@rianusr
2019-08-13T02:06:59.000000Z
字数 1571
阅读 3439
第六章:机器学习01:特征工程--03数据降维
06-机器学习
1 数据降维
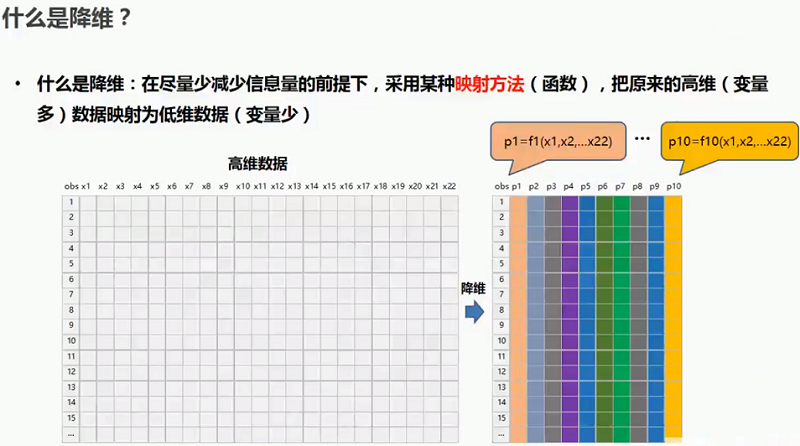
1.1 什么是降维
1.2 为什么要降维

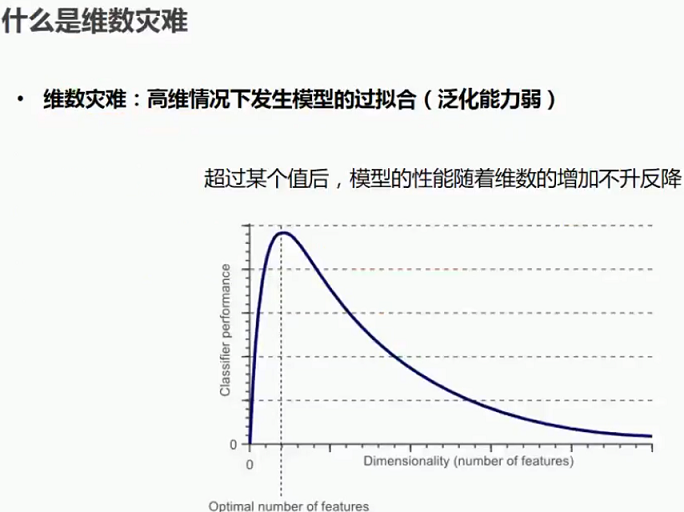
1.3 什么时维数灾难
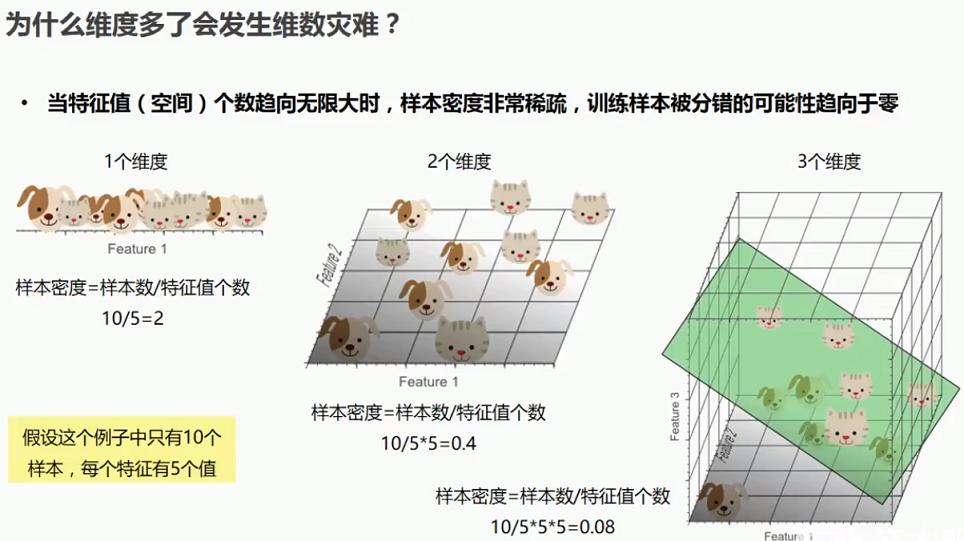
1.4 为什么维数多了之后会发生维数灾难
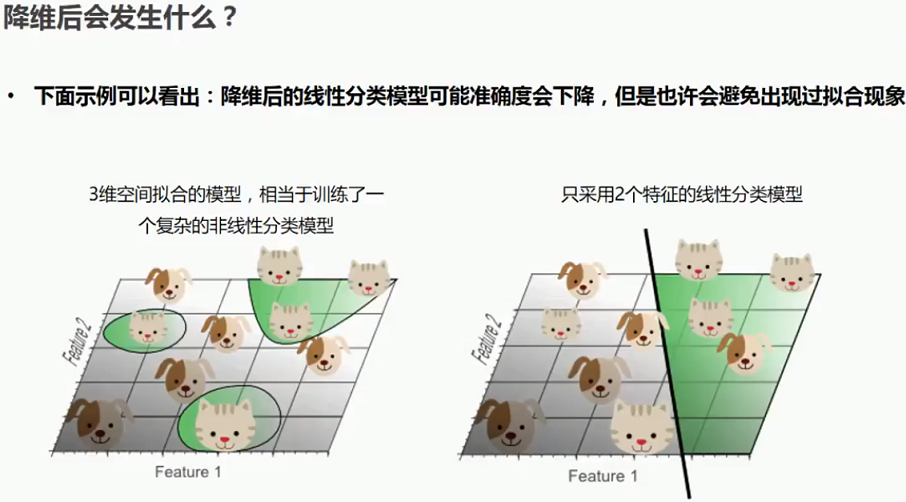
1.5 降维之后
1.6 避免维数灾难的方法
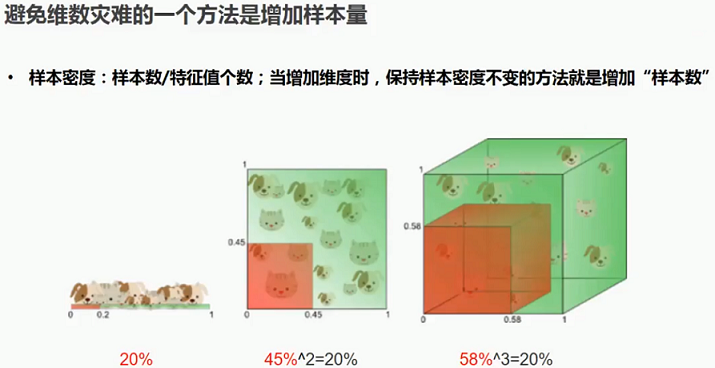
1.7 常用的数据降维方法

2 数据降维之主成分分析(PCA)-- 无监督降维技术
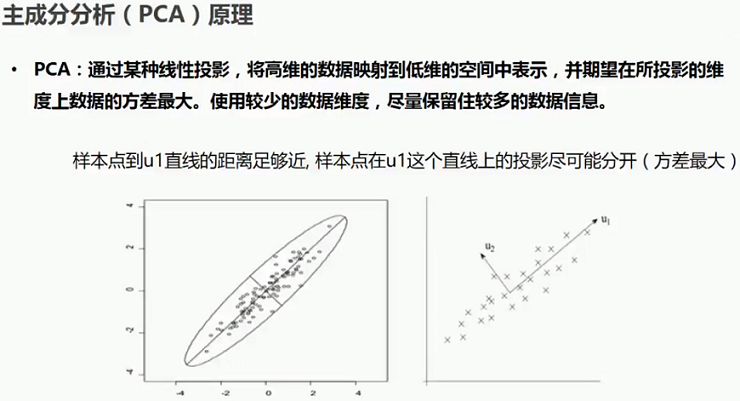
2.1 主成分分析(PCA)原理
2.2 主成分分析(PCA)操作流程
2.2.1 主成分分析(PCA)操作流程-第一步
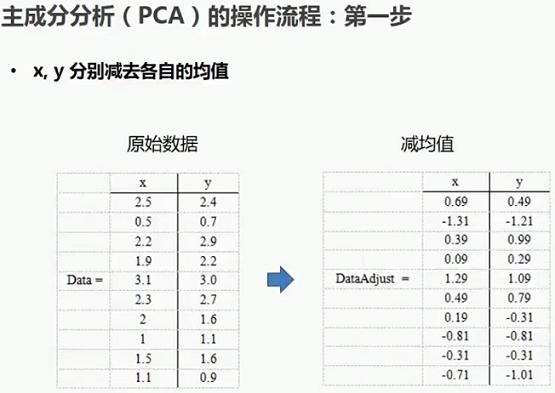
