@gongsheng
2018-01-13T05:37:11.000000Z
字数 2352
阅读 1434
python 图片转字符画
python
本篇的重点是实验过程中牵扯的很多知识。最终效果只是个附属品,原因之一:字符数(选取了70个字符)和它的排列情况还没达到使字符画精致的程度。
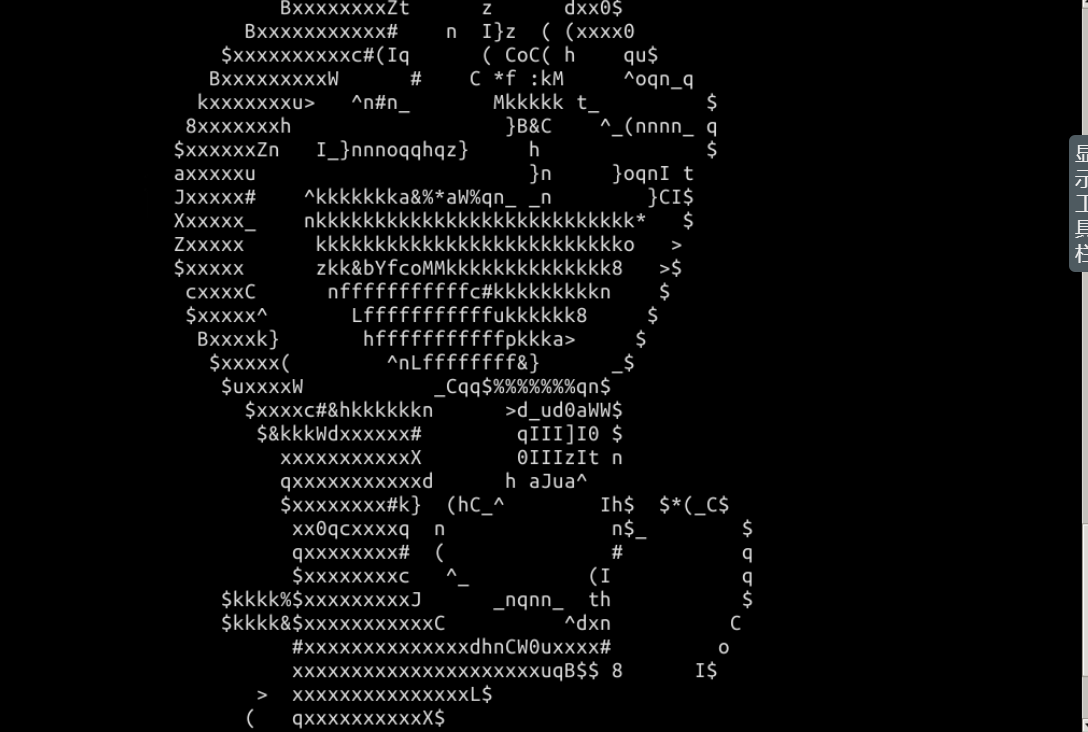
先看效果:
原图:

效果图(少部分未能截取):
你将在本文接触到这些词:
- PIL
- pillow
- argparse
- 映射
- r/g/b/a
- 灰度
1. 准备
在命令 pip install pillow 安装 pillow(python 的图像处理库)。
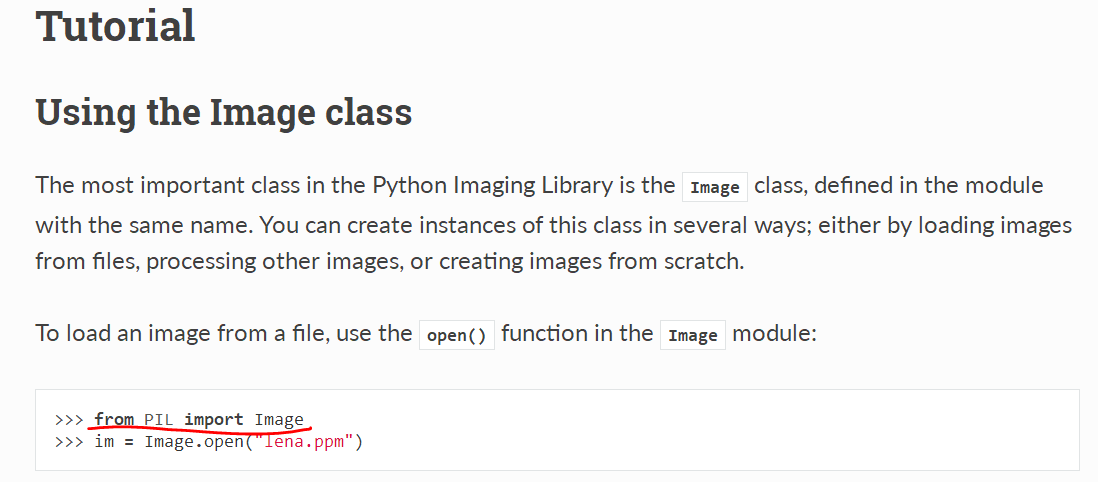
pillow官方文档 中规定,导入包的方式为:
from PIL import Image
而不是平常的 import pillow
官方文档截图(注意标记):
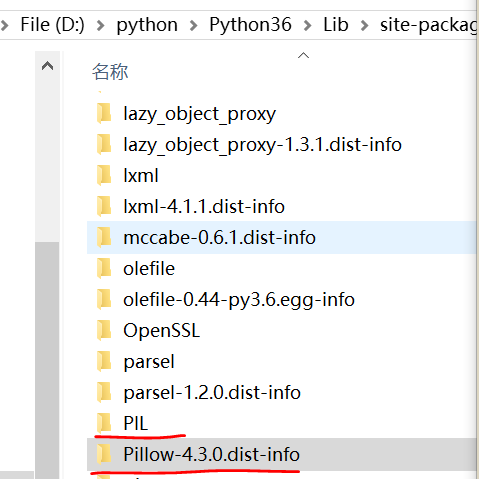
注 1:PIL 图像处理库很遗憾地只支持 Python2,但是它的分支 pillow 弥补了位置。安装之后你会发现 site-packages 文件夹里除了 pillow 还有 PIL 库,但你绝对不能按照惯性的导包思路操作,因为那是官方规定。
注 2:因为 pillow 的依赖包 olefile 存在无关紧要的一个编码 bug (olefile 的作者在 GitHub 提到),但是它会让你安装 pillow 不是那么顺利,在
