@darkproject
2020-02-13T11:29:24.000000Z
字数 6532
阅读 1268
网易新人作业
作业
不使用Re,其余库用Python解析cpp文件中的宏定义,含#ifdef #ifndef #else #undef #endif 注释空格制作符换行,#define identifier token-stringopt, 其中 token-stringopt 只有兼容如下几种C/C++指定基本类型常量表示内容:整型,浮点,布尔(true, false),字符(忽略宽字符),字符串,及各上述基本类型组成的聚合。解析输出所有可用宏到字典,并存储到新的cpp文件。转换前后数据如下表:
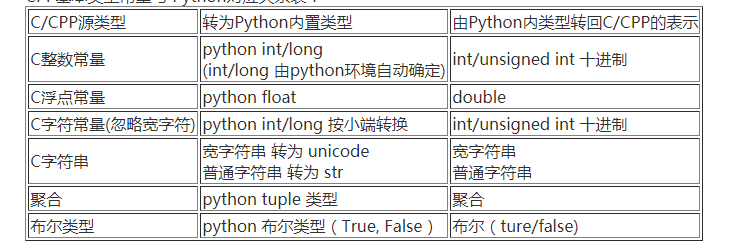
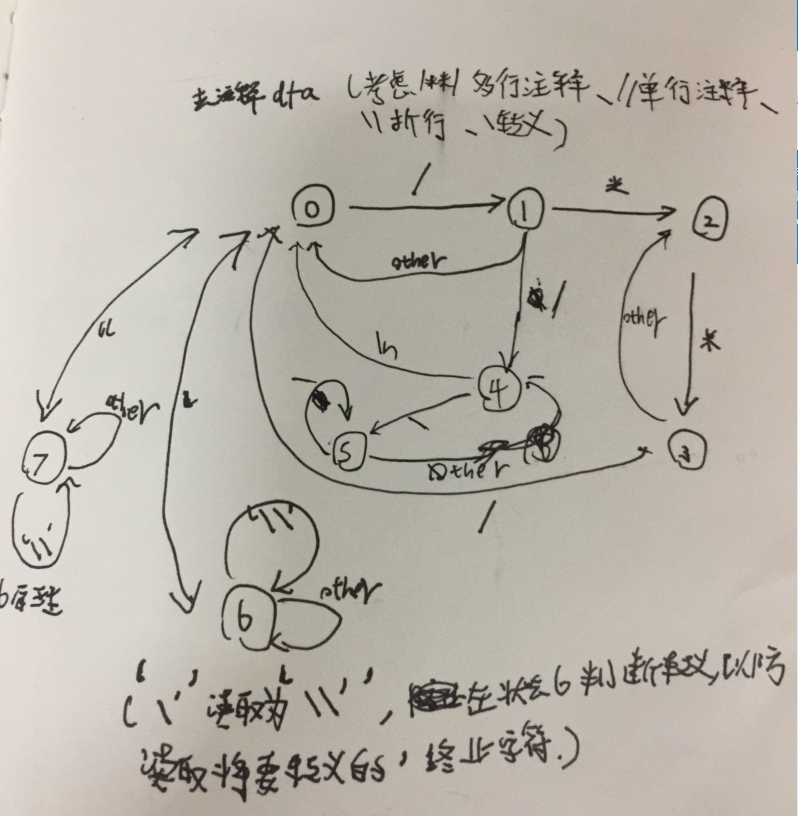
# -*- coding: UTF-8 -*-path = "D:/hw/a.cpp"save = "D:/hw/save.cpp"# 查表处理转义字符Escape = {'r': '\r', 't': '\t', 'v': '\v', "'": "\'", 'a': '\a', 'b': '\b', 'f': '\f','n': '\n', '"': '\"', '\\': '\\', '?': '\?', '0': '\0'}ReEscape = {'\a': '\\a', '\b': '\\b', '\f': '\\f', '\n': '\\n', '\r': '\\r', '\t': '\\t','\v': '\\v', "\'": "\\'", '\"': '\\"', '\\': '\\\\', '\?': '\\?'}def ParseAgg(value):# 状态机解析聚合类型# 栈匹配'{'与'}'# 返回值:元组temp = ''Res = []stack = []state = 0value = value[1:-1]for i in value:if state == 0 and i == ',':Res.append(temp.strip())print Restemp = ''elif state == 0 and i == '\"':state = 1temp += ielif state == 0 and i == '\'':state = 2temp += ielif state == 0 and i == '{':state = 3temp += istack.append(True)elif state == 0:temp += ielif state == 1 and i == '\"':state = 0temp += ielif state == 1:temp += ielif state == 2 and i == '\'':state = 0temp += ielif state == 2:temp += ielif state == 3 and i == '}':temp += istack.pop()if stack == []:state = 0elif state == 3 and i == '{':temp += istack.append(True)elif state == 3:temp += iif len(temp) > 0:Res.append(temp.strip())tempRes = tuple(Res)Res = []for i in tempRes:Res.append(ParseValue(i)) # 递归解析聚合类型嵌套情况return tuple(Res)def ParseString(value):lstr = FalseRes = ''state = 0if value[0] == 'L':lstr = Truevalue = value[1:]for i in value:if state == 0 and i == '\"':state = 1elif state == 1 and i == '\"':state = 0elif state == 1 and i == '\\': # 处理字符串中转义可能出现'"'误判为终止态state = 2elif state == 1:Res += ielif state == 2 and i in Escape:Res += Escape[i]state = 1elif state == 1:Res += iif lstr is True:return unicode(Res)else:return Resdef RePareseString(value):Res = ''for i in value:if i in ReEscape:Res += ReEscape[i]else:Res += ireturn Resdef ParseChar(value):value = value[1:-1]length = len(value)if length == 1:return ord(value)elif value[0] == '\\' and length > 2:if value[1] == 'x' or value[1] == 'X':value = '0' + value[1:]return int(value, 16)else:return int(value[1:], 8)elif value[0] == '\\':return ord(Escape[value[1]])def ParseValue(value):# 将cpp源类型解析为python内置类型sign = 1if value is None:return None# 字符串if value[0] == '\"' or value[0] == 'L':return ParseString(value)# 聚合类型if value[0] == '{':return ParseAgg(value)# bool类型if value == 'true':return Trueif value == 'false':return False# 前缀符号if value[0] == '-':sign = -1value = value[1:]elif value[0] == '+':value = value[1:]# 十六进制数if value[0:2] == '0x' or value[0:2] == '0X':value = value.replace('i64', '')value = value.replace('I64', '')value = value.rstrip("uUlL")return sign * int(value, 16)# 八进制数elif value[0] == '0' and len(value) > 1 and '.' not in value:return sign * int(value, 8)# 浮点数elif 'e' in value or 'E' in value or '.' in value: #if 'f' in value or 'F' in value or 'l' in value or 'L' in value:value = value.rstrip('fFlL')return sign * float(value)else:return sign * float(value)if value[0] == '\'':# 字符类型return ParseChar(value)else:# 十进制整数value = value.replace('i64', '')value = value.replace('I64', '')value = value.rstrip("uUlL")return sign * int(value)def ReParseValue(value):if isinstance(value, unicode):return 'L' + '"' + RePareseString(str(value)) + '"'if isinstance(value, str):return '"' + RePareseString(value) + '"'if isinstance(value, bool):if value is True:return "true"else:return "false"if isinstance(value, tuple):res = ''for i in value:res += ReParseValue(i) + ','res = '{' + res[:-1] + '}'return resreturn str(value)def RemoveComment(str):# 有限状态机去除读取的字符串中的注释部分# 注释可能存在的情况/**/多行注释、//单行注释、\\折行# 返回值:字符串state=0Res=''for i in str:if state==0 and i=='/':# 我们利用空格进行分词,出现#define/**/name注释紧贴情况,添加空格便于分词Res+=' 'state=1elif state==0 and i=='\`':state=6elif state==0 and i=='\"':state=7elif state==0:Res+=ielif state==1 and i=='*':state=2elif state==1 and i=='/':state=4elif state==1:state=0Res+='/'+ielif state==2 and i=='*':state=3elif state==3 and i=='/':state=0elif state==3 and i=='*':state=3elif state==3:state=2elif state==4 and i=='\n':state=0Res+=ielif state==4 and i=='\\':state=5elif state==5 and i=='\\':state=5elif state==5:state=4elif state==6 and i=='\\':state=6elif state==6 and i=='\`':state=0Res+=ielif state==7 and i=='\\':state=7elif state==7 and i=='\"':state=0Res+=iif state == 6 or state == 7:Res+=ireturn Resdef RemoveTab(code):# 处理不在“”和''内的制表符Res = []temp = ''state = 0for str in code:for i in str:if state == 0 and i == '\t':temp += ' 'elif state == 0 and i == '\"':temp += istate = 1elif state == 0 and i == '\'':temp += istate = 2elif state == 1 and i == '\"':temp += istate = 0elif state == 2 and i == '\'':temp += istate = 0else:temp += iRes.append(temp)temp = ''return Resdef To_List(str):# 将处理掉注释的字符串按行分割,并清理多余符号# 返回值:列表 ex:[#define a 1]code = []ans = []start_index = 0end_index = 0while end_index < len(str):if str[end_index] == '\n':code.append(str[start_index:end_index])start_index = end_index + 1end_index += 1if str[start_index:] != '':code.append(str[start_index:])print codecode = RemoveTab(code)for t in code:temp = t.strip().split(' ', 1)ins = temp[0].strip()if ins == '#': # 处理'#'未紧贴宏指令的情况temp = temp[1].strip().split(' ', 1)ins += ''.join(temp[0])if len(temp) > 1:temp2 = temp[1].strip().split(' ', 1)if len(temp2) > 1:temp2[1] = temp2[1].strip()ans.append(ins + ' ' + temp2[0] + ' ' + temp2[1].strip())else:ans.append(ins + ' ' + temp2[0])else:if ins != '':ans.append(ins)print ansreturn ansdef ParseMacro(code, dict):# 进行分词,将宏的定义语法分为指令 宏名 值 三部分# 2个栈匹配宏定义分支逻辑,一个栈匹配#ifdef #ifndef #else,# 另一个栈记录分支的状态(防止前一个分支不满足时,内部遇到一个分支不满足,此时内部分支else时flag将会为true会执行内部#define)index = 0stack = []state = [True]flag = Truewhile index < len(code):temp = code[index].split(' ', 2)length = len(temp)macro_ins = temp[0]if macro_ins == '#define' and flag:if length > 2:dict[temp[1]] = ParseValue(temp[2])else:dict[temp[1]] = Noneelif macro_ins == '#ifdef':if temp[1] in dict:state.append(True and state[-1])stack.append(True)else:state.append(False)stack.append(False)flag = Falseelif macro_ins == '#ifndef':if temp[1] not in dict:state.append(True and state[-1])stack.append(True)else:state.append(False)stack.append(False)flag = Falseelif macro_ins == '#else':if not stack[-1] and state[-2]:state[-1] = Trueflag = Trueelse:state[-1] = Falseflag = Falseelif macro_ins == '#undef' and flag:if temp[1] in dict:del dict[temp[1]]elif macro_ins == '#endif':stack.pop()state.pop()flag = state[-1]index += 1class PyMacroParser:def __init__(self):self.dict = {}self.code = []self.pDefine = []def load(self, f):try:with open(f, 'r') as p:str = RemoveComment(p.read())self.code = To_List(str)except IOError:print "Not Find File!"def preDefine(self, s):self.dict = {}self.pDefine = []temp = s.split(";")for i in temp:if (i != ''):self.pDefine.append(i.strip())def dumpDict(self):self.dict = {}for i in self.pDefine:self.dict[i] = NoneParseMacro(self.code, self.dict)print self.dictreturn self.dictdef dump(self, f):self.dict = {}for i in self.pDefine:self.dict[i] = NoneParseMacro(self.code, self.dict)try:with open(f, 'w') as p:for key in self.dict:if self.dict[key] is None:p.write('#define ' + key + '\n')else:p.write('#define ' + key + ' ')p.write(ReParseValue(self.dict[key]))p.write('\n')except IOError:print "Not Write File!"if __name__ == '__main__':t = PyMacroParser()t.load(path)t.preDefine("")t.dumpDict()t.dump(save)