2.2.1 主成分分析(PCA)操作流程-第二步

2.2.1 主成分分析(PCA)操作流程-第三步

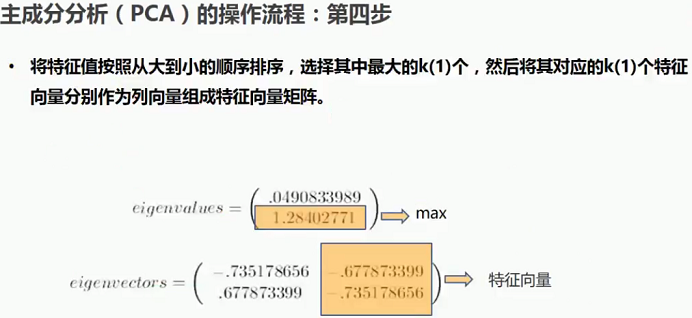
2.2.1 主成分分析(PCA)操作流程-第四步
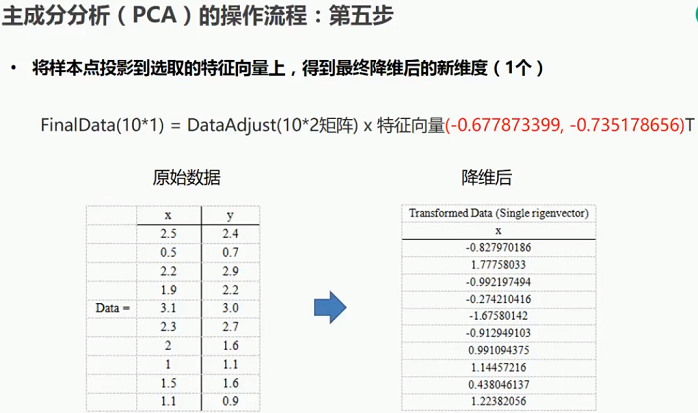
2.2.1 主成分分析(PCA)操作流程-第五步
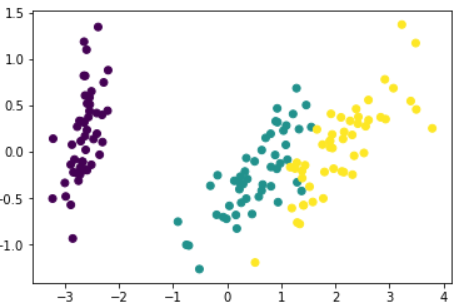
3 PCA降维代码实现(基于sklearn.decomposition模块下的PCA模块)
from sklearn import datasets #获取内置数据iris=datasets.load_iris() #导入iris数据x=iris.datay=iris.targetprint(x[:10])print(y[:10])# 构建PCA模型from sklearn.decomposition import PCA# sklearn.decomposition.PCA(n_components=None,cpopy=True,whiten=False)# n_components:主成分个数# cpopy:是否复制一份原始数据,default=Ture# whiten:白化,使用每个特征具有相同的方差,default=Falsepca=PCA(n_components=3) # 