@Wishes
2018-10-30T07:45:43.000000Z
字数 6144
阅读 684
Python 常用包及其示例
- requests
# -*- coding: utf-8 -*-import sysimport requestsimport jsonfrom base64 import b64encodedef post(sess, url, headers=None, data=None):return sess.post(url, headers = headers, data=data)def main(cookie):session = requests.Session()img = open('id_search_200.png', 'rb').read()imgStr = '<img src="data:image/png;base64,' + b64encode(img) + '">'url = 'http://omds.sit.sf-express.com/dataplatform/rest/billing/feedback/upload'headers = {'content-type': 'application/json', 'Cookie': cookie}data = json.dumps(({'content': imgStr, 'type': 'data_issue'}))res = post(session, url, headers, data)print res.text.encode('utf-8')if __name__ == '__main__':cookie = Noneif len(sys.argv) > 1:cookie = sys.argv[1]main(cookie)
sys.argv 用来存的是输入的命令行参数,示例中运行的时候,可以执行如 python test.py JSESSIONID=13ii2srw9twfwdy915nkaeg2e 就可以将cookie传入main函数中。
- time
>>> import time>>> now = time.time()>>> now1540791442.952>>> ts = time.localtime(now)>>> tstime.struct_time(tm_year=2018, tm_mon=10, tm_mday=29, tm_hour=13, tm_min=37, tm_sec=22, tm_wday=0, tm_yday=302, tm_isdst=0)>>> lst = list(ts)>>> lst[0] = 2019>>> time.mktime(lst)1572327442.0>>> time.strftime('%Y-%m-%d %H:%M:%S', lst)'2019-10-29 13:37:22'>>> time.strptime('2018-08-15 10:27:36','%Y-%m-%d %H:%M:%S')time.struct_time(tm_year=2018, tm_mon=8, tm_mday=15, tm_hour=10, tm_min=27, tm_sec=36, tm_wday=2, tm_yday=227, tm_isdst=-1)
- flask
from flask import Flask, requestimport logging, syslogging.basicConfig(stream=sys.stdout, level=logging.DEBUG)app = Flask(__name__)@app.route('/test', methods=['GET', 'POST'])def hello_world():if request.method == 'POST':print request.args.get('next')print request.get_json()print request.get_data()print dir(request)return 'Hello Flask!'if __name__ == '__main__':app.run(host='0.0.0.0', port=9090, threaded=True, debug=True)
flask 默认单线程运行,在某些情况下会有问题,比如写了死循环的时候,设置threaded=True是多线程模式。
- excl
import xlwtimport xlrddef write():wbk = xlwt.Workbook()sheet = wbk.add_sheet('sheet 1')sheet.write(0, 1, 'content')wbk.save('test.xls')def read():workbook = xlrd.open_workbook('test.xls')sheet_names= workbook.sheet_names()for sheet_name in sheet_names:print (sheet_name)sheet2 = workbook.sheet_by_name(sheet_name)rows = sheet2.row_values(0)print (rows[1])cols = sheet2.col_values(1)print (cols[0])
- 文件IO
with open('test.txt') as f:for line in f:print linecontent = open('test.txt').read()
- 排序
>>> lst = [2,3,1,4]>>> sorted(lst, lambda x1, x2: x1-x2)[1, 2, 3, 4]>>> sorted(lst, lambda x1, x2: x2-x1)[4, 3, 2, 1]
- mysql
import pymysqldef get_conn(host, port, user, password, db):conn = pymysql.connect(host = host, user = user,password = password, db= db, port = port, charset='utf8')conn.autocommit(False)return conndef execute(sql, conn):cur = conn.cursor()try:cur.execute(sql)conn.commit()return cur.fetchall()except BaseException as e:conn.rollback()return None
- 高阶函数(接受函数作为参数或者将函数当成返回值), 装饰器
def transaction(execute):def commit(sql, conn):try:res = execute(sql, conn)conn.commit()except BaseException as e:conn.rollback()return resreturn commit@transactiondef execute(sql, conn):cur = conn.cursor()cur.execute(sql)conn.commit()return cur.fetchall()
- 闭包(内层函数引用了外层函数的变量,然后返回内层函数,闭包的特点是返回的函数还引用了外层函数的局部变量)
import requestsdef retry(num):def wrapper(func):def request():for i in range(num):print ifunc()return requestreturn wrapper@retry(10)def post():return requests.get('http://www.baidu.com')
Elasticsearch 基础
全文检索
对结构化与非结构化数据的检索。
分词
分词示例:
>>> seg_list = jieba.cut(u'人民日报是中国共产党中央委员会机关报。')>>> print ' / '.join(seg_list).encode('gbk')人民日报 / 是 / 中国共产党中央委员会 / 机关报 / 。
以上述为例,使用的是正向最大匹配算法分词,还有其他分词如HMM(隐马尔可夫模型),正向最小分词等。如下为正向最大分词伪代码:
public static List forwardSeg(String text){List result=new ArrayList();while(text.length()>0){int len = MAX_LENGTH;if(text.length() < MAX_LENGTH){len=text.length();}//取指定的最大长度 文本去字典中匹配String tryWord=text.substring(0, len);while(!dictory.contains(tryWord)){ //如果词典中不包含该段文本//如果长度为1 的话,且没有在字典中匹配,返回if(tryWord.length()==1){break;}//如果长度大于1且匹配不到,则长度减1,继续匹配tryWord=tryWord.substring(0, tryWord.length()-1);}// 得到分词结果tryWordresult.add(tryWord);//移除字符串最左侧被分出的词tryWord,继续循环text=text.substring(tryWord.length());}return result;}
倒排索引
倒排列表用来某一个词出现在有哪些文档中。示例图如下:
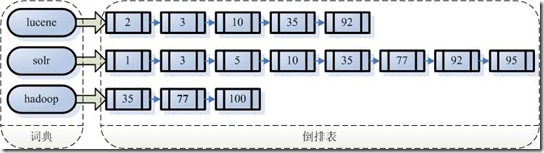
如果搜索 lucene hadoop,则只需要合并第一个和第三个链表。合并方式有顺序合并和跳表合并。
词袋模型与排序
词袋模型是指对于文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,文本中每个词的出现都是独立的,不依赖于其他词是否出现。
对于检索的关键词进行分词,得到的所有词进行量化,得到一个向量,例如搜索lucene hadoop,可表示为的向量;对于需要检索的文本集合,则需要对所有的文本进行分词,建立倒排索引,对于某一个文档,计算每一个词的权重,得到向量,那么查询与文本的向量余弦相似度公式如下:
=
最后根据相似度进行排序。
Elasticsearch 用法
Elasticsearch 集群
集群结构
es 集群包含master eligible node(主候选节点),其中的一个主节点负责轻量级集群范围的操作,例如创建或删除索引、记录集群的节点状态,以及决定将索引的分片非配到哪些节点;data node(数据节点),存储索引的数据;coordinating node(协调节点),负责请求的分发(scatter)与请求结果的收集(gather)。主节点选举与脑裂(split brain)
es只有discovery.zen.ping.unicast.hosts参数中的节点才能选举成为主节点,并且discovery.zen.minimum_master_nodes是形成集群的最少候选主节点的数量,一般minimum_master_nodes需要设置成(master_eligible_nodes / 2) + 1才能避免出现脑裂问题。分片与副本(主备模型)
为保证高高效性与高可用性,es支持将索引切片,称为主分片,存储在不同机器上,每个索引分片又设置备份分片,称为副分片。主分片数量设置好之后,在索引使用的过程中不可 改变,而副分片数量可以修改。主分片与副分片都能处理查询请求。分布式副本一致性与请求路由
当一个请求到达协调节点,协调节点根据请求内容的ID进行hash之后取模分片数量,得到该请求对应的分片,然后将转发到分片对应的节点上。也可以自定义字段进行hash。
如果是更新请求,那么请求将只会发送到主分片上,主分片更新成功之后再并发转发到其他副本分片上,等待所有副分片响应,不论成功失败,最后再返回给请求前端。如下图所示:
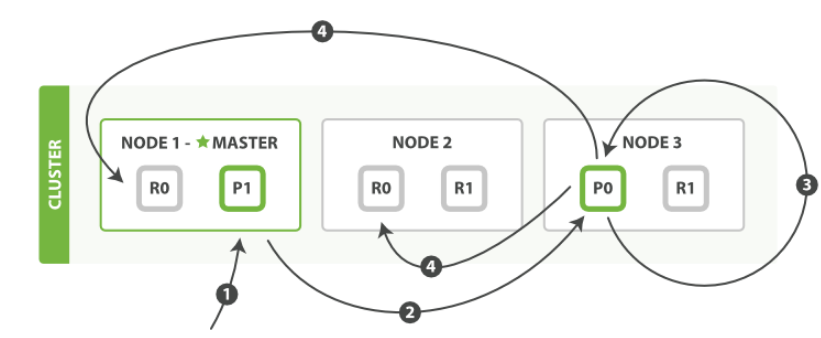
es会维护所有索引的in-sync表,存放索引中更新至最新的分片列表,如果副本分片在更新时失败,则会被移出in-sync表。es的查询只会被分发到in-sync表中的分片中。数据节点对更新请求的处理逻辑
es底层使用Lucene作为存储引擎,数据分片节点收到更新请求后,先写入Lucene,然后写入TransLog,如下图所示:
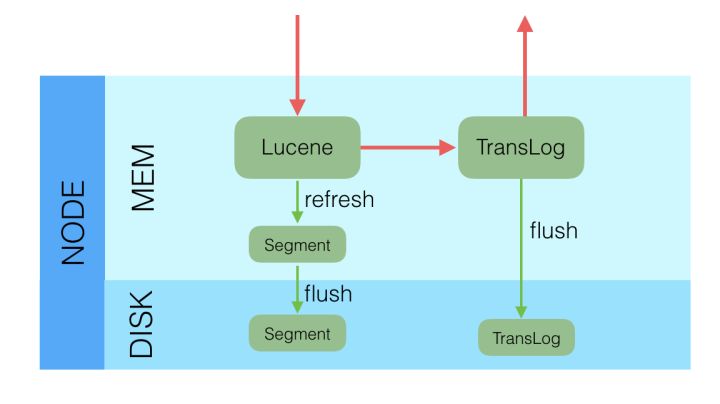
es的flush操作会调用Lucene的commit,创建提交点,并清理TransLog。NER(Near Realtime)近实时搜索的原因
写入Lucene中的数据,其实是保存在内存中,需要es每隔1秒钟就refresh一次,触发Lucene的flush操作,将内存中的数据写入磁盘,然后读入新增数据的meta,才能被检索。由于Lucene的flush有磁盘操作,而又不能直接检索内存中更新的数据,所以只能做到近实时,并且用户手动refresh的频率不应太高。
Elasticsearch 事务
- 持久性:Lucene提供
commit接口,保证了数据一旦提交,会将内存中的数据flush到磁盘,并保证所有文件sync,同时生成检查点保存到文件中。 - 一致性:非物理损坏都不会导致Lucene的索引丢失,Lucene启动的时候,会对数据进行一致性检查。
- 原子性:所有Lucene中的更新操作,都会保存在内存中,一旦在
commit的时候发生错误,即可使用rollback函数回滚到最新的提交点,不存在中间状态。 - 隔离性:Lucene不能开启多个独立的事务,
rollback回滚或者其他方式回滚将导致所有的数据都回滚到某个提交点。如果是单线程写入,数据在提交之前都是不可读的。
总体而言,es对事务的支持非常差,主要是隔离性支持太差。
- 持久性:Lucene提供
Elasticsearch 存储的数据与索引
- 存储的数据
对于需要存储的每一行数据,es首先会对需要建立索引的列进行索引,然后将整行数据转化成JSON存到_source列中,并且默认会给每个文档生个一个_id,_version,_index,_type列。 ES索引:倒排索引,列式存储,KD-Tree
对于每一列数据,需要进行正确的索引操作,es的mapping中描述了每一列的类型。
如果是text列,则建立倒排索引,将该列分词,得到词项(Term)-文档ID的索引信息,同时记录下该词在这一列中出现的位置,所以得到的最终索引是Term-[(docId, position), (), ...];
如果该列是key-word列,es默认会将该列建立(string,docId)的列式索引,如下图所示:
行数据:docId 姓名 1 张三 2 李四 3 赵武 列式存储数据:
李四 2 张三 1 赵武 3 如果该列是数字类型,那么会存到kd树中。一维向量的kd树,假设节点值是 [1,3,4,6,7,8,10,13,14],建树后如下:

- ES查询
任何查询都是与索引相关的,倒排索引支持全文检索;列式存储支持字符串查询,排序,和聚合查询;kd树支持多维向量的范围查询。
- 存储的数据
