@PandoraKey
2024-04-21T16:38:45.000000Z
字数 43344
阅读 303




1.可行性分析
当开始明确要开发一个系统或者一个具备相当规模的软件时,应该先进行可行性分析研究。可行性分析研究的目的,就是用最小的代价在尽可能短的时间内确定问题是否能够解决。因此我们针对本次毕业设计所要开发的系统——计算机辅助考试软件系统进行可行性研究,其研究内容包括系统规模、系统目标、相关系统研究、系统逻辑模型、系统开发的若干解决方案、系统开发计划。
1.1 系统规模及目标
本节主要研究我们的毕业设计项目——计算机辅助考试软件的系统规模及其系统目标。
- 系统目标
本系统旨在构建一个连接学生、教师、管理人员三方的智慧考试系统。
对于学生的设计目标是能够让学生在规定的时间内完成教师指派的考试内容,并且通过判分程序完成对学生所作答内容的智慧判分,接着以数据可视化的方式反馈考试情况给学生个人,并上报给任课教师。
对于教师的设计目标是能够让教师以个性化方式对所带班级进行教学,并且能够以多种方式生成课业考查试卷以供学生进行测试,学生考查判分完毕后将会提供给教师反馈可视化信息,以便后续调查研究。
对于管理人员的设计目标是,能够以多种方式从互联网或者本地相关数据库中导入海量试题信息到试题仓库数据库内以供教师的多样化试卷生成以及师生信息的导入。
- 系统规模
为了较合理地估算开发本系统所需代码规模,我们采用 IFPUG 功能点估算方法[1]对系统代码规模进行研究。这里简单地阐述一下 IFPUG 功能点估计法是什么。 IFPUG 功能点估算法是依据功能点的数量来估算系统开发规模。而且功能点分析方法只从用户这一方来量化软件开发,不会去考虑相关的物理系统实现。
| 序号 | 功能点类型 | 基本过程 | 复杂度 |
|---|---|---|---|
| 1 | 外部接口文件 | 管理员基本信息 | 中 |
| 2 | 外部接口文件 | 教师基本信息 | 中 |
| 3 | 外部接口文件 | 学生基本信息 | 中 |
| 4 | 外部接口文件 | 爬虫导入试题数据 | 高 |
| 5 | 外部接口文件 | 本地导入试题数据 | 低 |
| 6 | 内部逻辑文件 | 筛选阀过滤数据 | 低 |
| 7 | 内部逻辑文件 | 考卷信息数据 | 低 |
| 8 | 内部逻辑文件 | 判分结果数据 | 高 |
| 9 | 内部逻辑文件 | 判分结果可视化 | 高 |
| 10 | 内部逻辑文件 | 分发试卷情况 | 低 |
| 11 | 外部输入 | 配置控制信息 | 低 |
| 12 | 外部输入 | 考试作答 | 高 |
| 13 | 外部输入 | 用户登录(传统) | 低 |
| 14 | 外部输入 | 数据库内容编辑 | 中 |
| 15 | 外部输入 | 用户信息编辑 | 低 |
| 16 | 外部输入 | 用户登录(非传统) | 高 |
| 17 | 外部输入 | 卷面设置 | 低 |
| 18 | 外部输出 | 可视化反馈 | 高 |
| 19 | 外部输出 | 待答题卷面 | 中 |
| 20 | 外部输出 | 导出班级情况 | 中 |
| 21 | 外部查询 | 查询试卷 | 低 |
| 22 | 外部查询 | 查询用户信息 | 低 |
| 23 | 外部查询 | 查询得分情况 | 低 |
最后可以统计出项目功能点的相关分布情况,其中高级别权重为10,中级别为7,低级别为5:
- 外部接口文件:
- 高级别:1(个)
- 中级别:3(个)
- 低级别:1(个)
- 内部逻辑文件:
- 高级别:2(个)
- 低级别:3(个)
- 外部输入:
- 高级别:2(个)
- 中级别:1(个)
- 低级别:4(个)
- 外部输出:
- 高级别:1(个)
- 中级别:2(个)
- 外部查询:
- 低级别:3(个)
因此通过功能点计算公式:
通过参考目前各种编程语言对于每个功能点的所需代码行情况,便可以大致估算出项目系统规模。
1.2 相关系统的研究
经过两周的查阅文献后,我们对现有的两个相关系统做出详细研究,这里做出简要讲述。
- 基于遗传算法的智能组卷在线考试系统[2]
该系统由中国科学院大学硕士生曹烨设计并实现,采用基于生物基因多样性变化的遗传算法作为考试系统的组卷算法策略,并且进一步作出改进,使之能达到用户所需的智能、高效与便捷。该系统较为精巧,主要功能是试卷管理中的智能组卷,而其他功能则是作为一种辅助手段或者是基本手段以完善系统主题,例如登录管理、系统管理、人员管理、考试管理、题库管理这五大基本模块,该系统有个较为突出的优点在于利用智能组卷和人工组卷相结合的组卷策略,以满足多个用户不同的组卷需要。但是存在不足的地方就是这个系统的阅卷模式仍然是一种人工阅卷,不够智能,更谈不上为用户减少工作量。
- 学校通用考试系统的设计与实现[3]
该系统由电子科技大学硕士生郭素蓉设计并实现,采用 B/S 的设计方式,在浏览器上进行系统运行,通过随机法、回溯法、遗传算法作为自动组卷的组合策略,但是在设计方面上,依旧是无法解决解放教师工作量的问题,教师工作量过高,但是由于目前的系统设计方向上并没有引入自然语言处理模块,于是便无法把主观题的人工阅卷变更为更优秀的自动化阅卷,因此仍然是需要对这类通用考试系统做出改进,即引入自然语言处理模块。
1.3 系统逻辑模型
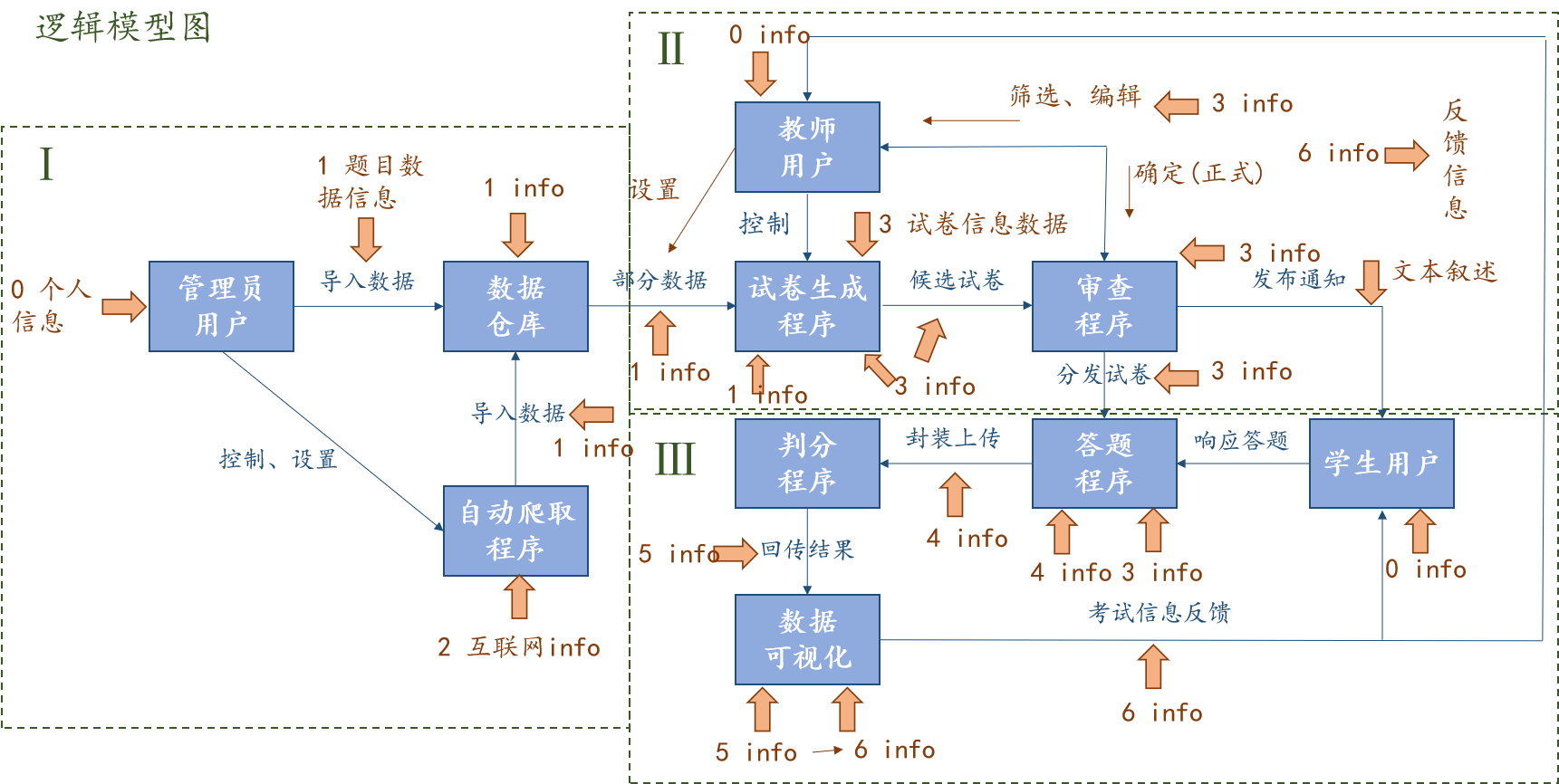
上节介绍了相关系统的进展,接下来要介绍本系统的逻辑设计模型,主要分为两个部分,一个是高层逻辑模型设计,包含整个系统的完整模型,但是不对其中的程序做出更加详细的功能分解,仅仅保留基础框架。
1.3.1 高层逻辑模型设计
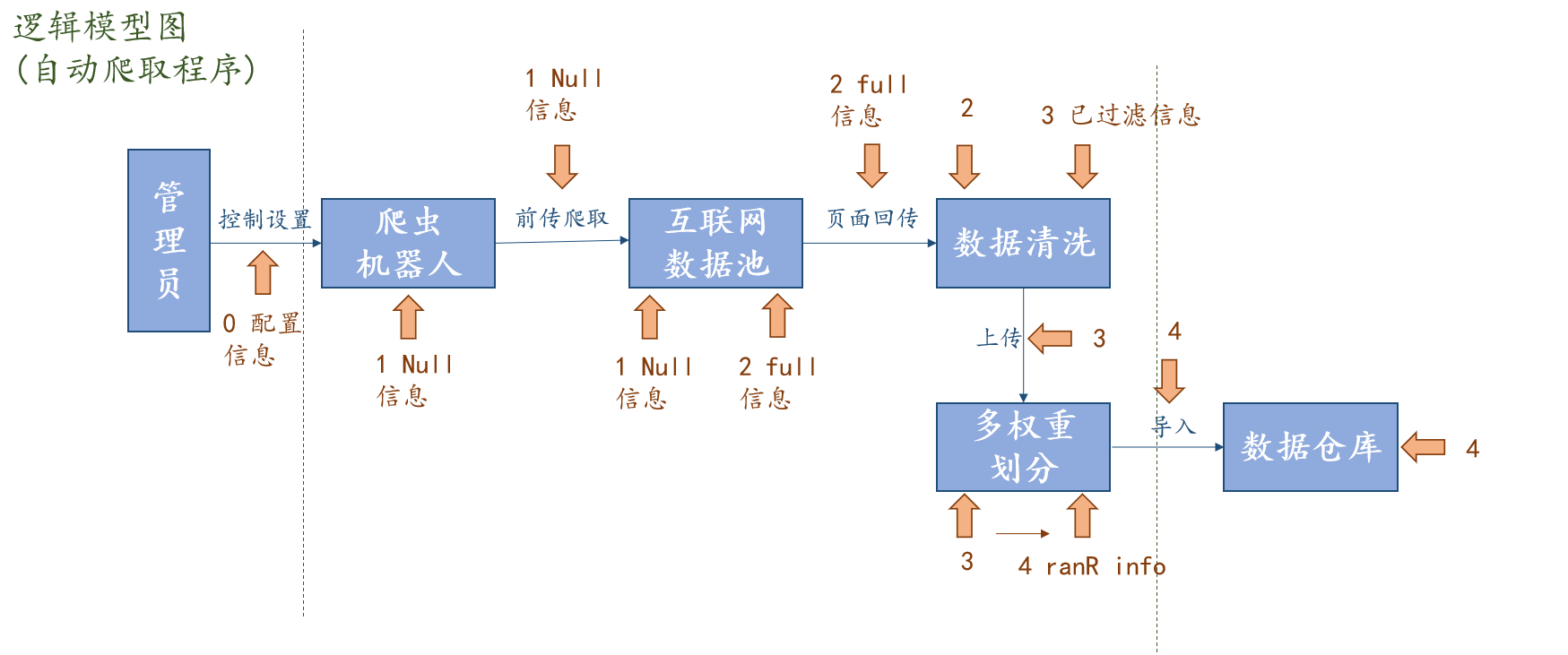
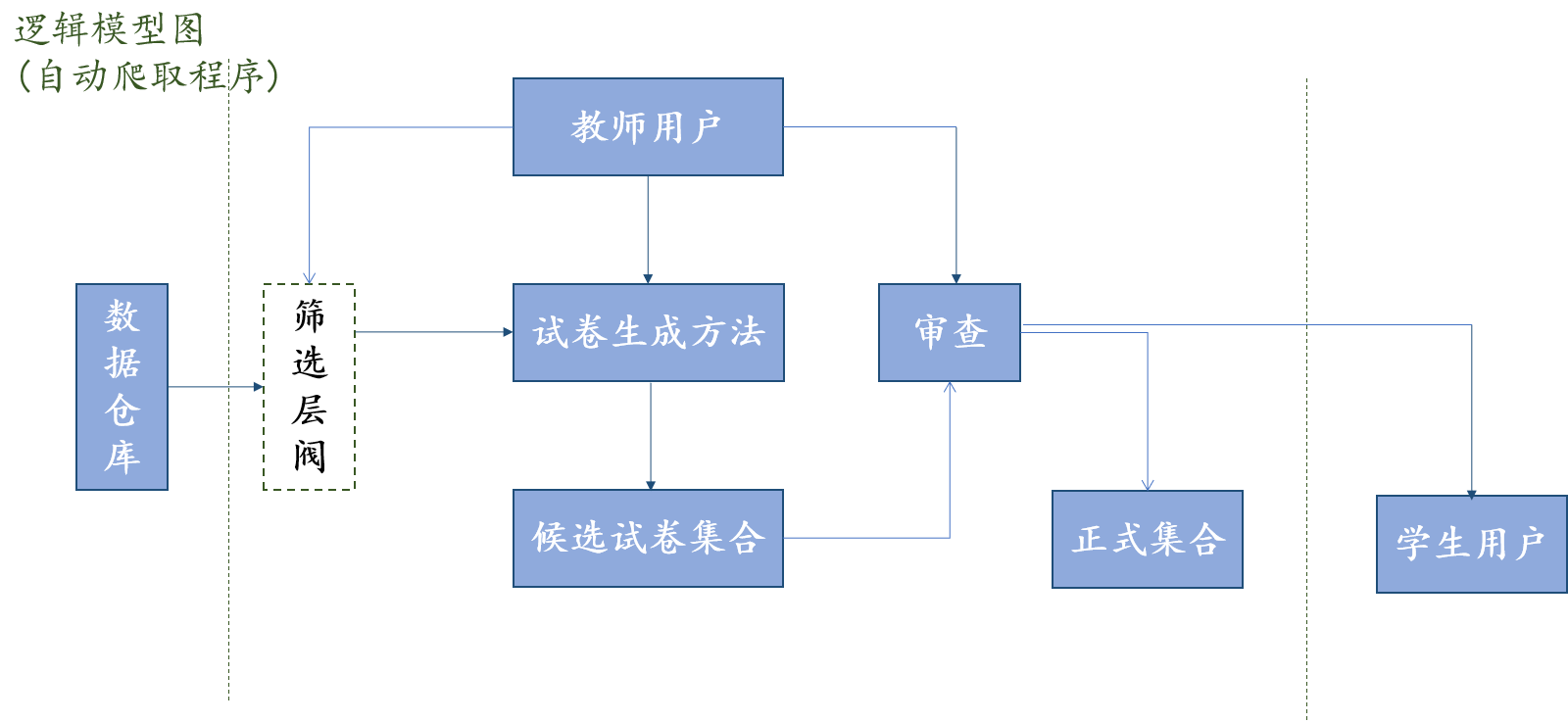
1.3.2 分层逻辑模型详细设计
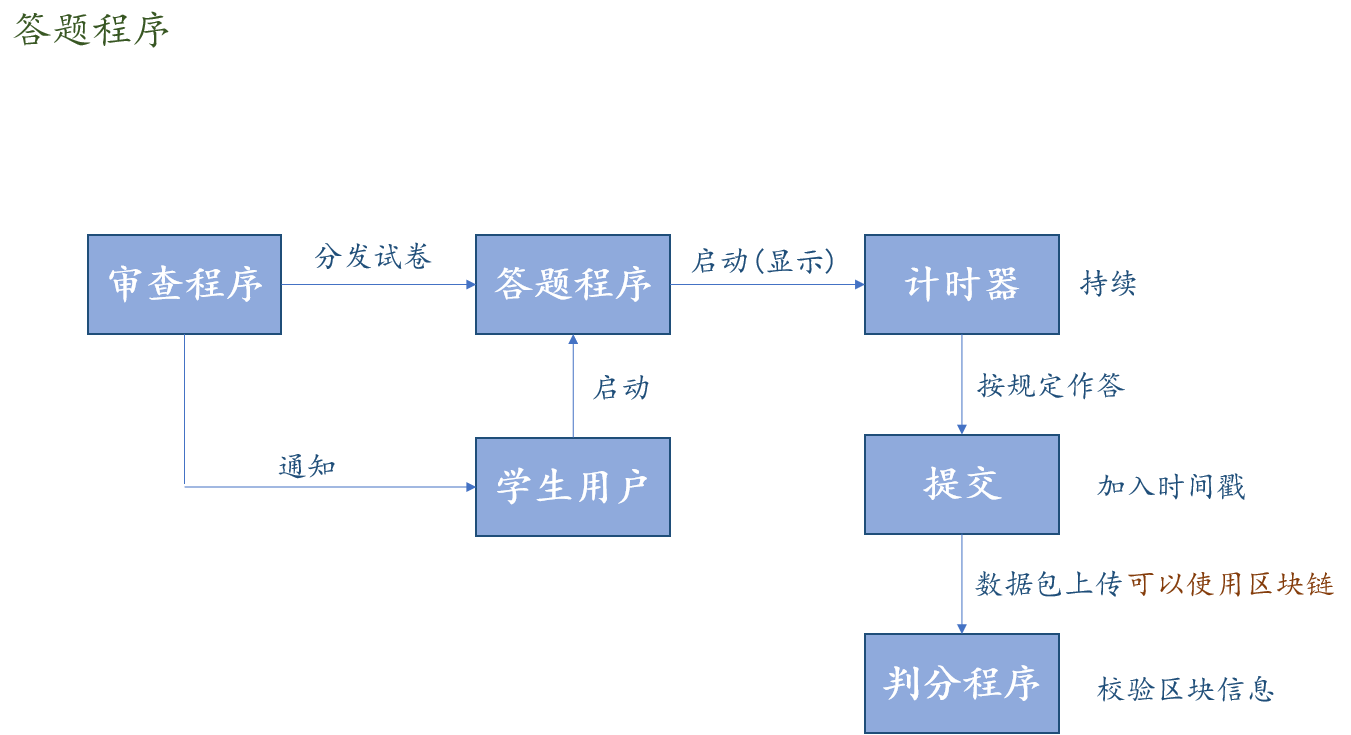
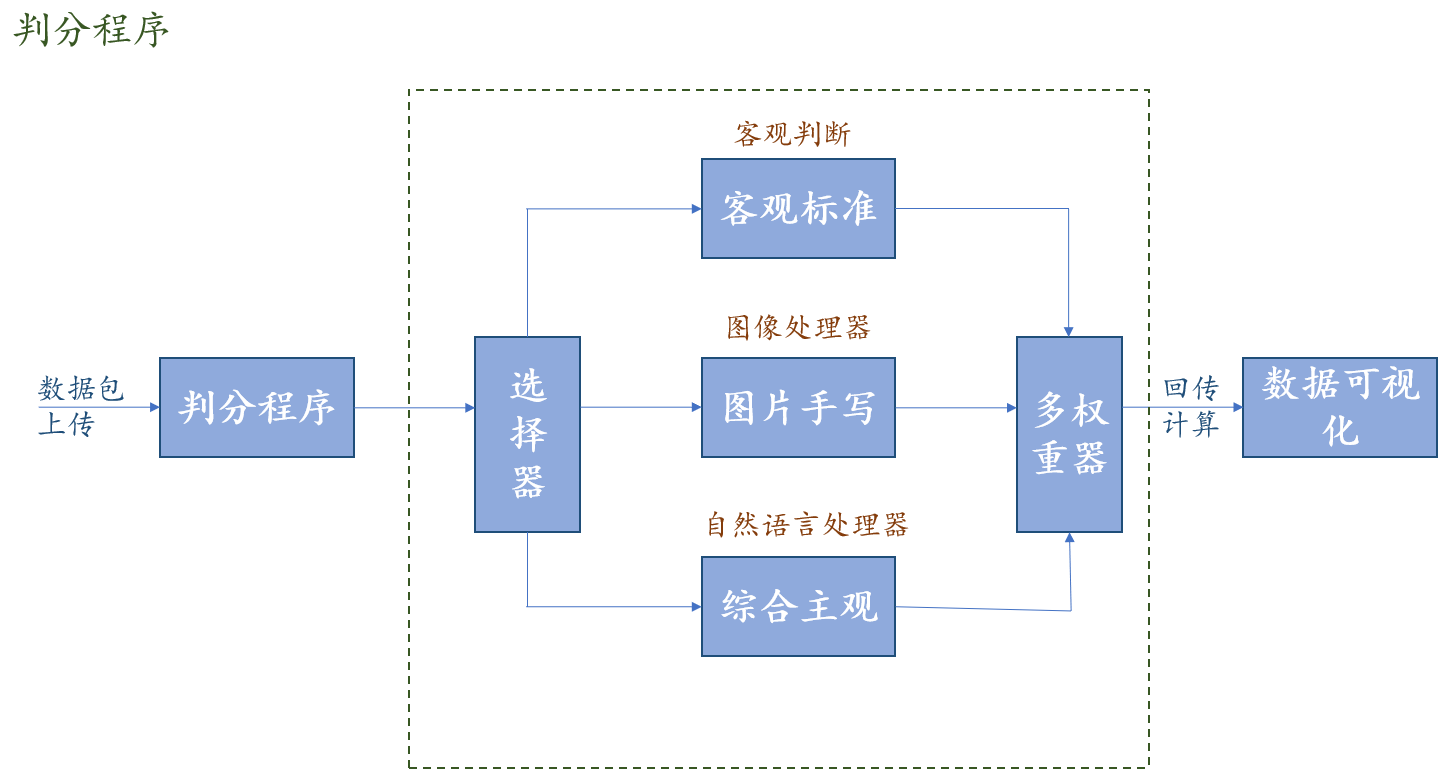
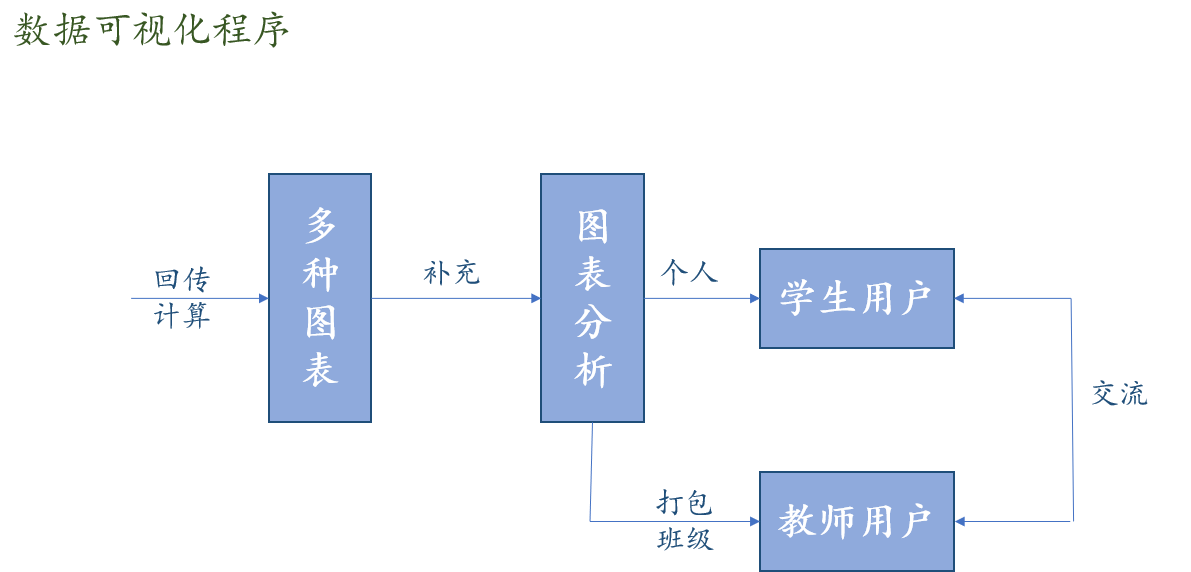
1.4 系统开发相关方案
开发本系统有两种策略:一是按照在线教育的模式,进行 B/S 开发,以网站的开发策略制作在线的智能考试系统,随考随反馈;二是采用 C/S 开发模式,以客户端为本地载体,当用户答卷完成之后,把数据包整体上传到服务器进行处理,然后服务器再回传答题情况给当前用户以及任课教师。但是考虑到并不是所有教室都是机房,且以PC客户端为数据采集端的 C/S 开发方案并不符合随时随地开展考查,因此本系统开发采用基于 Web 的 B/S 开发模式。
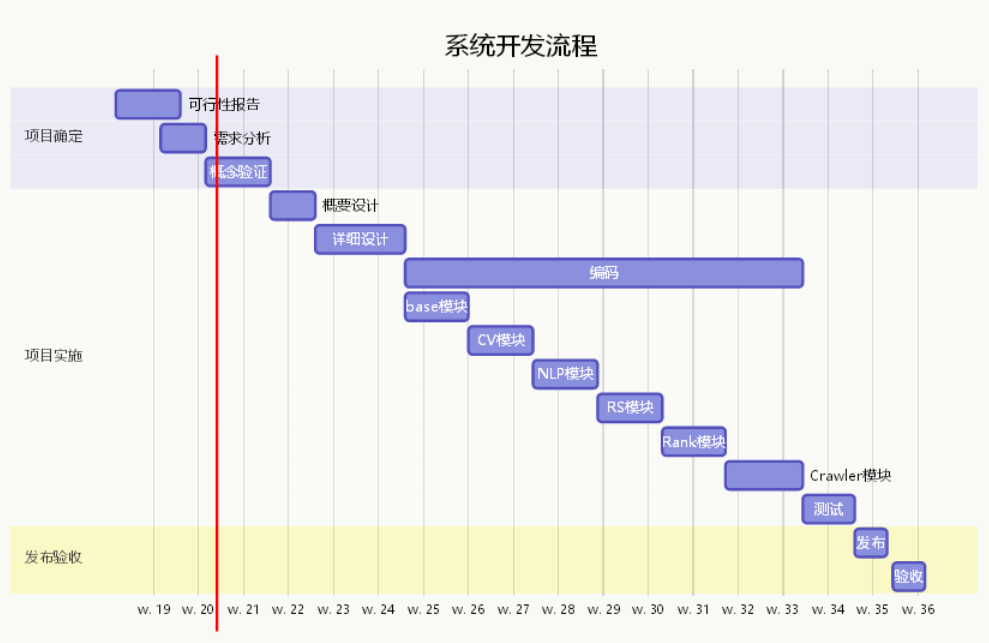
1.5 系统开发计划
本系统预计开发规模为五万行,开发时长预计为8周,预计每天开发九百行,本系统才用多模块的组合开发,共有六个模块:base module、CV module、NLP module、RS module、Crawler module、Rank module。其中 bese module 是整个系统的基础部分,包括登录、注册等基本功能;CV module 即计算机视觉模块,主要处理用户考试时所引入的手写图片以及人脸识别登录;NLP module 是自然语言处理模块,主要处理用户考试时所引入的主观题解答部分;RS module 是整个软件的推荐核心,将会采用传统的协同过滤方法配合 PRM 策略做重排序,主要处理教师用户的智能组卷,受到相关系统的启发,可能会引入智能进化算法配合组卷;Crawler module 是爬虫模块,由于基本题库中的练习题种类较少、形式较为寡淡,无法全面地帮助教师为学生进行查缺补漏,因此使用爬虫模块的目的在于从互联网中搜索、爬取、筛选合适的试题进入题库中,等待使用;Rank module 是排序模块,其中包括基本排序与重排序,基本排序将会用在试题仓库中进行多权重校正,重排序则是利用 FM 做 RS module 的 re-ranking。基本介绍系统的各模块职能之后,对各个模块制定开发计划:
大图如下:
2. 需求分析
计算机辅助考试系统最开始的业务流程是试题导入,只有管理员导入试题,授课教师才能够生成试卷提供给学生进行学业考查,于是就产生了题库信息。当题库中的试题数量到达一定程度时,教师才能够通过随机生成、自主选题、推荐生成这三种方式进行出卷操作,然后提供给学生标准化试卷以考查当前学习情况。因此计算机辅助考试系统的主要业务集中在导入试题、生成试卷、回答试卷、考情反馈四个方面,从这三方面又衍生出题库管理、试卷生产的过程、智能阅卷、考情可视化分析等过程。本章节主要进行计算机辅助考试系统的需求分析,分别从功能性和非功能性两大方面进行分析。具体描述了全部功能的用例模型和业务流程,详细分析了具体功能的执行流程,明确本系统具体提供给用户哪些便利。通过功能性需求分析,把系统一步步地分解成具体的业务功能模块,熟悉系统所需数据类型和子系统之间的数据交互方式,为后续系统的详细设计提供了重要依据。