定义一个PCA模型pca.fit(x) # fit()函数x_new=pca.transform(x) # transform()函数print(x_new[:5])# x_new=pca.fit_transform(x) #fit_transform -- 可以替代fit()和transform()#主成分解释方差占比print(pca.explained_variance_ratio_)print(pca.explained_variance_)#PCA降维后可视化pca=PCA(n_components=2) #降到2维之后图表进行展示pca.fit(x)x_new = pca.transform(x)import matplotlib.pyplot as plt%matplotlib inlineplt.scatter(x_new[:,0],x_new[:,1],marker="o",c=y)plt.show()
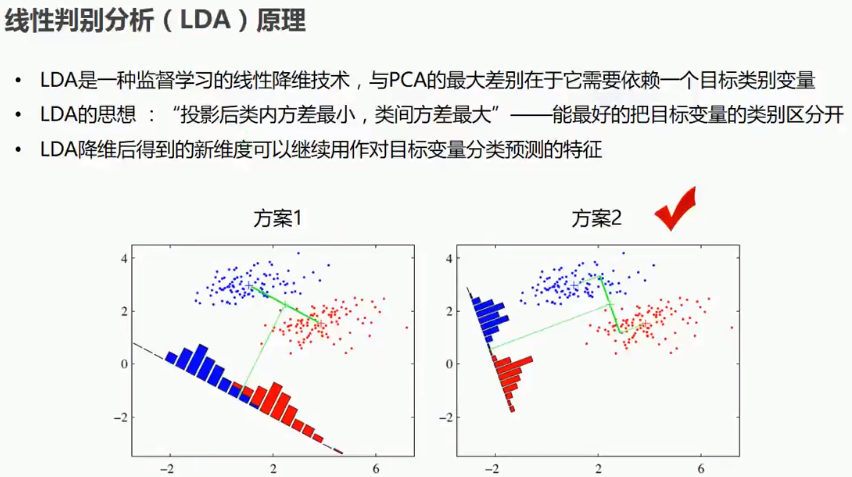
4 数据降维之线性判别分析(LDA)--监督学习(引入目标变量)降维
4.1 LDA分析原理
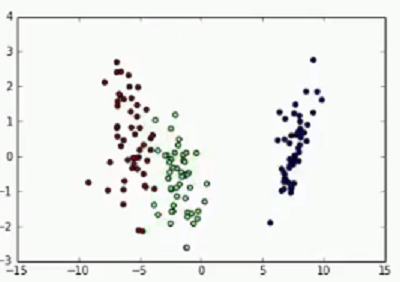