pip install pillow 时,工具自动下载并安装它的依赖包,虽然报了编码错误,olefile 还是完成安装,在这基础上,pillow 需要再次 pip install。
报错:
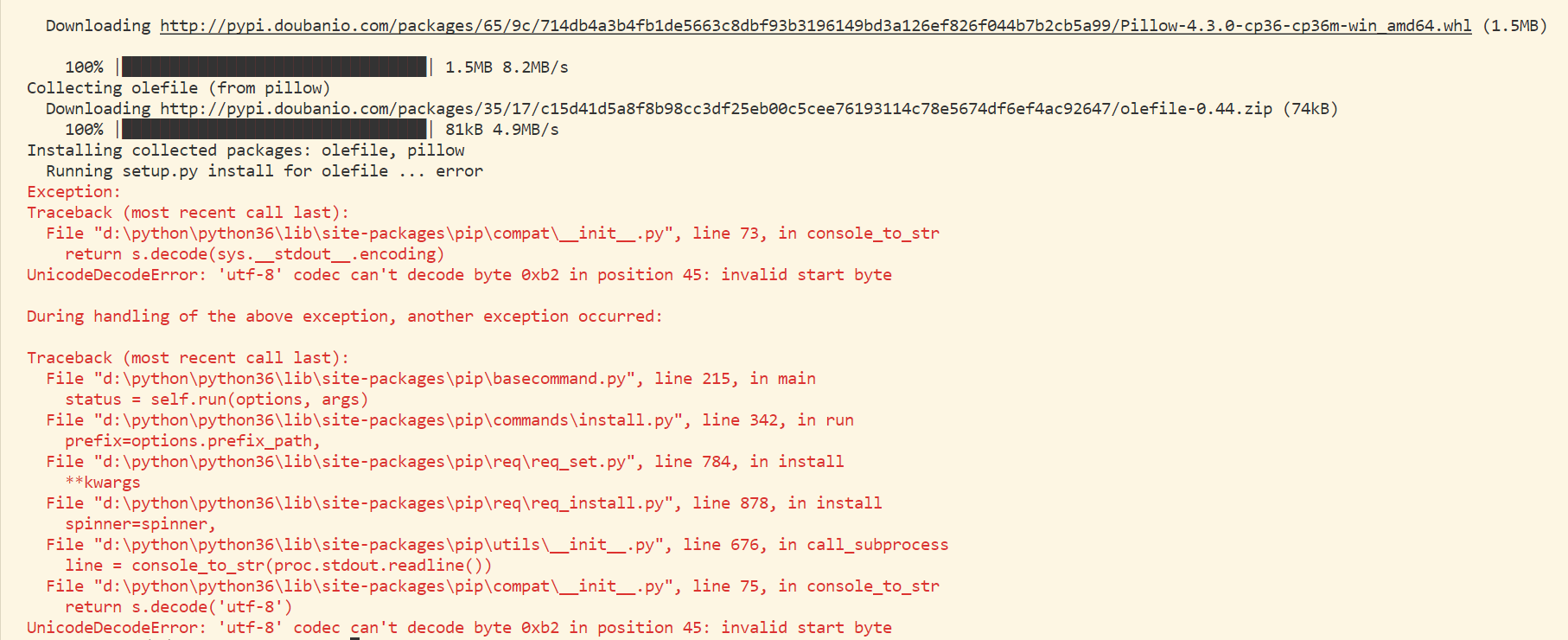
pillow的安装停止(pip show 没有显示 pillow 的信息):

2. 贴代码逐行分析
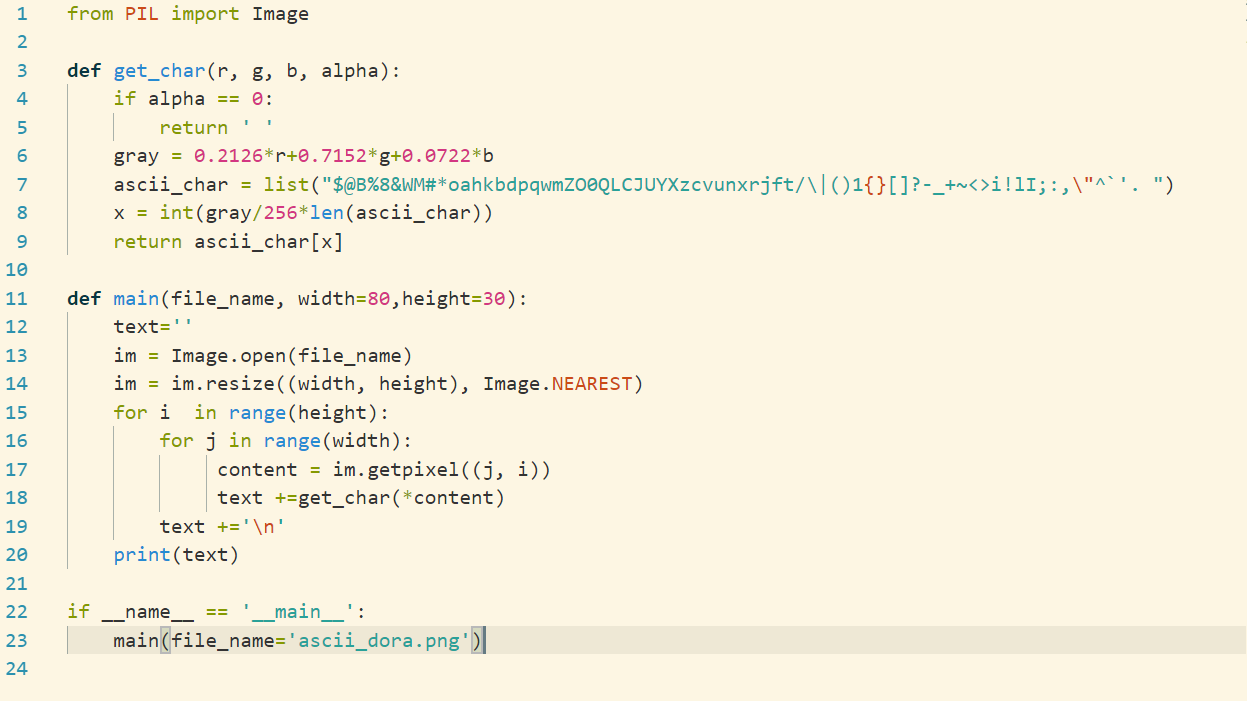
到这里,如果你的目的只是字符画,这个教程就结束了,只要你懂得如何运行一个 Python 代码文件,就可以得到最终效果。
符号解释:-1 为代码第1行,代码解释从起始行开始,无结束行
- -1
从 PIL 库中导入 Image 模块(非抽象的描述就是从 PIL 文件夹中导入 Image.py,这个文件中有 Image 类,类内有 open()属性(方法 ))
- -3
r:red; g:green;b:blue;alpha:透明度,每一个的值范围都是 0~255,alpha 不好理解,它的作用只判断自身是否为0。
没有判断 alpha 为 0 的效果如下:

- -6
gray = 0.2126*r+0.7152*g+0.0722*b
这是代码中的第一个重要式子,是科学公式,gray 就是我们要算的灰度值,它对 rgb 取不同比例得出,三个系数和为 1, 所以 gray 的上限值为 255 。下限0 。
- -7
list() 这个函数将字符串转换为列表,所以 ascii_char 的值是列表(这里含70个字符):
['$', '@', 'B', '%', '8', '&', 'W', 'M', '#', '*', 'o', 'a', 'h', 'k',