2.1 需求分析概述
需求分析是新开产品调研和总结的一个过程,是一个软件市场定位的重要依据。完整的需求分析需要充分考虑用户群体特征、产品特征、市场竞争等多个相关因素,通过比对自身的长短,选定符合战略战术特色的需求方案。
2.1.1 产品特点分析
使用基于Web端和基于Android的计算机辅助考试软件来帮助教师对学生进行定期考查与人工分发试卷进行考察有很大的差异。人工分发试卷会产生大量的纸质材料,且存在物理途径的相关保密问题,以及运输时产生的人力物力的耗损,并且及其容易在一些环节中出现人为失误,例如漏题、泄题等。而且由于存在大量的考试文件,因此在指定信息查找时非常困难。而利用计算机辅助考试软件来帮助教师对学生进行考查则与之不同,该系统把考试试卷的产生、分发、答卷、阅卷、反馈划分为多个功能模块,将人为操作改为计算机操作,降低了人为引发的失误率,并且用户还能可以根据不同需要操作不同的模块,或者是拼凑不同的功能模块以达到用户所需效果。本系统对与市面上普通的考试软件来说,也具有不少的优越性:
- 安全性
普通的考试软件所采用的登录方式是简单的账号-密码式,或是手机+短信验证码的登录方式,均存在些许安全隐患。而本系统所采用的登录方式更加多样化,引入人脸识别登录与指纹验证登录,通过生物特征唯一性保证了登陆安全,极大地减少了因信息泄露而导致的帐号安全隐患。
- 智能性
普通的考试软件无法对主观题进行阅卷,只能针对选择填空或者判断题这类有预设答案的考题类型进行阅卷。本系统引入自然语言处理模式,将用户的主观题答案抽象为精简模式,同后台预设答案结构进行自编码重构,快速对主观题进行判分。
- 趣味性
普通的考试软件在针对汉字笔画考查时,并没有此种类型题目设置,或者仅仅以选择的形式进心考查。本系统采用图像处理模式将学生所手写绘制的汉字轨迹进行特征提取,而后分析并做出识别,最后给予书写得分。
- 高效性
普通的考试软件在信息管理时,大多采用手动录入至信息管理系统或者一些相关的表格软件中,这样子造成大量的人力消耗。本系统采用学生主动填写个人信息,而后通过整体导入的方式管理学生信息;通过爬虫技术+多权重排序模式动态获取高质量的试题并导入题库中。
- 便捷性
普通的考试软件大多是以固定的习题作为一份试卷考查学生学习情况。本系统采用随机生成、自主命题、推荐生成三种模式为教师个性化制定试卷提供了更加便捷的方式,同时改进推荐算法及其重排序模块,提高系统推荐生成试卷的质量水平。
- 可视化
本系统针对学生提交答卷之后,为学生提供个人考情分析,对于学生的考试情况做出可视化分析;在教师方面,提供班级考试情况的可视化分析,尽可能地做到尽善尽美。
2.1.2 用户特征分析
传统的人工考试系统的题库管理、考卷的运输、考卷内容的产生、考试情况反馈等,都是靠考试系统里的教师及学生共同完成的,效率低下且具有一定的误差。随着计算机的普及,使用考试软件系统代替传统考试系统是大势所趋。普通的考试软件系统只能对固定试卷进行管理。计算机辅助考试系统则是在普通考试软件系统的基础上,跟随技术的发展、前沿科学的进步与用户的相关需求,做了很大程度上的功能扩展。本系统的用户类型主要分为以下几类:学生、教师、管理员,他们的特征表现如下:
- 注重信息准确性
学生和教师是非常关注信息准确性的,尤其是在对知识的准确判断上更是要精益求精。学生用户会更倾向于试卷试题的完整性及其严谨性,如果有更好的趣味性、时事性,学生会更加地乐于靠近这类试题,以及答题判分之后的个人考情反馈;教师用户则更加倾向于试卷试题的典型性和创新性,以及后续的班级考情分析;管理员用户会更加倾向于试题的来源及其试题的内容是否合理等。
- 多维度获取信息
对于一个考试软件而言,题库就是它的命门所在,因此如何多维度地获取多样化试题就成了这个软件的关注重点。本系统设计了一个在全网爬取试题信息的爬虫机器人,在爬取相关试题时,还会通过权重函数多方位地计算该试题的得分,从而筛选高质量的试题加入题库中,为管理员谋取便利地同时,也能够利用互联网多维度地获取试题信息。
2.2 功能性需求分析
考试软件的主要功能就是教师生成试题提供学生考试或日常练习,因此考试软件的考试业务是以学生为本,围绕着学生的日常学习进行开展的一项基础活动,而且考情反馈、试卷生成及试题更新也都是围绕着如何让学生收获更多知识作为主要目的而产生的相关性活动。试题能够通过筛选进入试题库,是因为管理员对试题进行了预先的正则化筛选以及多权重筛选,并且也涉及到了题库的实时更新,主要是增删改查等几类操作;试卷生成也是一样的,试卷中的内容从试题库里随机抽取,或教师自主选定,或系统推荐产生,因此会产生一系列的数据传输以及相关数据变动;考情分析则涉及到学生答题结束之后的反馈报告,采用数据可视化的报告模式能够撩动学生及教师的兴奋点,达到意想不到的正反馈效果。本章节就从管理员子系统、教师子系统、学生子系统入手,从三个方面来介绍计算机辅助考试软件的主要功能。
2.2.1 管理员子系统
管理员子系统是对计算机辅助考试软件的基础数据进行采集并导入数据库中,以及对学生、教师的权限进行开闭,有全面具体的管理页面。基础数据主要包括学生信息、教师信息、管理员信息、试题信息、试卷信息、考试信息、考情反馈信息、班级信息等。下面就试题信息的采集为例进行具体分析,下图展示了试题管理用例图。
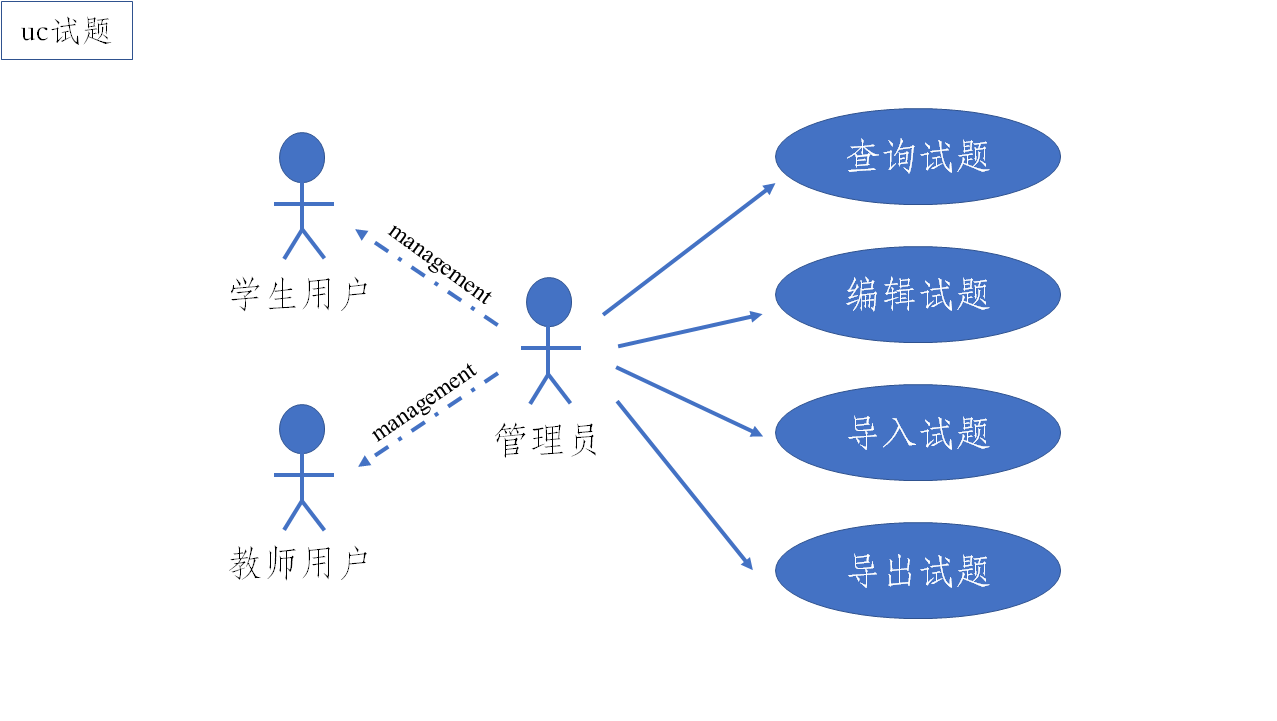
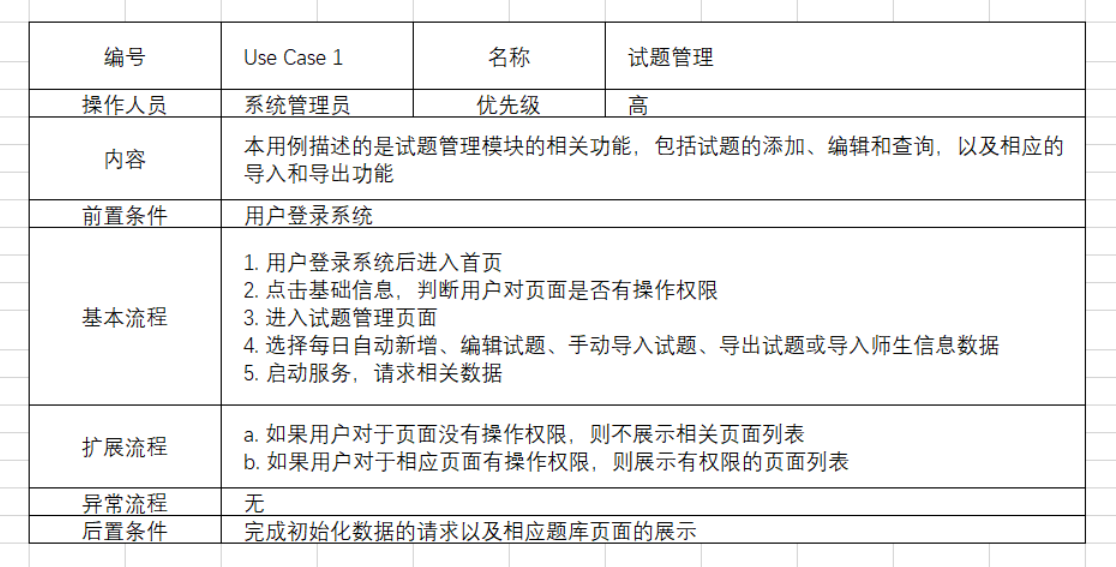
管理员拥有试题管理页面的权限,能够对试题进行查询,按照试题题干、试题类型、导入时间、试题知识点、抽象参考答案、全局正确率、全局错误率等条件进行单一或组合条件查询或筛选。还能够对试题信息做出编辑,试题编辑时只能编辑除导入时间之外的其他信息。另外,管理员也可以对试题进行导入导出,表 2 是试题管理用例说明。
试题数据的采集过程简单,但是工作量比较大。试题数据的采集方法主要有三种,第一种是在页面上进行手动添加,这种方式是单个添加试题,操作效率极慢;第二种方式是批量导入,使用特定的导入模板,利用现有的试题统计资源进行自主导入;第三种是利用网络爬虫机器人在互联网内无差别地爬取试题数据信息,按照类别做好分类及权重得分排序,这种方法适合大规模导入试题,并且能够做到实时迭代。
对于学生和教师的基本信息,可以通过 Excel 表格导入或者是用户主动编辑或修改基本信息,最早的用户个人信息是由系统统一给予的,在用户入驻之后自行添加或修改。而试卷的基本信息,则在教师用户生成该试卷时就已经自动保留在数据库中。
2.2.2 教师子系统
教师子系统主要是用来生成个性化试卷,以满足日常学生学习过程中的查缺补漏以及考查考核学生的阶段性学习情况;还有就是教师作为一个班级的引导者,教师还需要密切关注学生的学习情况,依据考情反馈对学生的学习做出调整或者是直接约谈。因此在教师子系统中,生成试卷和分析考情反馈信息成为两个重要功能模块。其中生成试卷又存在三种主要操作:随机生成、自主选题以及系统推荐。考情反馈则是采用数据可视化之后的答题情况分析。而且只有经由教师产生试卷之后,学生才能够进行答题,进行后续的一些相关操作,因此教师子系统是计算机辅助考试软件中十分重要的一个子系统,起到“活水”的关键作用的。
试卷生成在教师子系统中可以分为三种操作,随机生成、自主选题以及推荐生成。又因为试卷中的试题存在四种基本类型:选择题、判断题、填空题和综合题,因此试卷生成在教师子系统中正是对各种类型题目数据的一种管理与分发。
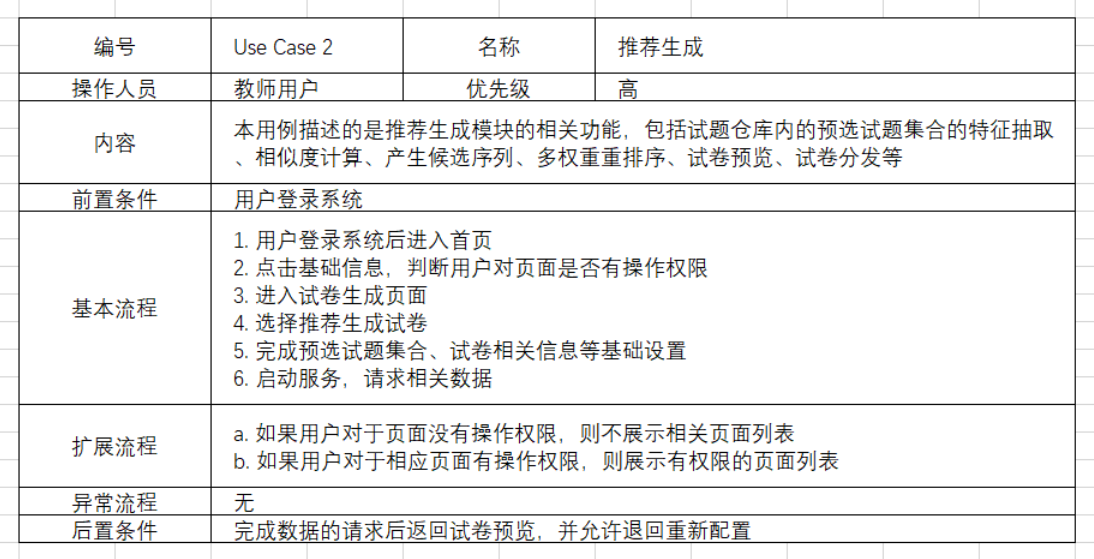
下面就以试卷生成中的推荐生成操作为例进行具体的分析,图 9 表示推荐生成用例,表 3 表示推荐生成的用例说明。
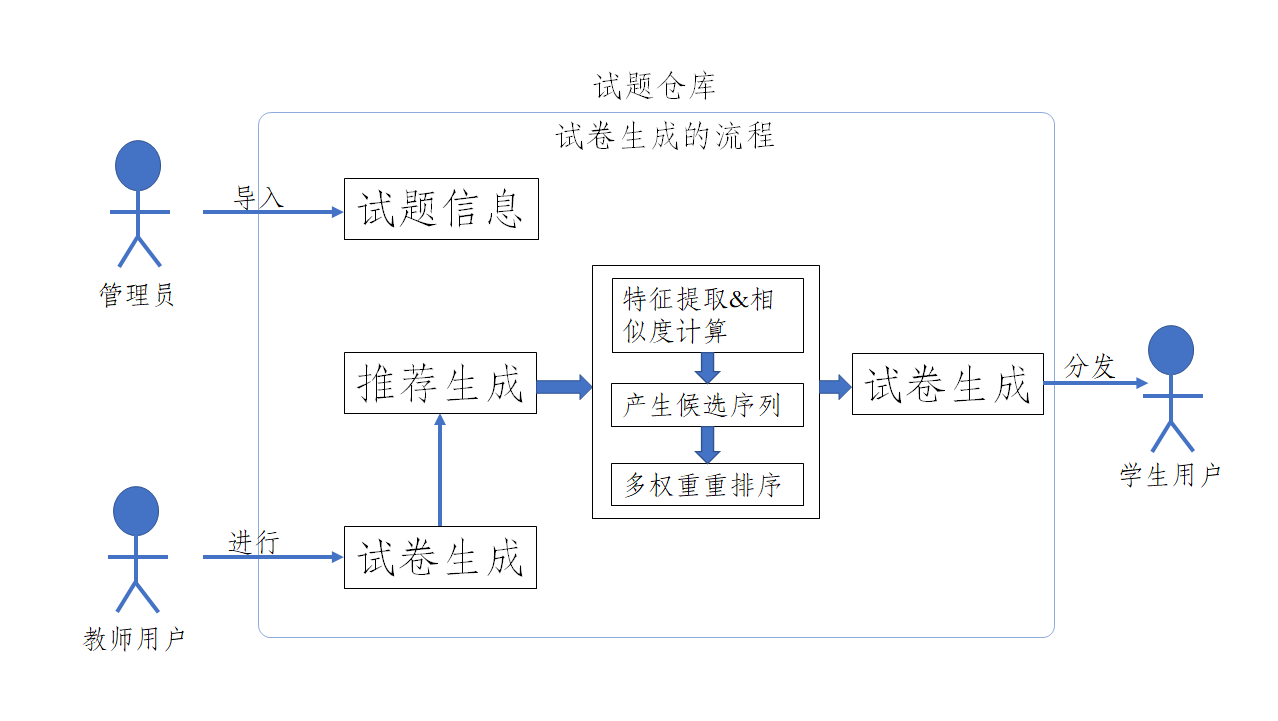
管理员通过多种渠道将大量的试题信息导入到试题仓库中以供教师用户进行试卷生成。教师用户采用推荐生成操作来完成试卷制定,其中推荐生成的主要步骤是通过早期导入是的特征抽取,然后计算内容之间的相似度,然后得到一串试题候选序列,接着进行多权重重排序,得到我们所需要的最终试题序列,依序生成文档文件分发给学生用户,提供给学生用户以课堂考察或自查自纠。
一份好的试卷,首先会通过大量的试题信息通过层层筛选之后呈交到教师用户的案前。它可以是通过多种方式进行生成的,在前文中也做出了非常详尽的方式提及,一共就是三种不同的生成模式,随机、自主、推荐。对于新产生的考试文档文件,系统会首先提交给提出生成卷宗的教师用户审核,审核通过之后在相应的试卷数据库中做出备份操作,接着再分发给指定班级进行后续考察工作。关于本节中对于推荐生成的相关详细描述,将会在第四章的系统详细设计与实现的关于推荐系统模块的详细说明中开展进一步地阐述。
2.2.3 学生子系统
在本系统中,学生用户是最为关键的一类用户群体,会占到用户总群体的 95% 以上,而在学生子系统中最关键的一环就是考试子系统。考试子系统中又进一步分为考试模块、反馈模块与基本模块。因为学生考试需要定时计时,因此基本模块需要内置计时器,当倒计时结束时,考试随之结束;为了提供学生用户以便捷,基本模块中还需要内置选题功能,以方便学生用户快速的浏览卷面或者是切换试题;最后的提交功能则更不必说,是数据封装成 json 传输的关键一环。
反馈模块则是采用数据可视化设计,提供多元化的图表反馈;靓丽的色彩搭配,能够使得学生更加乐于参与考试,实时监测到自己的成长,同时反馈信息也会以班级为整体反馈给任课老师,老师依据班级反馈情况给予相应的整改与约谈。
整个子系统的重点,也是整个软件的关键在于学生考试模块,有大量的数据信息通过学生的行为表现与答题情况结合机器学习得到一定的相关预测。考试模块中依据题目类型整体划分为选择题、判断题、书写题和综合题。其中判断与选择属于简单的字符匹配;而书写题则涉及到汉字结构设计与汉字字形设计,并结合轨迹识别等计算机视觉相关的图像处理做出相应地判分;综合题,主要是指没有标准答案的主观题,例如阅读理解、写作等类型习题,因此引入自然语言处理对上述综合题进行相关分析,依靠多种统计学习方法抽象出学生主观题答题梗概后,与后台进行对比判分。
本小节就针对考试模块中的书写题做出详细描述,其中图 10 为书写题答题用例与表 4 为书写题答题用例说明。
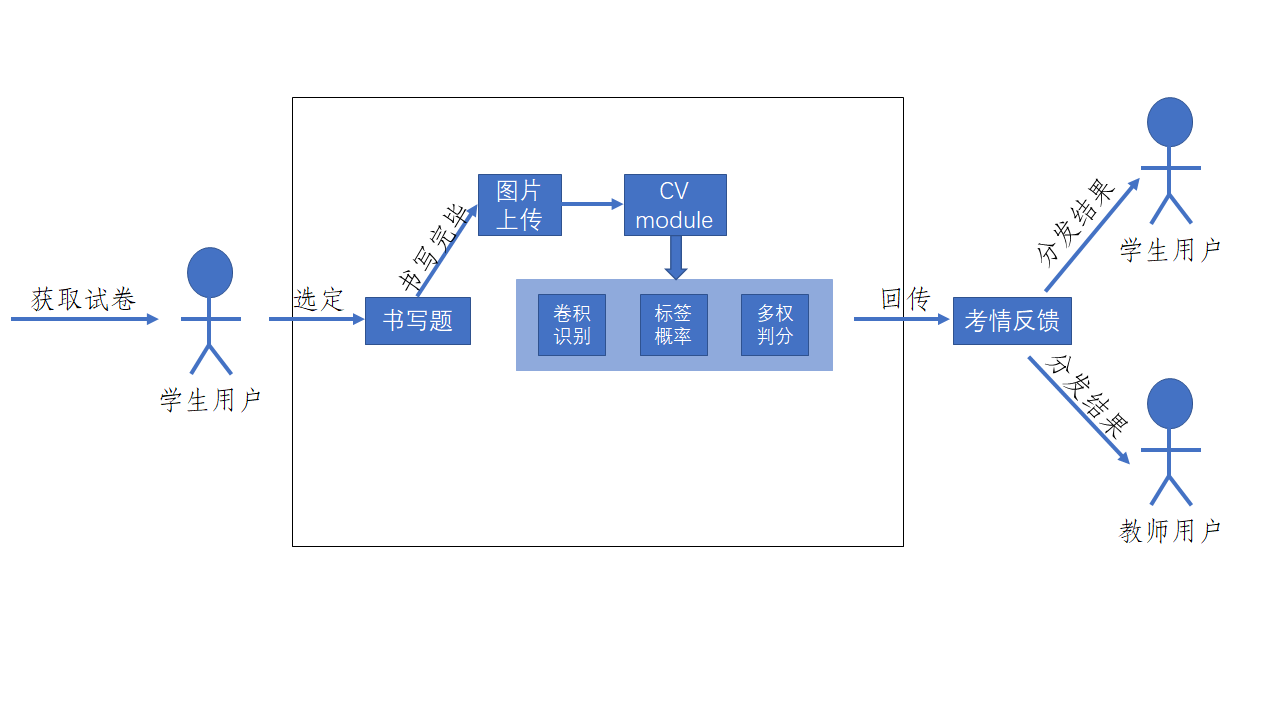
计算机辅助考试软件的考试模块是整个软件的核心,而考试模块有包含多个子模块,其中对于汉字书写题的考量又相对其他模块更加复杂一些。当教师完成试卷生成之后,学生用户获取考试试卷,接着选择书写题进行书写,当书写完毕后,所有书写片段将会各自整合成图片,然后封装成基础数据包,等待答题完成之后的整体上传提交。对于书写图片部分的基础数据包将会传送至计算机视觉模块种,进行卷积识别、标签概率的计算与多权重判定得分,然后再等待其他试题判分完毕后回传至考情分析中做数据可视化分析绘制,最后分发给学生用户与教师用户进行反馈。
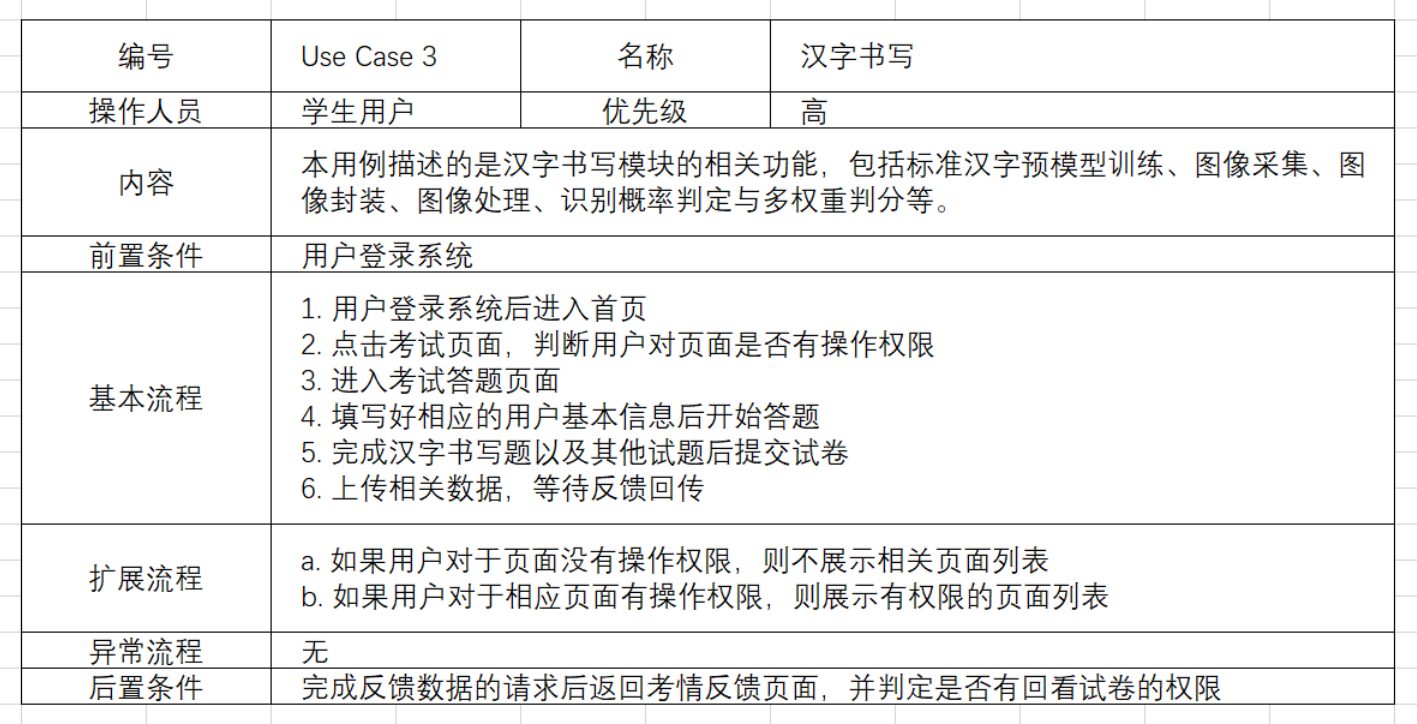
上表基本详细地阐述了汉字书写答题用例的相关说明,其中具体的功能详细设计将会在第四章的系统详细设计与实现的关于计算机视觉模块的详细说明中开展进一步地阐述。
2.3 非功能性需求分析
普通的考试系统只会提供选择、填空、判断等基本的考试模式,并不能满足现代化考试的基本需求,本文所描述的计算机辅助考试系统不仅仅具有基础的考试模式,还具有更加多样化的考试功能,自然语言分析,图像识别等功能。所以,在非功能性需求上也要有一定的分析。
- 稳定性
系统稳定性是一个系统最基本的要求,对于吸引用户来说,也是一个很重要的方面,如果用户在系统使用过程中,出现极其频繁的软件故障,肯定会极大地降低用户体验程度,从而更换其他的选择。因此计算机辅助考试软件在运营过程中,不能出现严重问题,即使出现了问题,也应该能及时修复。
- 流畅性
流畅性是用户体验中很重要的特性,要保证用户在操作系统的过程中,系统反应顺畅,即使遇见数据量较大的情况,系统的响应时间也不能超过用户的可接受范围,一般最长要控制在五秒以内。这种情况在进行导入与导出,或者处理业务复杂情况时会出现。如果出现系统响应时间过长,则应及时地提醒用户,而不是没有任何提醒的冷处理。
- 易用性
系统页面是一个系统的门户,能够给用户留下第一印象的也是系统的页面。系统页面设计要尽可能的符合当前大众用户的审美及其使用习惯,在得知用户的某一操作时,要猜测用户接下来的后续操作有哪些,从而将相应的操作按钮摆放在系统显眼的位置,以方便用户使用,提高系统的易用性。
3. 软件概要设计
3.1 软件设计目标

如图所示,计算机辅助考试软件的设计目标在于能够完成上述三条指标,并且在此基础上加入更多个性化功能。
3.2 软件整体设计概貌
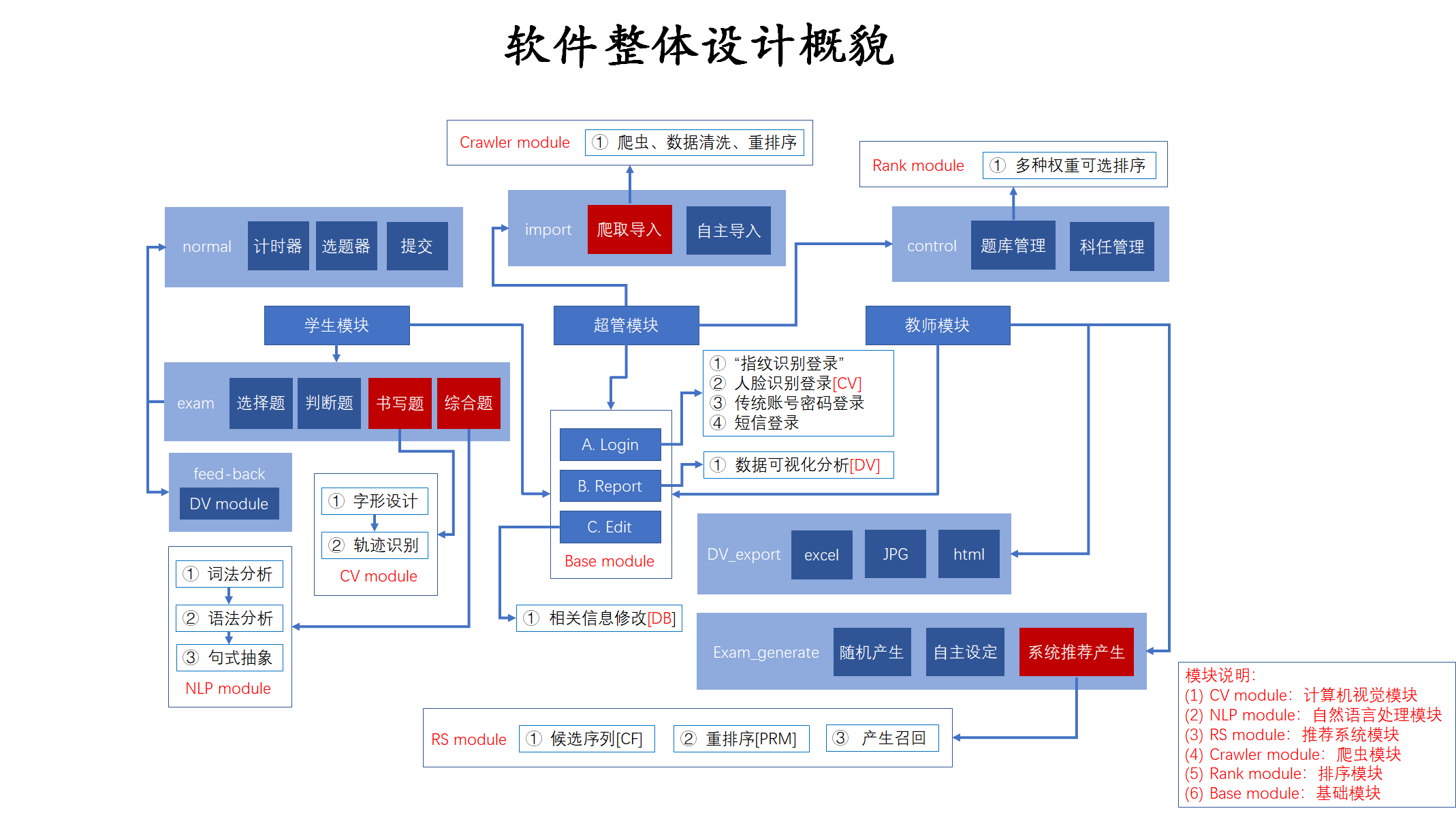
软件设计概貌如上图所示,其中我们将整个系统划分为六个模块,即:
- 计算机视觉模块
- 自然语言处理模块
- 推荐系统模块
- 排序模块
- 爬虫模块
- 基础模块
这些模块将在第四章和第五章中进行详细的阐述,并且给予准确可用的程序关键代码及其注释。让我们先对这个软件的概貌设计做出详细阐述。首先三类用户都具有登录、反馈、编辑这三类基本操作,因此它们被归为 base module,即基础模块。然后学生用户可以通过接收教师分发的试卷进行答题,进入答题区域之后会出现计时器、选题器、提交这三个功能构件,它们被称之为 normal module,即普通模块,然后还会看见 exam module 中的选择题、判断题、书写题和综合题,等到答题完成之后,会出现可视化考情分析,也就是 DV module,由 DV module 生成的数据会传输给教师用户进行考后访谈。当教师用户登录时,他可以进行的是考情的审查、试卷的生成等相关功能,而管理员则是进行试题的导入与系统相关控制。
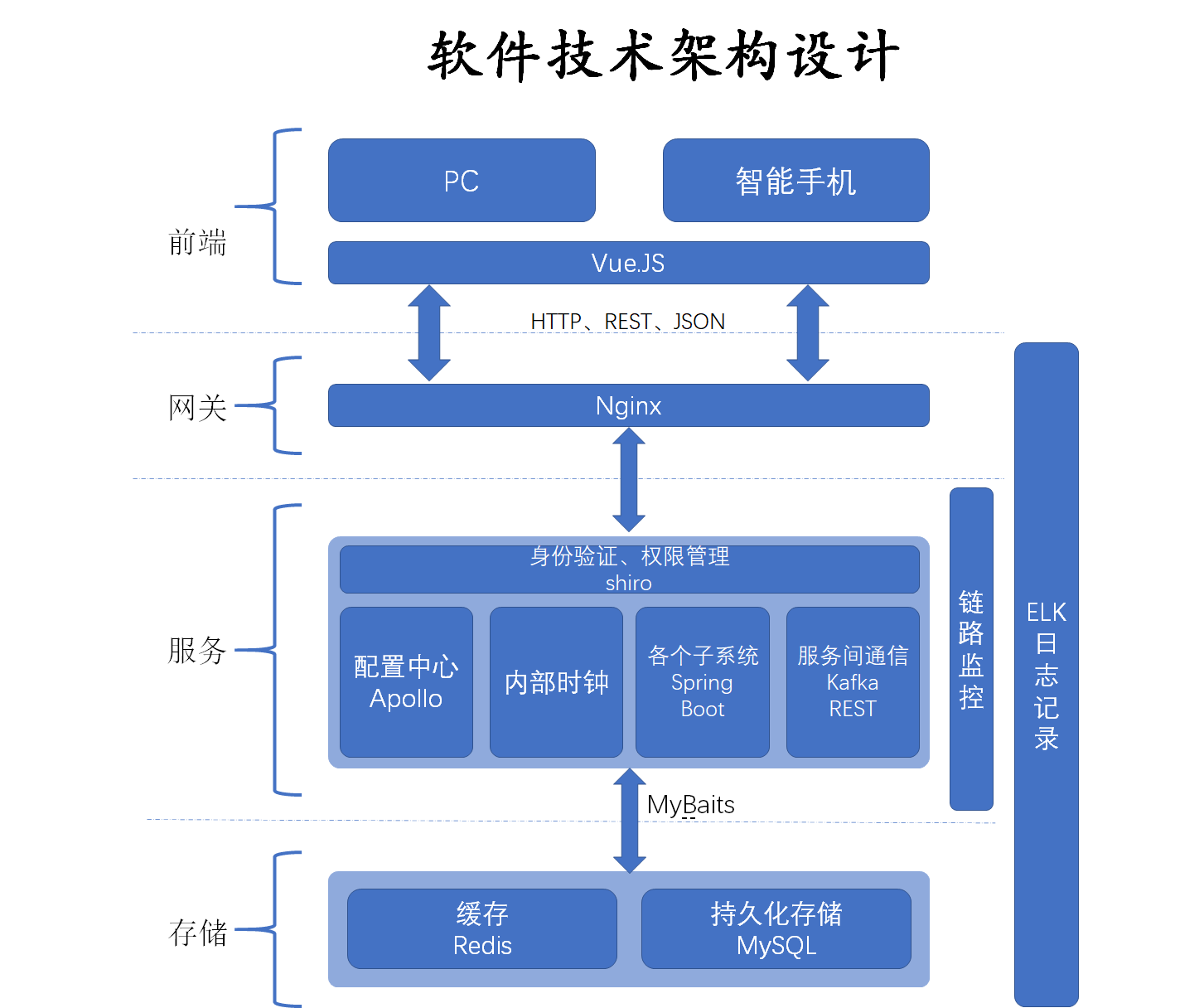
3.3 软件技术架构设计
在计算机辅助考试软件的技术架构设计上,我们前期采用微服务架构的模式,将整个大的系统拆分为六个子模块,每个子模块单独部署运行。对于访问量较大的子模块还可以做集群部署、负债均衡,并且提供了 API 网关对请求进行负载路由,提高了每个子模块的高度可用性。并且提供了全面的链路监控,对子模块之间的数据、信息等相关交互进行监控,加强了集群的稳定性。本系统的技术架构如下图所示:
- 前端
计算机辅助考试软件的前端主要分为两个端口,一个是个人电脑端口,PC用户可以使用电脑浏览器进行更全面的系统使用。另一个则是智能手机,采用智能手机主要是为了能够使得人脸识别、手写识别等能够使用摄像头的功能更加好用。本软件系统的开发过程采用了前后端分离的方式,个人电脑端采用的是目前主流的前端框架 Vue.JS,智能手机同样对此做出了适配。
- 网关
网关采用 Nginx 作为路由,能够将前端的请求分流分量的发送给后端服务,能够实现基本的负载均衡,甚至可以通过中间件的方式构造更加高强度的负载均衡方案,减少了后端的服务压力。
- 服务端
服务端采用的是 Spring 系列框架,使用 Spring Boot 的开发框架,加快了开发效率,并且采用注释方式可以减少代码量,已完成快速实现系统功能的需求。
服务端接口和页面交互采用 RESTFUL 风格,后端提供 Rest 接口,前后端通信协议采用 HTTP 协议,数据传递方式使用 JSON。
后端的权限框架采用的是 Shiro,Shiro 是一个简单易用的权限框架,主要是使用了 Shiro 的身份验证和授权的功能。用户信息存放在数据库中,使用 Shiro 需要定制特定的 Realm,从而在用户登录时,能够根据用户填写的信息和数据库中的真实信息进行校验。用户权限同样也是存放在数据库中,用户加载页面时会通过 Shiro 定制的 Realm 访问数据库,加载用户权限下的列表数据。
系统的每个配置项通过 Apollo 来进行管理,以键值对的格式进行存储,系统加载配置项时可以使用 Spring 的“$”进行取值。而且 Apollo 的配置项可以有更新就自动推送,这避免了使用配置文件时无法热加载的问题。
在定时服务中,使用了xxl-job 技术,能够方便快捷地进行定时任务操作。
各个子模块之间的同步调用通过 Eureka 使用 Rest 接口调用的方式;而存在一部分异步处理地信息则通过 Kafka 消息队列进行消息传递,不需要及时反馈处理结果。
在后端功能实现的过程中,可能存在一个功能调用了多个服务接口,为了方便定位错误位置,后端服务中采用了 SkyWalking 进行链路监控,它能够监控服务调用过程中是否超时,以及定位超时地服务,并且这个技术还提供了可视化页面,能够快速分析服务运行性能、查看超时情况以及展示服务调用拓扑结构等功能。
日志处理采用了 ELK 的框架进行日志收集和分析。系统中通过 slf4j 框架作为日志门面,使用 Logback 打印记录各种日志,ELK 框架则从服务器上收集系统打印的日志,并展示在管理页面中,方便日志查询和问题定位。
- 数据存储
数据存储技术使用了开源的 MySQL,计算机辅助考试软件所涉及到的大部分数据使用关系型数据库存储,这样子能够更好的表现数据之间的关系。 MySQL 架构采用了主从模式实现读写分离,降低了主库的压力,增加了数据库的可用性。另有部分需要经常被查询但是又不经常变动的数据,采用 Redis 缓存存储,例如用户的基本信息,查询时可以先查询缓存,如果能够查询到该数据,则直接返回,提高了查询效率,也降低了物理数据库的压力。
3.4 数据库设计
本项目的数据库使用的是阿里云提供的 MySQL 服务,PC 端和移动端通过后端接口来访问数据。本小节主要通过一些重点数据表的结构,来介绍计算机辅助考试系统的数据库设计。
3.4.1 基础数据表设计
基础系统模块主要包括学生、教师、管理员、班级、试题、试卷的信息管理,对于不同的信息内容都有相应的数据库表单进行存储。学生表是存储学生的基本信息,比如说学生的学号、姓名、班级、身高、体重、账号名称、密码哈希等相关信息。教师表和管理员表主要是存储教师基本信息以及管理员基本信息的表单,主要包括工号、姓名等,其中教师表主要是用以存储教师及其下辖班级的一个基本信息情况,管理员表则是存储控制权限以及管理员个人信息的基本表单。班级表要存储班级的基本信息,例如班级名称、编号;试题表则是存储试题的基本信息,包括试题编号、入库时间、被使用次数等;试卷表主要存储的是试卷编号、试卷生成日期等基本信息。
我们都很清楚的是,一个教师可以对应多个学生,一个管理员可以对应多个教师,一个班级对应一个教师,一个班级同样对应多个学生,一套试卷可以对应多个学生,一个试题可以对应多个试卷而且一个试卷可以包含多个不同的试题。下图展示了基础数据表之间的 E-R 关系:
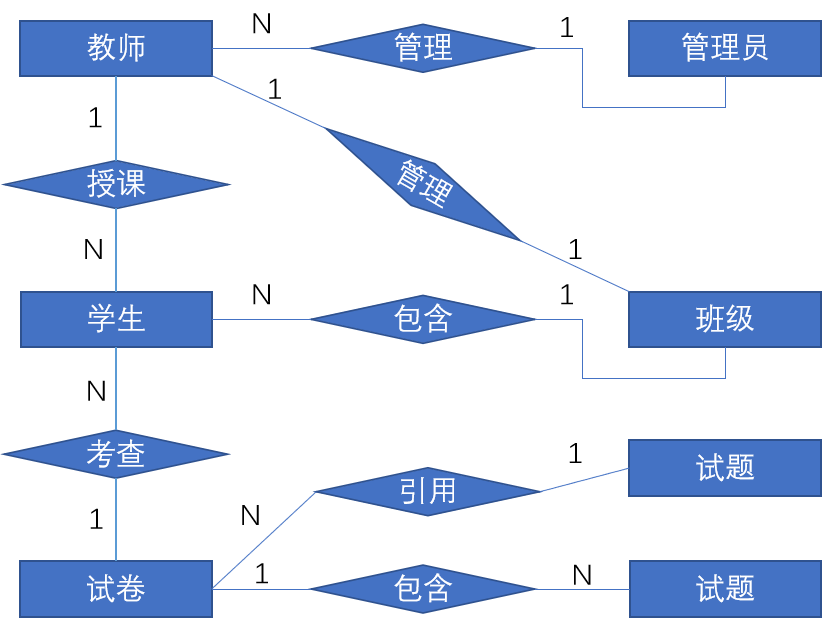
表名:stu_infomation
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | stu_code | VARCHAR | 64 | 学生学号 |
| 3 | stu_name | VARCHAR | 64 | 学生姓名 |
| 4 | stu_class | VARCHAR | 64 | 学生班级 |
| 5 | stu_height | DECIMAL | 18,2 | 学生身高 |
| 6 | stu_weight | DECIMAL | 18,2 | 学生体重 |
| 7 | stu_home_address | VARCHAR | 128 | 学生家庭住址 |
| 8 | stu_school_address | VARCHAR | 128 | 学生宿舍住址 |
| 9 | stu_per_answer_time | DECIMAL | 18,4 | 学生答题平均时长 |
| 10 | stu_per_submit_exam_time | DECIMAL | 18,4 | 学生交卷平均时长 |
| 11 | stu_username | VARCHAR | 64 | 学生账户名 |
| 12 | stu_password_hash | VARCHAR | 256 | 学生密码哈希值 |
| 13 | stu_avatar | VARCHAR | 256 | 学生头像图片地址 |
| 14 | stu_motto | VARCHAR | 128 | 学生座右铭 |
| 15 | stu_per_face_passtime | VARCHAR | 18,4 | 学生人脸识别平均时长 |
| 16 | stu_sellphone | BIGINT | 20 | 学生手机号码 |
| 17 | stu_email | VARCHAR | 64 | 学生电子邮箱 |
| 18 | stu_face_feature | VARCHAR | 65535 | 学生人脸特征数据 |
| 19 | stu_fingerprint_feature | VARCHAR | 65535 | 学生指纹特征数据 |
| 20 | stu_per_exam_score | DECIMAL | 18,2 | 学生答卷平均得分 |
| 21 | stu_max_exam_score | DECIMAL | 18,2 | 学生答卷最高得分 |
| 22 | stu_min_exam_socre | DECIMAL | 18,2 | 学生答卷最低得分 |
| 23 | stu_feedback_count | INT | 11 | 学生查看反馈的次数 |
| 24 | stu_gender | VARCHAR | 32 | 学生性别 |
| 25 | stu_is_generate_exam | TINTINT | 4 | 学生是否可以生成试卷 |
| 26 | stu_birthday | DATETIME | - | 学生出生日期 |
| 27 | stu_is_vip | TINYINT | 4 | 学生是否为VIP用户 |
表名:global_exam_infomation
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | exam_name | VARCHAR | 64 | 试卷名称 |
| 3 | exam_time_length | INT | 11 | 考试时长(秒) |
| 4 | exam_total_score | INT | 11 | 考试总分(分) |
| 5 | exam_about_class | VARCAHR | 128 | 考试班级 |
| 6 | exam_total_student | INT | 11 | 考试总人数 |
| 7 | exam_max_score | INT | 11 | 考试最高分 |
| 8 | exam_min_score | INT | 11 | 考试最低分 |
| 9 | exam_avg_socre | INT | 11 | 考试平均分 |
| 10 | exam_generate_type | VARCHAR | 64 | 试卷生成的方式 |
| 11 | exam_generate_by | VARCHAR | 64 | 试卷被谁生成 |
| 12 | exam_open | TINYINT | 4 | 试卷是否开放 |
| 13 | exam_close_review | TINYINT | 4 | 试卷是否允许回看 |
| 14 | exam_problem_feature | VARCHAR | 65535 | 试卷试题特征 |
| 15 | exam_submit_forward | TINYINT | 4 | 试卷是否可提前交卷 |
| 16 | exam_is_need_password | TINTINT | 4 | 试卷是否需要密码 |
| 17 | exam_password | VARCHAR | 64 | 试卷密码 |
| 18 | exam_enter_count | INT | 11 | 进入考试人数 |
| 19 | exam_studnet_feature | VARCHAR | 65535 | 考试学生特征 |
| 20 | exam_latest_in | DATETIME | - | 最晚进入考试学生 |
| 21 | exam_earliest_out | DATETIME | - | 最早提交考卷学生 |
| 22 | exam_begin | DATETIME | - | 考试开始时间 |
| 23 | exam_end | DATETIME | - | 考试结束时间 |
| 24 | exam_stu_rank | VARCHAR | 65535 | 考试排名情况 |
| 25 | exam_avg_likely | DECIMAL | 18,2 | 试卷平均好评度 |
表名:tech_infomation
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | tech_code | VARCHAR | 64 | 教师工号 |
| 3 | tech_name | VARCHAR | 64 | 教师姓名 |
| 4 | tech_class | VARCHAR | 65535 | 教师授课班级 |
| 5 | tech_is_generate | TINTINT | 4 | 教师是否可以生成试卷 |
| 6 | tech_is_review_total | TINYINT | 4 | 教师是否可回看全员答题 |
| 7 | tech_gender | VARCHAR | 32 | 教师性别 |
| 8 | tech_home_address | VARCHAR | 128 | 教师家庭住址 |
| 9 | tech_school_address | VARCHAR | 128 | 教师在校住址 |
| 10 | tech_level | VARCHAR | 64 | 教师教职级别 |
| 11 | tech_username | VARCHAR | 64 | 教师用户名 |
| 12 | tech_password_hash | VARCHAR | 256 | 教师密码哈希 |
| 13 | tech_sellphone | VARCHAR | 64 | 教师手机号码 |
| 14 | tech_email | VARCHAR | 64 | 教师电子邮箱 |
| 15 | tech_examed_count | INT | 11 | 教师已举办考试次数 |
| 16 | tech_examed_generate | INT | 11 | 教师已生成试卷次数 |
| 17 | tech_total_student | INT | 11 | 教师生涯教学总人数 |
| 18 | tech_is_vip | TINYTINT | 4 | 教师是否为VIP用户 |
| 19 | tech_face_feature | VARCHAR | 65535 | 教师人脸数据 |
| 20 | tech_face_avgpass_time | DECIMAL | 18,2 | 教师人脸识别平均时长 |
| 21 | tech_fingerprint_feature | VARCHAR | 65535 | 教师指纹数据 |
| 22 | tech_fingerprint_avgpass_time | DECIMAL | 18,2 | 教师指纹识别平均时长 |
| 23 | tech_avg_exam_pass | DECIMAL | 18,2 | 教师考试平均通过率 |
| 24 | tech_avg_person_score | DECIMAL | 18,2 | 教师受学生平均好评度 |
| 25 | tech_review_feedback_count | INT | 11 | 教师查看学生反馈次数 |
| 26 | tech_favorite_stu_code | VARCHAR | 64 | 教师最喜爱的学生学号 |
| 27 | tech_is_export | TINYINT | 4 | 教师是否可导出反馈表格 |
| 28 | tech_export_count | INT | 11 | 教师导出反馈总次数 |
| 29 | tech_avator | VARCHAR | 256 | 教师头像地址 |
| 30 | tech_motto | VARCHAR | 256 | 教师座右铭 |
| 31 | tech_birthday | DATETIME | - | 教师出生日期 |
| 32 | is_use_nlp_help | TINYINT | 4 | 教师是否可使用NLP辅助 |
| 33 | is_use_cv_help | TINYINT | 4 | 教师是否可以使用CV辅助 |
| 34 | is_use_rs_help | TINYINT | 4 | 教师是否可以使用RS辅助 |
| 35 | is_use_dv_help | TINYINT | 4 | 教师是否可以使用DV辅助 |
表名:class_infomation
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | class_code | VARCHAR | 64 | 班级编号 |
| 3 | class_name | VARCHAR | 64 | 班级名称 |
| 4 | class_stu_count | INT | 11 | 班级学生人数 |
| 5 | class_stu_code_feature | VARCHAR | 65535 | 班级学生学号序列特征 |
| 6 | class_tech_code_feature | VARCHAR | 64 | 班级授课教师工号特征 |
| 7 | class_total_exam_count | INT | 11 | 班级总考试次数 |
表名:admin_infomation
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | admin_code | VARCHAR | 64 | 管理员工号 |
| 3 | admin_name | VARCHAR | 64 | 管理员名称 |
| 4 | admin_gender | VARCHAR | 32 | 管理员性别 |
| 5 | admin_sellphone | VARCHAR | 32 | 管理员手机号码 |
| 6 | admin_email | VARCHAR | 64 | 管理员电子邮箱 |
| 7 | admin_face_feature | VARCHAR | 65535 | 管理员人脸数据 |
| 8 | admin_username | VARCHAR | 64 | 管理员用户名 |
| 9 | admin_password_hash | VARCHAR | 256 | 管理员密码哈希 |
| 10 | admin_avatar | VARCHAR | 256 | 管理员头像地址 |
| 11 | admin_motto | VARCHAR | 256 | 管理员座右铭 |
| 12 | is_admin_crawler | TINYINT | 4 | 是否可全网爬取导入题库 |
| 13 | is_admin_diversity_rank | TINYINT | 4 | 题库是否可多元化排序 |
| 14 | is_admin_grobal | TINYINT | 4 | 是否为全局管理员 |
| 15 | admin_import_count | INT | 11 | 管理员手动导入题库次数 |
表名:problem_information
| 序号 | 字段号 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | problem_id | VARCHAR | 64 | 试题编号 |
| 3 | problem_type | VARCHAR | 32 | 试题类型 |
| 4 | problem_import_method | VARCHAR | 32 | 试题导入模式 |
| 5 | problem_is_export | TINYINT | 4 | 试题是否支持导出 |
| 6 | problem_rank_intact | TINYINT | 4 | 试题完整度 |
3.4.2 考试过程相关表设计
上一小节中已经将本系统的基础数据表设计完成,接下来是设计考试单,一个标准的考试单中将会包含监考教师信息、参考学生信息、试卷信息、考试基本信息,看上去似乎和基础数据表中的试卷表单相似,但其实是一个整合。其 E-R 图设计如下:
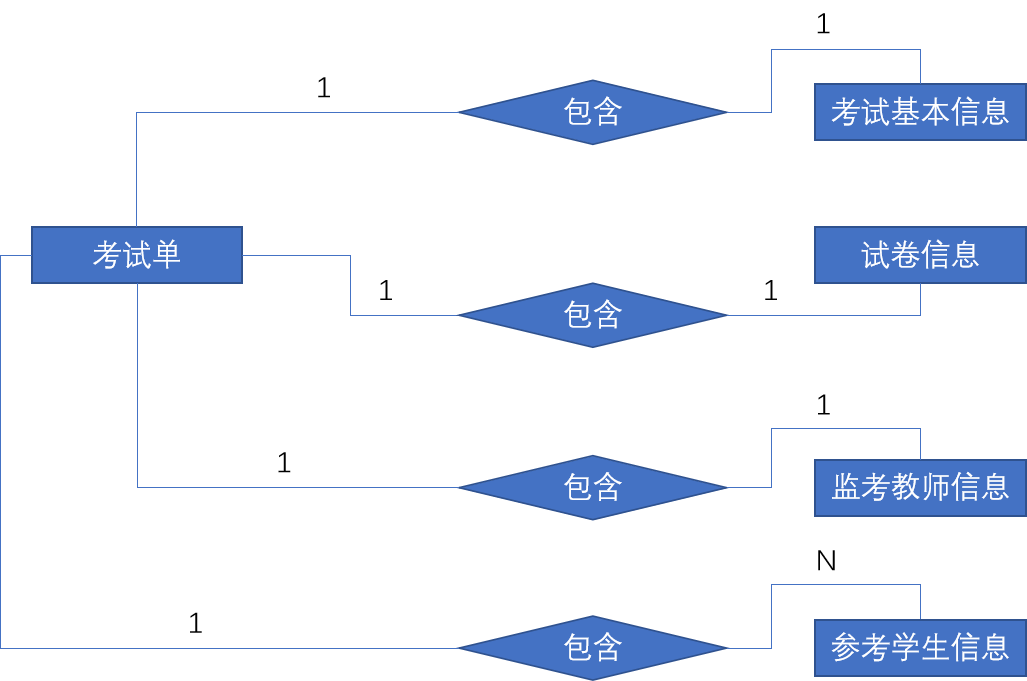
其中试卷信息、参考学生信息、监考教师信息[默认为科任老师]均为基础数据表中的试卷表详细信息、教师表详细信息、学生表详细信息,而考试基本信息则包括考试开始时间、考试结束时间、出卷人、保密等级、考试地点等基础信息。因此考试单表设计如下:
表名:exam_unit_information
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | exam_code | VARCHAR | 64 | 考试编号 |
| 3 | exam_startdate | DATE_TIME | - | 考试开始时间 |
| 4 | exam_overdate | DATE_TIME | - | 考试结束时间 |
| 5 | exam_join_tech_code | VARCHAR | 64 | 监考教师工号 |
| 6 | exam_join_stu_code | VARCHAR | 65535 | 参考学生学号[序列] |
| 7 | exam_address_code | VARCHAR | 64 | 考试教室编号 |
| 8 | exam_generate_by | VARCHAR | 64 | 出题教师工号 |
| 9 | exam_is_open | TINYINT | 4 | 是否开卷[默认:否] |
| 10 | exam_confidentiality_level | TINYINT | 4 | 保密等级 |
3.4.3 答卷卡相关表设计
整个答卷的过程中,会产生大量的答卷数据信息,其中有部分数据是系统不做录入的,例如草稿数据信息,这部分内容由于处理过程较为复杂因此不做录入,也不要求进行处理,只针对四大类题目做出数据录入,即选择题、填空题、书写题、综合题。通过可行性分析中对相关系统的研究可知,系统仅仅处理客观题部分,而对于主观题则采用人工阅卷的方式,本系统则对主观题也采取自动化处理,其中的答卷数据完不完整便是系统能不能做好处理主观题的关键所在。答题过程的相关表 E-R 图如下所示:
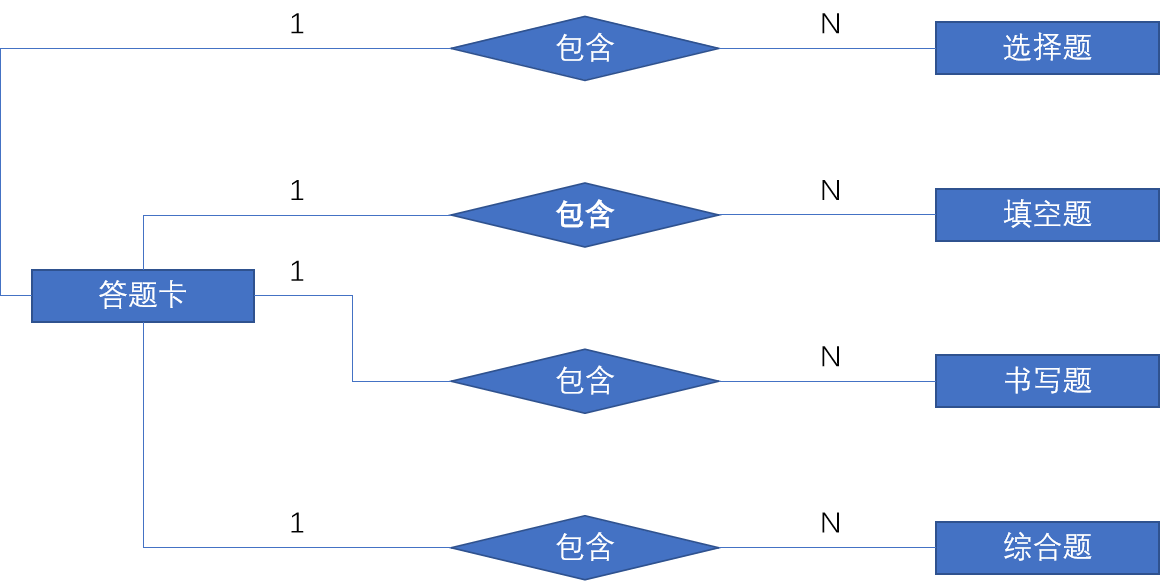
在答题卡中,除了上述的试题答案数据之外,还需要有参考学生学号、班级、姓名等基础信息。
表名:answer_sheet_information
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | answer_sheet_code | VARCHAR | 64 | 答题卡唯一编号 |
| 3 | answer_join_stu_code | VARCHAR | 64 | 答题卡填学生学号 |
| 4 | answer_join_class_code | VARCHAR | 64 | 答题卡填班级编号 |
| 5 | answer_join_stu_name | VARCHAR | 64 | 答题卡填学生姓名 |
| 6 | answer_choose_code | VARCHAR | 64 | 学生选择题作答编号[外] |
| 7 | answer_fill_code | VARCHAR | 64 | 学生填空题作答编号[外] |
| 8 | answer_write_code | VARCHAR | 64 | 学生书写题作答编号[外] |
| 9 | answer_multiple_code | VARCHAR | 64 | 学生综合题作答编号[外] |
| 10 | answer_is_abandon | TINYINT | 4 | 学生是否缺考 |
表名:choose_information
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | choose_code | VARCHAR | 64 | 选择题答案编号 |
| 3 | choose_answer_list | VARCHAR | 65535 | 选择题答案序列 |
| 4 | choose_is_submit | TINYINT | 4 | 是否提交选择题 |
表名:fill_information
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | fill_code | VARCHAR | 64 | 填空题答案编号 |
| 3 | fill_answer_list | VARCHAR | 65535 | 填空题答案序列 |
| 4 | fill_is_submit | TINYINT | 4 | 是否提交填空题 |
表名:write_information
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | write_code | VARCHAR | 64 | 书写题答案编号 |
| 3 | write_answer_feature | VARCHAR | 65535 | 书写题答案特征 |
| 4 | write_is_submit | TINYINT | 4 | 是否提交书写题 |
表名:multiple_information
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | multiple_code | VARCHAR | 64 | 综合题答案编号 |
| 3 | multiple_answer_feature | VARCHAR | 65535 | 综合题答案特征 |
| 4 | multiple_is_submit | TINYINT | 4 | 是否提交综合题 |
如果仅从表的结构及其类型分布来看,四种类型题目的表结构是一致的,但是从内容数据在具体处理中来看,却是大相径庭。其中选择与填空属于客观直接判断,机改正确率接近100%;而书写与综合则需要采用计算机视觉技术与自然语言处理技术进行处理,尤其是在书写题中,一个汉字的特征信息便高达 16 维,需要更大的算力去处理分析这个字的结构正确度与美感评分,因此尽管表结构相同,但其中数据构成是不同的。
3.4.4 反馈过程相关表设计
反馈过程主要是针对答题情况做出分析,其中会依据总体情况以及分类型与分题情况进行分析反馈。反馈过程的 E-R 图设计如下:
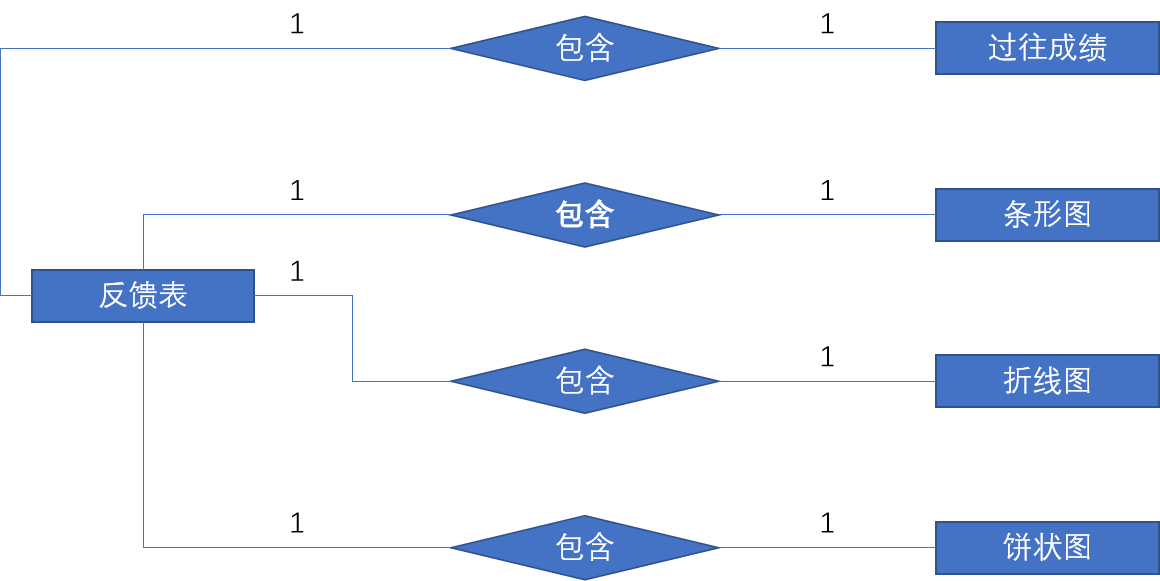
表名:feed_analysis_information
| 序号 | 字段名 | 类型 | 长度 | 描述 |
|---|---|---|---|---|
| 1 | id | BIGINT | 20 | 自增主键id |
| 2 | feed_code | VARCHAR | 64 | 反馈编号 |
| 3 | feed_stu_code | VARCHAR | 64 | 反馈学生学号 |
| 4 | feed_exam_code | VARCHAR | 64 | 反馈考试编号 |
| 5 | feed_ten_achievement_list | VARCHAR | 256 | 最近十次成绩序列 |
| 6 | feed_is_lines | TINYINT | 4 | 是否绘制折线图 |
| 7 | feed_is_bars | TINYINT | 4 | 是否绘制条形图 |
| 8 | feed_is_circles | TINYINT | 4 | 是否绘制饼状图 |
| 9 | feed_about_choose | VARCHAR | 65535 | 选择题得分情况 |
| 10 | feed_about_fill | VARCHAR | 65535 | 填空题得分情况 |
| 11 | feed_about_write | VARCHAR | 65535 | 书写题得分情况 |
| 12 | feed_about_multiple | VARCHAR | 65535 | 综合题得分情况 |
| 13 | feed_about_tips | VARCHAR | 65535 | 温馨小贴士 |
在设计整个反馈过程时,应当按照反馈表单的结构不断向下解构。到这里,整个表结构的设计就完成了,基础数据表设计是整个系统的基础基石,许多的相关表设计都从基础设计开始做出延申,尤其是在对于后续的相关设计上,采取分层次数据库设计使得整个数据库的结构变得更加立体,也对后续的详细设计开发奠定了数据信息基础。至此对于数据库设计便告一段了,下一小节将会讲述服务接口设计,对于类接口的相关设计尽管应该是放在详细设计中,但是在第四章详细设计中,我们更加倾向于把我们为本系统所设计或在原有的基础上做出改进的的算法做出详细阐述。
3.5 服务接口设计
整个系统在技术架构上分为前端、网关、后端服务、存储,本节主要讲述后端服务接口的相关设计。前端展示页面通过调用各个子系统的后端接口来访问数据库,查询相关数据并作出展示。前端页面通过HTTP协议调用后端接口,传递参数的方式使用 JSON 字符串。后端将对数据的返回封装成一个 WebRespondse 类,用来返回成功信息、失败信息以及分页信息等公共数据,后端将封装好的类转化为 JSON 字符串的形式返回给前端页面。
3.5.1 基础数据相关接口设计
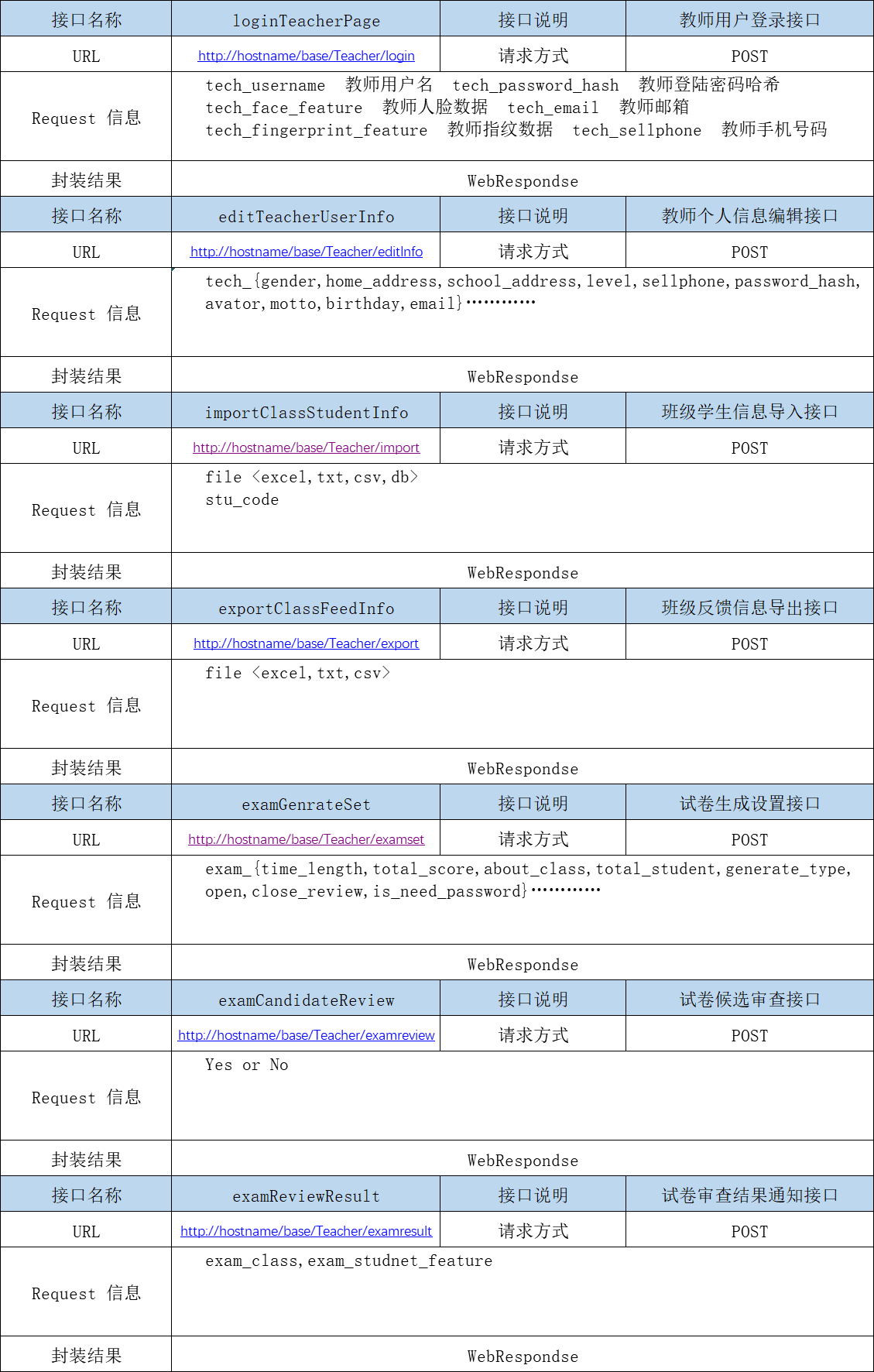
基础模块中所涉及到的页面比较多,包括各类人员的私有用户页面、考试首页、生成试卷页面、权限开放页面等,因此使用的接口也会比较多。下面就以教师管理页面作为例子进行讲述,展示相关的接口对照表信息。教师管理页面的接口包括以下几个,如下表所示,教师登录接口、教师个人信息编辑接口、班级学生信息导入接口、班级反馈情况的导出接口、试卷生成的设置接口、试卷候选审查接口、审查程序的通知分发接口。
3.5.2 考试相关接口设计
考试模块实际上并不能算作一个子系统而存在,它更接近的是一个总体,因为每一个子模块都是为它服务的,尤其是那些业务流程复杂的子模块,例如后续会做出接口设计的自然语言处理、计算机视觉、数据可视化。因此它的存在应该分为三部分设计,即后续的三个小节。但是考试总体仍然存在若干需要设计的接口,例如计时器、选题器等基础模块,考试总接口设计如下:
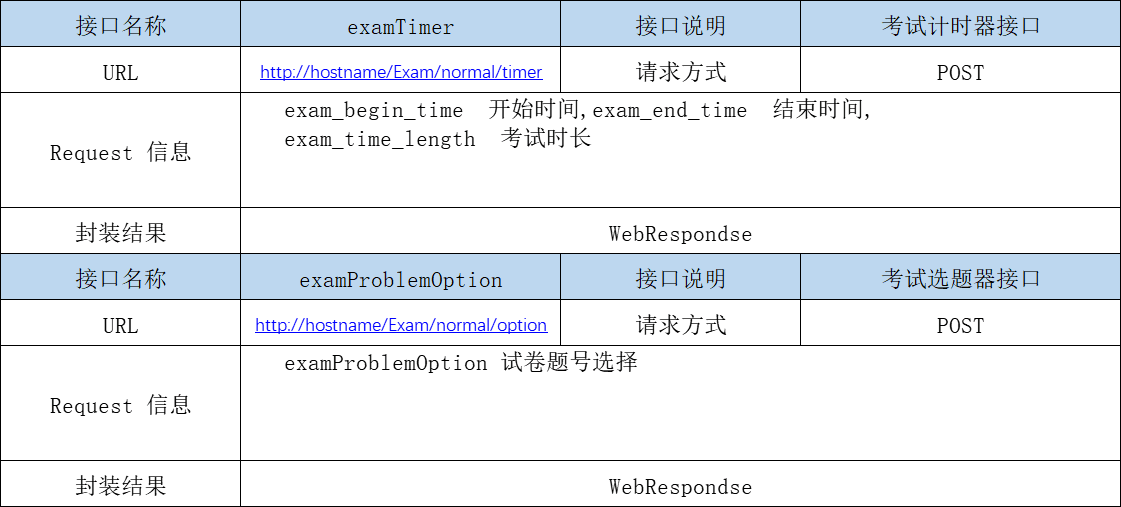
整个基础接口调用如上所示,而子模块的接口调用则更为复杂,我们将会以三个小节来进行讲述。
3.5.2.1 NLP相关接口设计
自然语言处理模块属于处理考试问题中的综合题,由于综合题的处理过程会需要进行词法分析、语法分析,先判断是否符合中文文法,尤其是在进行语文考试的时候,字、词、句的使用就需要更加贴近“风雅颂”,所以如何对答卷结果做出实体抽象就成了一关键所在,但是这问题将会留到详细设计中,我们只是在接口设计这里略微提及,NLP 相关接口设计如下:

3.5.2.2 CV相关接口设计
在 CV module 中存在两种操作,一个是针对人脸图像的识别操作,因此分属于 base module 的 login 功能,另一个则是在考试中的书写题模块,因此存在两个基本接口,如下所示:

3.5.2.3 DV相关接口设计
在 DV module 中存在若干操作,尤其是图像绘制接口的设计,存在条形图、折线图、柱状图、饼图、热力图、三维图像等,因此 DV module 的相关接口设计实际上是可以套用 pyecharts 这类 Python 的第三方库类的相关设计,此处便不再过多赘述。
3.5.4 试卷生成相关接口设计
本小节是试卷生成的相关接口设计,试卷生成会存在若干的设置,比如说索要抽取的题库是哪个、考试试题划分,难易程度的分配情况等相关数据配置,而且由于存在以推荐系统作为推荐产生的智能组卷方案,相关接口就变得更多了,此处不作详细说明,请直接参考 3.5.4.1 的 RS 相关接口设计。
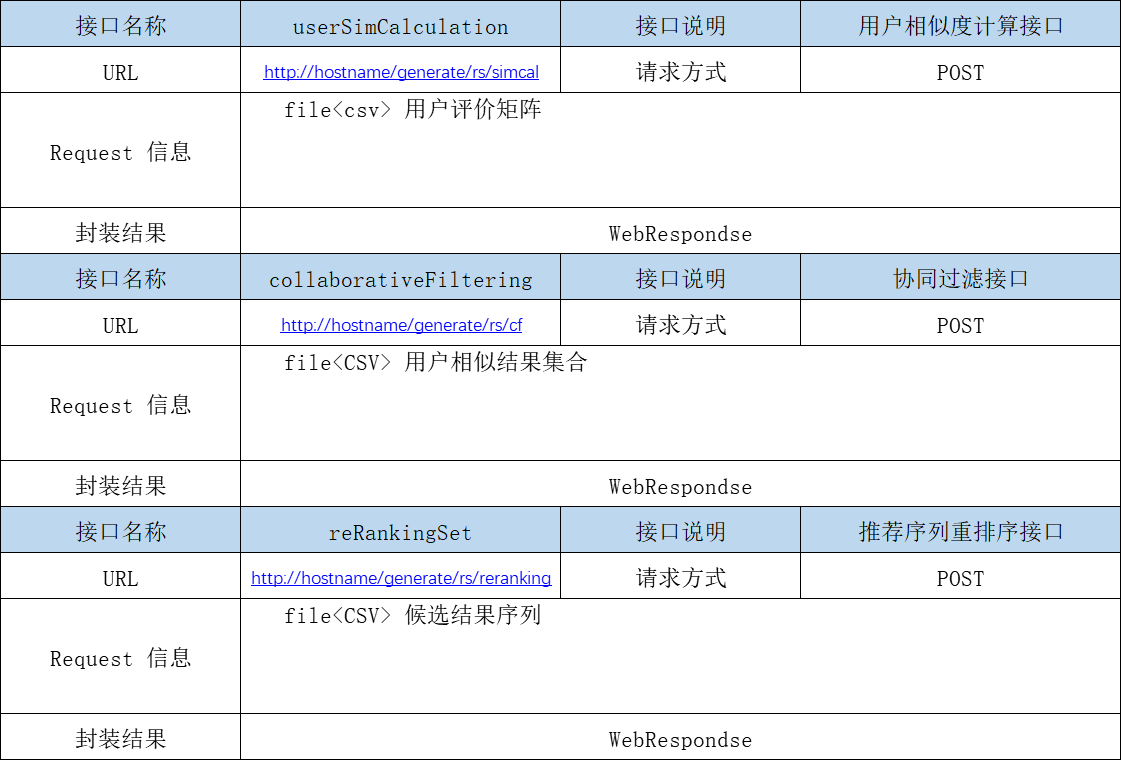
3.5.4.1 RS相关接口设计
本小节是作为智能组卷方案中的推荐系统策略的接口设计章节,RS module 的接口设计如下:
3.5.4.2 Rank相关接口设计
此处为排序接口设计,排序主要是作为多权重排序服务,因此会使用基本的十种排序算法作为相关接口,并且针对其中若干算法提出相应改进,具体改进方案请查看第四章的详细设计,Rank的接口设计不做赘述,至此概要设计完结。
4 系统详细设计与实现
本章节将会详细讲述整个系统的详细流程及其核心算法的设计与实现,总体分为两大块,即算法设计与工程实现。在算法设计上,将会以极大的篇幅讲述 NLP、CV、RS、RANK 这四个子模块的核心算法,从算法流程图、算法伪代码、算法内部设计与基本 Demo 实现开始讲述;在工程实现方面,将会从前端页面设计、网关、后端服务、数据存储四个架构划分进行讲述。
4.1 系统算法设计
本节讲述计算机辅助考试软件的系统算法设计,本系统所使用的算法领域如下:
- 推荐系统
- 协同过滤
- 重排序
- 自然语言处理
- 自动文摘
- 知识图谱
- 计算机视觉
- 图像识别
- 美感评估
- 排序
- 传统排序
- 多权排序
上述八点即本系统所使用到的算法相关领域,接下来对其中的内容做出逐点讲解。
4.1.1 推荐系统
为了解决信息过载这个问题,人们提出了个性化推荐系统以帮助用户在海量的信息世界中获取自己最感兴趣的一部分,考试软件也恰恰能够使用这种方式,去帮助用户依据在考试中的缺漏情况对自己的未来学习方向做出调整。对于推荐系统的历史来源和前沿进展,本节不做过多赘述,本节只讲述与本系统关联最大的一部分,即——如何设计一协同过滤算法以帮助教师用户更好地对学生用户的课业情况做出调整,并完成智能组卷以方便学生自查自纠和帮助教师了解学生情况。
在讲述本系统提出的改进协同过滤算法之前,需要用一定的篇幅来讲解什么是协同过滤。
4.1.1.1 基本推荐策略
在讲述协同过滤之前,我们得先了解基本的推荐策略,即基于内容的推荐策略,然后才是基于协同过滤的推荐策略。
使用基于内容的推荐策略,首先需要计算当前用户喜爱的内容的特征,然后依据这个特征在系统中寻找与之相近的内容,再按照相似度高低推荐给当前用户。
就基于内容的推荐策略而言,其优势是明显的。
- 可以很简单很有效地就将接近用户概貌的内容推送给目标用户,推荐结果直观,容易理解,也不需要有什么领域知识。
- 不需要用户的历史数据。
- 没有关于新产生的推荐对象有任何冷启动的弊端
- 没有稀疏问题,也就是数据不完备问题
- 有很多种业界成熟的分类学习方法为此推荐方案提供支持,例如自动聚类分析、数据挖掘。
但是有好的就有坏的地方。正是因为这种策略基于内容推荐,因此它受限程度非常大,例如所需推荐的对象是多媒体文件,音频或者视频,那么这类多媒体的特征提取就非常不便。
而且又由于用户喜欢的兴趣点不断地被推荐系统所匹配推荐,这就导致了用户只能一直在这个兴趣点内不断被深挖,很难出现新的推荐结果。
之前在优点方面我们提到推荐对象不会出现冷启动的问题,是因为这颗丑恶的毒瘤被踢到用户这边过来了。当出现一个新用户时,除非使用显示获取,否则很难获得用户的兴趣偏好,这是因为不知道要推荐什么给新用户。
目前较为普遍的计算用户描述文件与推荐内容相似度的方法是使用下面这个公式:
其中 可以使用向量夹角余弦代替,这是最简单的代入模式:
4.1.1.2 协同过滤[4]
接着所谓协同过滤,就是它会假设你朋友喜欢的东西,你也喜欢,于是乎推广到推荐系统时,就是把和当前用户最近邻的若干用户的喜欢内容通过一些计算方法得出相似度之后推送给当前用户。目前的协同过滤策略主要有基于用户的协同过滤、基于项目的协同过滤、基于模型的协同过滤。本节也会就这三种传统协同过滤算法做出对应描述。
4.1.1.2.1 基于用户的协同过滤方法
所谓基于用户的协同过滤(UBCF),它的思路蛮清晰的,大体上分为两步走,第一步计算用户之间的相似性得到用户的最近邻;第二步把符合当前用户概貌的内容推送给当前用户。
在第一步的相似性计算中,最简单的方法是计算两者的余弦相似性,形如下式:
也可以计算两者之间的相关相似性,会比较提高些,形如下式:
或者是两者之间的修正余弦函数弦相似性,更改善一些关系内容,形如下式:
当得到当前用户的最近邻时,就可以开始进行第二步,使用下式:
计算推荐得分,把分数高的内容呈现给当前用户。
4.1.1.2.2 基于项目的协同过滤方法
基于项目的协同过滤策略(IBCF),是假设大部分用户对于一些推荐对象的评分很接近,那么就认为当前用户对这些项目的评分也会很接近。比如说有很多用户对某个品牌非常认可,由于从众心理,其他用户也会对这个品牌产生认可,从而选择这个品牌的相关产品。
其基本思路与基于用户的协同过滤模型有些类似,同样是先找到目标用户的最近邻,然后使用当前用户对最近邻的评分,预测到当前用户对目标推荐对象的评分,最后再选择若干得分最高的推荐对象作为结果推送给当前用户。
在这个策略中,第一步查询最近邻的相似性计算函数可以使用在 基于用户的协同过滤策略 中使用的三种相似性函数;第二步产生推荐的得分计算则使用下式:
4.1.1.2.3 基于模型的协同过滤方法
最后是基于模型的协同过滤策略(MBCF)。这种方案相对于前两种的不同之处在于本策略针对用户已有数据应用了统计学与机器学习的方法,计算出一个用户模型,随后对已有数据之外的对象进行预测打分,把得分高的对象推荐给用户。
很显然,建立一个用户模型是这个策略的核心所在。在业界,我们通常是使用机器学习方法或者是统计学上的一些模型方案,去不断地调整处理,最终得到一个较为不错的用户模型。当然除了上述两种方案之外,我们还能够使用基于马尔科夫链模型法、潜层语义分析、语义生成或者是输入选择技术来对用户模型进行创建。
4.1.1.2.4 其他协同过滤算法[5]
- 基于内存的Top-N推荐算法
Top-N推荐,顾名思义是指将待选序列中排名靠前的N个元素推送给当前用户。在这种算法下,可以用两种表现形式,一种是基于用户的Top-N推荐;另一种则是基于项目的Top-N推荐。
1) 基于用户的 Top-N 推荐:
首先我们要采用皮尔森相关系数或者余弦相似度来计算当前用户的邻居集合 U ,这里要注意的是,每一个用户都是一个 N 维向量,N 表示的是当前这个系统中的全部的项目个数;接着有了这个用户邻居集合之后,我们要统计用户邻居集合中出现的项目频率,并且按照从大到小的顺序进行排列;最后我们把这个邻居集合 U 中排列位置靠前的并且没有被当前用户所标注过的 N 个项目(这里的 N 与推荐系统总项目个数 N 不是同一个)推荐给当前用户。
2)基于项目的 Top-N 推荐:[6]
与基于用户的 Top-N 推荐相似,此种推荐策略首先要计算项目相似邻居集合;然后从邻居集合中剔除已经被当前用户标注过的项目;接着把这个过滤完的集合中的每一个项目取出来计算它和当前用户的相似度,然后按照相似度的大小进行排序;最后把排序结果考前的 N (此处 N 的解释同上)个推送给当前用户。
- 基于缺省标注填充的推荐算法[7]
第二种算法是——基于缺省标注填充的推荐。
由于评价矩阵数据稀疏,很多用户之间的共同标注数量太少,这就导致相似度的计算不准确,引发后续的推荐失真。因此我们如果能够在计算用户相似度之前,就使用一些默认值来填充稀疏的评价矩阵,就有可能可以提高推荐精度。
实际上就是为了把评价矩阵的稀疏部分补充起来,使得这个矩阵看上去密集一些,我们都清楚,数据部分越是密集,则计算结果越是趋近真实情况,换句话说就是能够使得最后的推荐预测更加贴合用户所想。
这里一种较为简单的填充方法,就是我们把当前用户的相似用户群,针对该项目所标注的平均值,作为此用户在评价矩阵中对于该缺失值项目的标注值。
- 基于逆用户频率的推荐算法[8]
在每一次进行相似度计算的时候,总有些项目是非常热门的,我们看微博热搜就很清楚了,越是沸点越是爆点的热门项目,它往往是缺乏区分度的,因为每个人都会去看这些属于是社会聚焦的新闻话题,因此在做相似度计算之前,我们要考虑到超级热门话题的区分。因此我们在推荐算法中引入了逆用户频率,其公式表示为:
其中 表示标注过项目 的用户数量, 表示在此系统中的用户总数量。其算法思想其实很简单,无非是在计算用户相似度之前对标注进行一次变换,变换后的标注值是原来标注值与逆用户频率的乘积,这样子可以很好的过滤掉频繁标注对于相似度计算的影响,适当地提高非频繁标注的权重,从而使得整个相似度计算变得更加合理。所谓频繁标注指的就是那些很热门的项目,而非频繁标注则是较为一般的或者说冷门的项目。
在这里,我有一个设想,会不会存在这样一个问题,就是说原本 很小,但是经过一次变换之后, 就又变得很大了,这对于个性化推荐在协同过滤中的使用里,的确会有一小撮人受益,但是可能会导致某些标注的作用被过度放大。
- 基于虚拟值估算的推荐算法[9]
到这里我们已经讲述了三种不同的基于内存的推荐算法,下面要介绍的这种算法,同样也是去尽可能地提高评价矩阵中的数据密度,即改善数据稀疏性。它的具体做法,就是采用虚拟值插补技术对评价矩阵中的缺失标注进行填充,然后根据皮尔森相关系数计算相似度。
目前主要所使用的虚拟值插补技术是基于平均值的虚拟值插补技术。
基于平均值的虚拟插补
使用基于平均值的虚拟插补技术来生成填充在评价矩阵中的伪评分数据,这是一种改善数据稀疏性的可行方法。其主要操作过程是,假定在一个评价矩阵中,用户数量会多于项目数量,此时我们每一个缺失的矩阵值替换为该商品所观察到的平均值。例如下表所示(评分值采用五级积分制):
| - | 项目A | 项目B | 项目C | 项目D |
|---|---|---|---|---|