5 LDA分析代码实现 -- 基于sklearn
from sklearn import datasets#导入iris数据iris=datasets.load_iris() #获取内置数据x=iris.datay=iris.targetprint(x[:10])print(y[:10])#LDA降维from sklearn.lda import LDAimport matplotlib.pyplot as pltlda=LDA(n_components=2) #定义一个LDA模型x_new = lda.fit_transform(x,y) #fit()、transfrom()之后产生新的数据集print(x_new[:5])lda.predict(x) # predict()函数lda.score(x,y)plt.scatter(x_new[:,0],x_new[:,1],marker="o",c=y)plt.show()
6 总结:
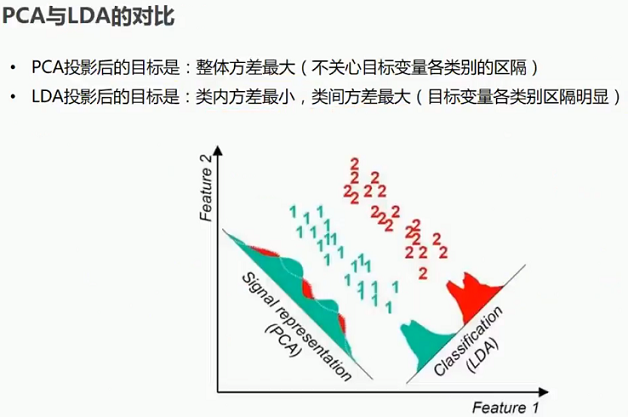
6.1 PCA与LDA进行对比
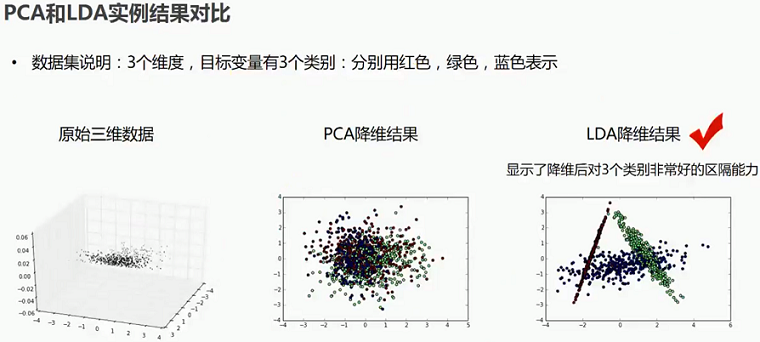
6.2 PCA与LDA实例结果对比
6.3 PCA和LDA的使用总结:

