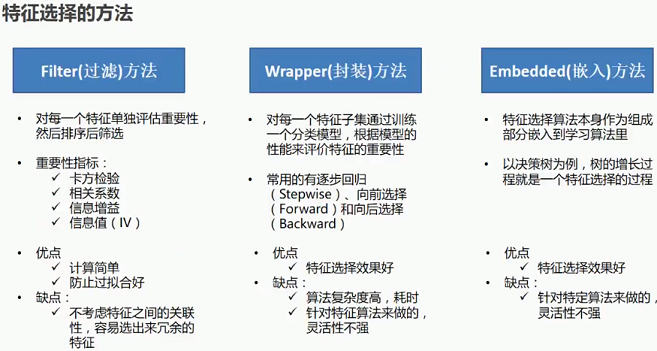
2 特征选择之单特征重要性评估-- Filter(过滤)方法
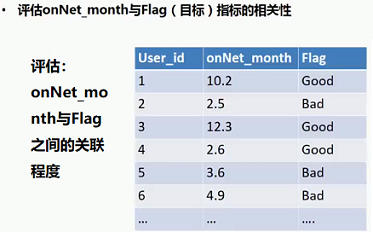
2.1 具体示例:
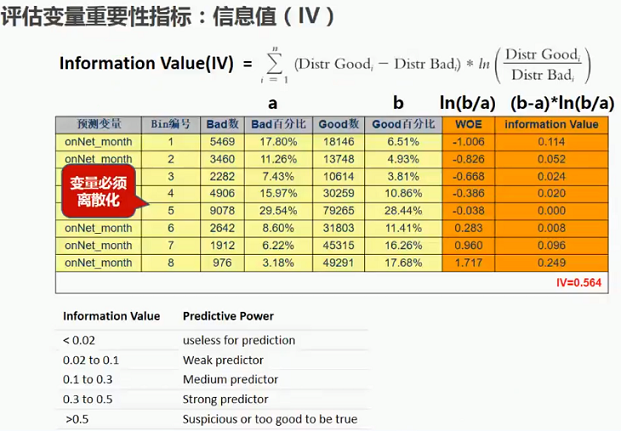
2.1.1 评估变量重要性指标:信息值(IV)
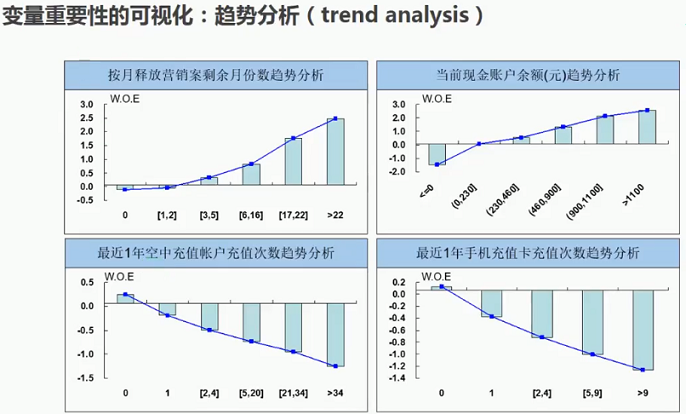
2.1.2 变量重要性的可视化:趋势分析(Trend analysis)
2.3 更多的评估指标

3 代码演示:单特征重要性评估 -- 基于pandas
import numpy as npimport pandas as pddef information_value(target,feature):"""计算变量的信息值:param target:ndarray,真实值,1=正例,0=负例:param feature:ndarray,离散变量:return:"""iv_table=pd.DataFrame({"feature":feature,"y":target})tot_good=np.sum(target)tot_bad=len(target)-tot_goodiv_table=iv_table.groupby("feature").agg({"y":{"bad_count":lambda x:len(x)-np.sum(x),"good_count":np.sum,}})["y"]iv_table["bad_percent"]=iv_table["bad_count"]/tot_badiv_table["good_percent"]=iv_table["good_count"]/tot_goodiv_table["woe"]=np.log(iv_table["good_percent"]/iv_table["bad_percent"])iv_table["iv"]=(iv_table["good_percent"]-iv_table["bad_percent"])*iv_table["woe"]iv_value=np.sum(iv_table["iv"])return iv_value,iv_table[["bad_count","bad_percent","good_count","good_percent","woe","iv"]]titanic=pd.read_csv(path) #读取数据titanic.head()feature=titanic.Pclasstarget=titanic.Survivediv_value,iv_table=information_value(target,feature)print(iv_table)print("information_value:",iv_value)
4 特征工程课程总结:

