@feuyeux
2016-07-09T14:56:13.000000Z
字数 5543
阅读 3756
流式处理中的棘手问题系列:第一篇 放弃Lambda架构
流处理 Kafka Samza
我们生活在这样一个时代,一旦世界各地有事件发生,我们就想知道与之相关的事件;一个根据我们的好恶,即时更新数字内容的时代;一个充满信用卡欺诈、安全隐患、设备一旦故障,站点一旦中断需要立即修复的时代。这就是按规模扑捉事件并实时处理的时代。实时事件处理(流式处理)虽然不是新生事物,但现在却成为普遍存在,并已达到很大规模。
流式处理存在很多棘手的问题,这个系列将讨论其中的一些重要问题,正是我们在LinkedIn遇到并正试图解决的。本文是这一个系列的第一篇。
我将在这篇文章中,着重探讨在流式处理应用中,人们经常使用Lambda架构的主要原因,并提出替代方案。关于Lambda架构的解释,之前已经有很多资料,因此在此我将不再冗述相关基本知识。Lambda虽然解决了流处理应用中的一些重要问题,但这种架构存在一些关键问题:比如,建立热(近线)和冷(离线)处理管线路径上的重复开发工作、再处理的额外开销,以及在提供服务之前,合并在线和离线结果的开销等。
需要说明的是,本文没有覆盖离线数据分析场景,现有的Hadoop和基于Spark的批处理已经很好地解决这部分内容。尽管本文中讨论的大多数流式处理问题,LinkedIn是用Apache Samza来解决的,但这也适用于其他的流式处理系统。
现在让我们一起深入讨论为什么开发人员倾向于使用重复的(近线+离线)处理模型吧。
1.让流式处理生成准确的结果
这是一个很好的研究区域,而且关于这个问题,已经有一些优秀的论文。然而,让人不能容易理解的是,为什么流式处理不能一直产生准确的结果。为了显示这个问题,让我近距离观察一个例子来说明这一问题在LinkedIn是多么常见。
LinkedIn部署了多地理分布的数据中心。为了应对网站的问题,我们一周会有多次将用户业务在数据中心之间透明地故障转移。现在,假设我们有一个流式处理应用,当用户观看一则广告(AdViewEvent)的时候,会生成一个事件流(Kafka的topic),然后当用户点击广告(AdClickEvent)的时候,生成另一个事件流。这个应用还会生成AdQualityEvent事件以指示广告是好还是坏。这个应用的逻辑可以很简单:如果用户在收看广告的一分钟之内点击,那么这是一条好广告。
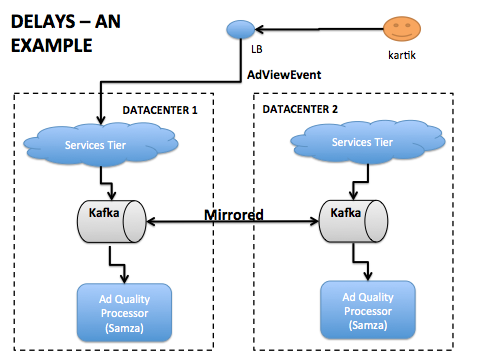
如上图所示,事件被复制到两个数据中心,从而使流处理器可以从两个数据中心获取所有事件的超集。
在正常操作下,流处理器在接收AdViewEvent后的一分钟之内获得AdClickEvent。然而,当有一个数据中心发生故障转移,一个会员的会话可能在DataCenter1上产生了AdViewEvent,但是却在DataCenter2上产生了AdClickEvent,如下图所示。
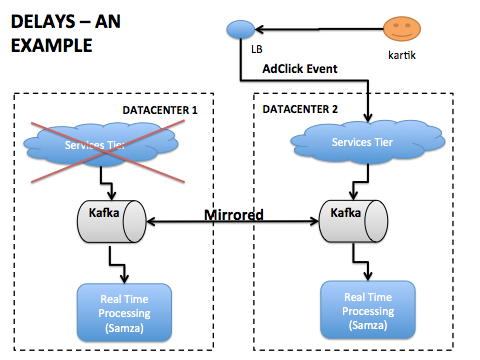
在上图所示的数据中心故障转移期间,有可能发生“迟到”现象,即流处理器可能会在接收AdViewEvent之后几分钟看到AdClickEvent。一个写得不好的流处理器可能推断该广告是一个低质量的广告,其实相反,这则广告可能一直都不错。另一种异常现象是流处理器可能会在看到相应的AdViewEvent之前,看到AdClickEvent。为了确保流处理器的输出是正确的,必须要有逻辑来处理这种“乱序消息的到来。”
在上面的例子中,数据中心的地理分布性质可以很容易地解释的延迟。然而,即使在同一数据中心,由于GC问题、Kafka集群升级、分区重新平衡,以及其它分布式系统天然存在的现象,延迟依然可能存在。
Lambda架构是否可以解决这个问题?
在LinkedIn,很多源事件流会被发送到两个基于Samza的实时流式处理系统,以及Hadoop和基于Spark的离线批处理系统。
一个常见的假设是,因为批处理会在一个较大的时间窗口内(例如一小时)发生,所以引起误差的迟到和乱序数据,通常只在时间窗口的间隔边缘发生。举例来说,我们有一个处理一小时时长数据的Hadoop离线作业,其最开始的五分钟和最后的五分钟数据有迟到现象。是否对于60分钟的数据来说,作业内的五分钟的窗口微不足道呢?答案取决于你正在开发的应用是什么类型的。在大多数情况下,这些不准确性是不能接受的。如果我们运行的批处理作业是每15分钟的,误差会变得更加明显。
在LinkedIn,为了解决一些高价值数据集批处理中的不准确,我们采用了以下正确性检查:
比如,为了处理中午12点到下午1点之间发生的事件,我们会在下午1点20分启动Hadoop作业。留出20分钟,是为了把数据通过Kafka管道镜像存储到HDFS。在LinkedIn的Kafka生态系统中有一个名为Audit Service的服务,用于跟踪统计一段时间内,每个生产集群在一组topic上发布的消息数量。在小时级Hadoop作业开始之前,它会查询Audit Service,获取相关topic在最近一小时有多少事件产生并存储于Kafka。然后,它会检查从HDFS摄取的Kafka事件数量是否与生产群集产生的事件数目大体匹配。
正如你所看到的,批处理作业中的准确性需要投入大量的悉心关注。虽然上面的方法提高了批处理作业的准确性,但要面对如果管道中存在延迟,那么正确性检查失败,批处理作业将无法运行的问题。考虑到为数据移动到HDFS的过程,也可以强制批处理作业在一段时间(在上述例子中是20分钟)后开始运行。
相反,大多数用户希望应用在生成事件后被尽快处理,并且在发生迟到和乱序事件时,具有更新结果的能力。
那么如何才能提高准确度呢?
在谷歌的论文MillWheel和Dataflow中对此问题有详细的讨论。Tyler Akidau继续在这篇博客中解释了为什么流处理器可以处理消息迟到和乱序。大多数流式处理平台,为应用开发者提供了管道以隐藏迟到和乱序的复杂性。
LinkedIn和其他几家公司使用Apache Samza流式处理。除了Samza的其他主要改进,我们在一组核心操作上,让应用很容易执行窗口,并加入了具有高度精确结果的事件流。核心逻辑是相同的:
为保留期较长的Samza作业存储所有输入事件。如果Samza应用执行单纯的聚合(像取平均值/累加等等),那么就没有必要存储所有输入事件。而是,仅存储存储每个时间窗口聚合需要的结果。
如果存在迟到现象,Samza作业可以重发受到影响的窗口输出。
- 如果是一个标准的翻滚(非重叠)窗口,那么只有一个窗口的输出必须被重发。
- 如果是一个滑动(重叠)窗口,那么单个事件可能发给了多个窗口,因此所有受到影响的窗口输出必须被重发。
关于更多细节,可以通过这篇设计文档来了解。正如你想象的,大量的数据必须存储以便为受到迟到和乱序影响的窗口重新计算和重新发出结果。有些系统将所有这些数据存储在内存中,从而在事件滞留时间超过几分钟(取决于事件发生率)时导致不稳定。有些系统全部存储在远程数据库。这样效果很好而且扩展性好。然而,由于远程调用的CPU开销(系列化成本)和网络开销很高,这样的解决方案需要占用明显较大的硬件资源。让Samza在上述功能上体现独特之处的是使用嵌入式的、容错的、基于RocksDB的键值存储,以一等公民/生产就绪的方式支持“本地状态”。在Samza的状态管理的更多信息可以在这里找到。我还打算把重点放在细节以后的帖子“状态管理”。更多Samza的状态管理请参考这篇文章。我也会在未来的文章中着重探讨"状态管理"的细节。
2.再处理
让我们来看一个在LinkedIn需要对数据再处理的场景。LinkedIn允许我们任意设定当前职称。你可以说你是你们公司的“首席数据呆鸟”。我们需要提供有关工作的相关推荐、新闻等,以便知道你在你们公司真的是做这个的。为了解决这一问题,我们有一个基于Samza的事件处理器,通过我们现有的变更捕捉系统Databus,监听基于Espresso的档案数据库中的更改。对于会员对其档案所做的每次更新,都会通过(离线驱动的)机器学习模型,有根据地推测所填写的职称(和其他属性)可能是真的。这个机器学习模型会被定期(有时每周多次)更新。每当模型改变时,我们都需要重新处理LinkedIn所有现有会员的个人档案,以便使用最新模型来标准化全部档案。
很多人使用Hadoop或者Spark执行这种再处理。但这意味着,必须为批处理系统重新实现核心应用逻辑。如果流处理器要调用线上服务或者在线数据库,那么移植逻辑到批处理系统就没那么简单了。大多数的Hadoop网格都体量显著(几十万规模的机器)。如果它们去调用在线服务/数据库,很容易耗尽这些系统的指定配额,导致网站遭受影响。其结果是,近线和批处理系统之间的应用逻辑并不完全一样。
Databus提供了我们称之为“引导”的功能,客户可以直接从备份数据库读取和处理整个数据库,而不会影响生产数据库的服务延迟。使用Databus,每当应用再处理整个数据集的时候,我们只需启动基于Samza流处理器,以引导模式从Databus读取数据即可。
上述方法中有一点非常重要,引导或者再处理可能需要花上几个小时,特别在我们限制了系统的整体吞吐量的时候。在此期间,我们想继续并行运行在线流处理器,直到引导处理器被追上。这就产生了一个问题,结果数据集存储在哪里。是该分别存储数据,还是该合并在线处理器和引导处理器的结果到一个数据库里呢?这两种选择都是可行的,各有其优缺点。单独存储数据就需要服务层负责结果的合并(类似于Lambda架构)。在LinkedIn,我们也开发了新的存储,提供获取数据服务,该项目名为Venice,能够无缝处理在线和引导处理器输出的合并。如果没有类似的数据存储,可以使用Kafka 的一个通用的topic存储在线和引导处理器的输出结果。另一个Samza作业负责合并这些结果并将它们写入类似Espresso这样的数据库里。
在上述场景中,整个数据库的数据被再处理。还有其他的场景,只对几小时的数据进行再处理。例如,在应用升级的过程中,流处理器引入了一个错误。如果我们有良好的监控,那么在几分钟到几小时内,你会意识到发生了什么。假设处理是幂等的,你可以恢复应用,快退输入流(支持这个操作的消息系统包括Kafka、AWS Kinesis、Azure EventHub等),然后重新处理数据。
这种方法的注意事项有哪些?
当我们使用在线流处理器执行再处理时,必须在脑海里牢记几件事情:
1.当我们在流式处理的作业中快退并开始再处理,并且对用户请求直接更新数据库时,必须考虑对网站延迟潜在的影响。因此,治理流处理器的并发是非常重要的。Samza框架中采用的控制方式是作业的总体并行。
2.虽然在Samza等流式系统中执行再处理,技术上没有大小的限制,但是这可能需要上千台机器一起执行再处理,才能在一个合理的时间内完成,比方说,数据集有数百TB以上。在LinkedIn,这样的数据集的再处理只在我们的Hadoop网格中执行。集群的这种分离能够避免网络饱和度以及在线集群上其他的DOS触发。
3.易于编程和试验
创建一个“始终运行”的近线流式处理应用需要更高的门槛。多数情况下,实现逻辑非常复杂或者相对于SQL这样的高级语言,使用Java表达很繁琐。应用开发者和数据科学家喜欢使用像HIVE/PIG这样的高级语言在Hadoop中开发轻巧的应用来表达他们的逻辑。然而,大多数开源流式处理框架没有将SQL功能作为一等公民。一个很好例子是Azure Stream Analytics,其商用流处理器将SQL功能作为实时数据流上的一等公民。在流处理器缺乏SQL支持的情况下,在LinkedIn,许多近线作业,是在Hadoop/Spark上实现的,并且配置为较短的运行频率。其他一些应用在其近线流处理作业中最终只能实现基本/简单的逻辑,更复杂的处理要在他们的Hadoop/Spark离线作业中完成。然后,他们以经典的Lambda风格合并结果,并提供可用性消费。
这是一个众所周知的差距,是现在流式处理框架开发中活跃的领域。Julian Hyde描述了使用Apache Calcite让Samza支持SQL所做的努力。这个努力不是生产就绪的,所以我们在LinkedIn没有使用。在缺少对SQL支持的时候,开发者可以结合使用CEP(复杂事件处理)框架和流式处理系统,来提供流的更高层次抽象。来自Uber的Shuyi Chen提供了在最近[Stream Processing Meetup @ LinkedIn]上25的介绍,解释了他们是如何嵌入开源的CEP引擎(Siddhi)到基于Samza的流处理器中,使其更容易实现业务规则,而无需一头埋进Java/Python中。
除了支持高级语言,我们的Hadoop网格还为重复试验提供了一个很好的模型。在在线/近线系统中,执行相同的试验是一个大麻烦事儿,并且必须额外小心不能在访问事件源和数据库时,对在线系统产生负面影响。在LinkedIn,最相关的数据集被定期复制到Hadoop/Spark网格,并对离线批处理作业准备就绪。其结果是,许多用户宁愿在Hadoop上执行离线试验。幸运的是,像Samza这样的流处理器已经可以运行于YARN(未来可以运行于Mesos)。因此,很容易将试验运行于Hadoop网格上。我们目前正在为Samza开发一个HDFS系统的消费端,能将应用逻辑一次写入,可以在输入源HDFS、Kafka、Databus和其他数据源之间切换。我们希望在今年晚些时候的Samza版本中提供这样的功能。
原文地址:Stream Processing Hard Problems – Part 1: Killing Lambda