'b', 'd', 'p', 'q', 'w', 'm', 'Z', 'O', '0', 'Q', 'L', 'C', 'J', 'U',
'Y', 'X', 'z', 'c', 'v', 'u', 'n', 'x', 'r', 'j', 'f', 't', '/', '\',
'|', '(', ')', '1', '{', '}', '[', ']', '?', '-', '_', '+', '~', '<',
'>', 'i', '!', 'l', 'I', ';', ':', ',', '"', '^', '`', "'", '.', ' ']
- -8
x = int(gray/256*len(ascii_char))
这是第二个重要式子。它将灰度值映射到列表里的字符上。你可以把分母的 256 换成其他值,但是它要在一个范围内,最终目的是把 0~255 映射为 0~69,所以你取的值不能使x越界(为说明方便,分母为 a,那么a要满足:
255 < a <258.695652,由以下两个式子推导)
使
这能保证x的取值不会是70及以上。
并且当 gray=255 时,
这能保证x最大值能取到69
- -14
resize() 更改图片的宽高,规定 width 和 height 必须作为一个元组传入,Image.NEAREST, NEAREST 最近的,表示更改最近打开的图片。 - -15
图片都是一行一行打印出来的,所以这里用了两层循环。第 j 列和第 i 行作为元祖传入 getpixel(),返回值也是一个元祖,是第 j 列 第 i 行的像素的 4 个图象值,包含(R,G,B,A),*取出 content 的每个值,传入 get_char(),输出一行,打一个换行。text 用相加的方式把字符包括换行连接起来 - -22
这一行仅仅表示 ascii.py 作为文件运行,如果它作为模块被其他 python 文件导入,则不需要这两行代码。
源码:
from PIL import Imagedef get_char(r, g, b, alpha):# if alpha == 0:# return ' 'gray = 0.2126*r+0.7152*g+0.0722*bascii_char = list("$@B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\|()1{}[]?-_+~<>i!lI;:,\"^`'. ")x = int(gray/256*len(ascii_char))return ascii_char[x]def main(file_name, width=80,height=30):text=''im = Image.open(file_name)im = im.resize((width, height), Image.NEAREST)for i in range(height):for j in range(width):content = im.getpixel((j, i))text +=get_char(*content)text +='\n'print(text)if __name__ == '__main__':main(file_name='ascii_dora.png')
注:图片和 python 文件同目录。