| 用户1 | 1 | 3 | 5 | |
| 用户2 | 4 | 2 | 2 | |
| 用户3 | 3 | 3 | 5 | |
| 用户4 | 5 | 4 | ||
| 用户5 | 2 | 1 |
接着计算每个项目所观测的评分平均值,使用下式计算:
其中 指的是该项目有多少个用户,例如项目 A 有四个用户给出了评分,那么项目 A 的 值就是 。下表为采用均值插补后的评价矩阵,伪评价数据已加粗。
| - | 项目A | 项目B | 项目C | 项目D |
|---|---|---|---|---|
| 用户1 | 1 | 3 | 5 | 2.67 |
| 用户2 | 4 | 2 | 4 | 2 |
| 用户3 | 3 | 3.33 | 3 | 5 |
| 用户4 | 2.5 | 5 | 4 | 2.67 |
| 用户5 | 2 | 3.33 | 4 | 1 |
尽管使用平均值插补能够改善评价矩阵的稀疏性,但是又产生了新的不可回避的问题——评价数据的分布情况可能会被扭曲,而且方差等相关的统计数据会有所改变,可能有些项目会被降低,而有些项目会被提高。
- 基于加权主用户预测的推荐算法[10]
这种算法一般被采用在解决二值标注的协同过滤问题上,其主要思想是利用评价矩阵中的用户向量,即行向量中相同列的标注的异同对用户的相似度做出不断地修正,并在预测时选择与活跃用户相似度最高的邻居用户的标注作为最终的预测值。
其算法流程如下:
Step1:首先将用户之间的用户相似度设置为1。Step2:判断如果两个用户向量中的某同列标注值相同,则用户相似度乘上(2-γ),反之则乘上 γ ;γ ∈ (0,1)。Step3:随着用户相似度的不断计算,最终将会更新到最后的用户相似度,并选择与活跃用户相似度最高的用户在对应项目上的标注作为预测值。
通过对该算法的分析,可知这种基于加权主用户预测的算法,具有较好的可泛化能力,但是当评价矩阵非常大的时候,由于其计算的复杂度较高,它是不现实的,因此当数据量较小时,可以考虑使用这种方式来处理协同过滤。
- 基于模型的协同过滤算法
与基于内存的 CF 算法一样,基于模型的 CF 算法更新迭代的速度也是非常快的,几乎每天都有新的算法推出,我们所主要讲解的是以下三种。
贝叶斯信念网络可以用一个有向无环图来表示,那么它应该怎样被引进于处理推荐系统中的协同过滤呢?首先我们可以假设类别之间的各个特征是互相独立的,各个特征对不会对自身之外的特征产生影响。然后我们对想要推荐给当前用户的项目使用朴素贝叶斯分类器进行预测,挑选出预测概率最高的类别作为最终的结果,并将之呈现给当前用户。为了防止在计算条件概率时出现概率为 0 的情况,我们将会采用拉普拉斯公式来做平滑处理。
光是简单地讲述算法的基本思想,是令人难以接受的。因此我要引入一个简单的实例来进一步地做出详细阐述。例如当前存在有五种得分类别,分别是 ,有一个评价矩阵如下:
| - | I1 | I2 | I3 | I4 | I5 |
|---|---|---|---|---|---|
| U1 | 3 | 2 | ??? | 5 | 5 |
| U2 | 2 | 1 | 2 | 4 | |
| U3 | 4 | 4 | 3 | 5 | |
| U4 | 4 | 4 | 1 | 2 | |
| U5 | 5 | 1 | 3 |
现在我们要使用基于贝叶斯信念网络的协同过滤算法来求得 I3 的值,首先要提到两公式,如下所示:
朴素贝叶斯分类器的预测公式:
拉普拉斯平滑:
接下来运用 和 式来计算 U1 在 I3 的预测值。
从评价矩阵中可以看出,I3 这一列中有评分的用户是 因此我们要先套用公式 并展开,可以得到:
接着逐一求解,并套用公式 ,得到最终的得分集合,如下所示:
因此,当 时,可以取到最大的预测分数。
接着再按照后续的推荐标准进行推荐即可。
- 基于聚类模型[13]
接着是第二种模型方法,基于聚类模型的协同过滤,这是一种使用较多的模型方法。所谓聚类算法就是计算样本点之间的联系程度,有使用闵科夫斯基距离的,也有使用皮尔森相关系数来衡量的。在前面的算法讲述中,我们不断地提及一个词汇——评价矩阵。评价矩阵中的每个用户行中对于每个项目的值的集合,就可以看作是一个具有 维的数据样本点。
众所周知,聚类算法就是针对数据样本点之间的相似性进行划分,把相似的样本放在一个类中,就好像相似的用户存放在一个相似用户集合中,把不同的数据样本存放在其他的类中。先前我们有提到闵可夫斯基距离,这是在聚类算法中通常用来衡量两数据样本间相似程度的,例如当前有两个数据样本 和 ,我们可以使用如下的公式计算其闵可夫斯基距离:
当 时,就是我们所喜闻乐见的欧氏距离。然后通过式 计算两数据样本间距离可以得到其相似程度,并聚合在同个邻居类中,再展开协同过滤的相关计算即可。
- 基于回归模型[14]
基于回归模型的协同过滤方法是将用户行内标注视作特征向量,通过训练回归模型来预测尚未标注的项目得分,并将高分项目推荐给当前用户。具体做法有很多种,每种方法之间又存在不同的优点,这里主要讲一种保密性较好的方法。
首先我们把每个用户对各个项目的标注视作一特征向量,其中如果存在尚未标注的项目,那么就是用全部标注的平均值作为该尚未标注项目的初始值。假如我使用全部标注的平均值作为缺省值时,从外部很难再去揣测各个项目标注是什么了。接着我们把这个特征向量套到回归模型中去预测这些使用了缺省标注的未知项目标注值是什么。最后再按照推荐标准去向用户推荐这些高分项目即可。
4.1.1.2.5 本系统所提出的协同过滤方法
本系统所提出协同过滤方法,其实有点儿接近基于项目的协同过滤推荐策略。首先我们把整个系统中所存在的题库数据整理成一个评分矩阵,形如下表:
| 用户名 | 项目1 | 项目2 | 项目 | 项目 | ||
|---|---|---|---|---|---|---|
| 学生1 | ||||||
| 学生2 | ||||||
| 学生 | ||||||
| 学生 |
首先对每个项目的正误率、既往出现率、试题完整度、试题难易度等相关属性进行加权计算,得到 ,然后对全体学生用户做用户相似度计算,采用修正余弦函数弦相似性函数进行计算,得到一候选序列,然后对候选序列进行大规模重排序,或采用遗传算法、模拟退火等智能进化算法进行序列寻优操作得到最终的正式试题集合。
4.1.1.2.6 模拟退火[15]
当然我们仍然可以对模拟退火做出一份不太简短的说明:
模拟退火(Simulate Anneal,SA)是由Kirkpatrick S; Gelatt C D; Vecchi M P这三个人在1983年发明的,其论文名称为《Optimization by simulated annealing》,论文在摘要中指出,模拟退火是一种从统计力学的角度类比固体退火的优化算法。详细来说,模拟退火是源于物理热力学的一种全局优化搜索算法,利用物理固体在高温状态下温度的不断下降,使得固体内部的各个分子能量逐渐从高能态往低能态方向下降,当各个分子都处于最低能态时,会重新以一定的结构进行排列,此刻我们视其为最优解的表现。从统计力学的角度来看,分子处于高能态的概率会远远小于分子处于低能态的概率,尤其是当固体温度趋近于绝对零度的时候,每个分子处于低能态的概率将无限趋近于1。模拟退火正是基于上述热力学原理所设计的一种全局随机搜索算法。
SA的设计原理如上所述,其隐射所向,是将一个固体内部的最初分子排布视作最先得到的那个初始解S0,并且给予这一固体充分大的高温,然后将其放置于室温或者是淬火池中,给一个降温的趋势,当然也可以放点冰块,加快降温速度嘛。每当这个固体的温度下降一个固定数值或者是等比例数值时,固体内部的分子排布将会重新整合,形成一个新解,而这个新解通过评价计算之后,与旧解比较,如果比较结果是小于,则新解取代旧解;如果是大于,则会有一定的概率取代新解(这是一种返回较差解序列的方法,后续会详细说明这个概率是如何计算的),重复上述步骤直到温度下降至预定好的阈值,此时可以近似地看作是全局最优解已经取到了。
模拟退火算法的算法流程图如下所示:
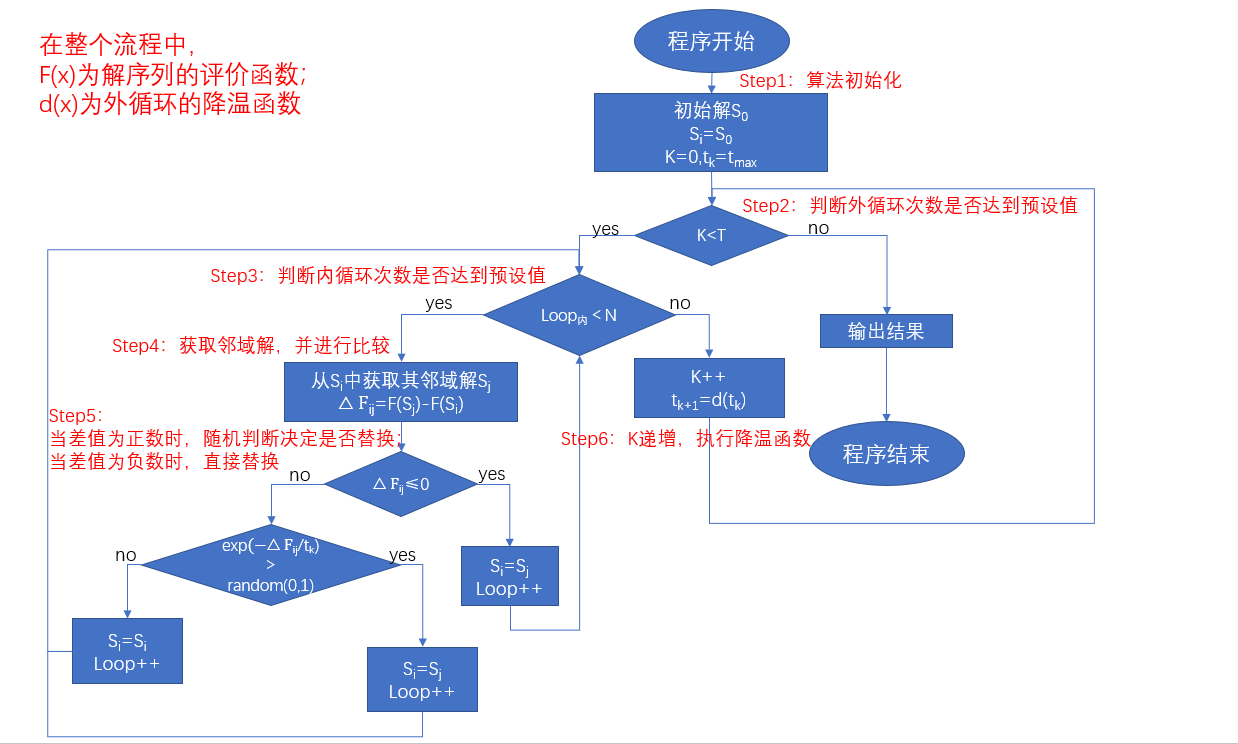
模拟退火算法的核心问题有以下四个方面:初始温度的选取、内循环如何跳出、下降温度的步长设置、算法终止的条件。
初始温度的选取非常重要,因为如果这个温度选的好,那里面的内部分子排列可能会非常棒,这可能会使得程序的运行时间、迭代次数相对减少一些。经过一些前人的研究表明,初始温度要使得每次内循环中的状态判定的概率差不多相等,也就是说要满足:
因此初始温度一般会选择:
其中 是一个非常大的正数, 是一个简单估计量,一般是项目个数。
内循环,实际上是在每经过一次温度下降时的温度区域迭代,仅仅针对当前温度带而言,每一次的内循环,都会产生一次关于当前解序列 的邻域解 ,如果这个邻域解经过评价指标的计算之后,有 ,那么就会替换掉当前解序列;如果说 ,就会有一个随机判断:
倘若随机判断的结果是ture,那么当前解将会替换成现在的这个较差解;反之当前解不变,重复内循环,一直到满足内循环的停止条件为止。
这个随机判断就是模拟退火算法中最为核心的思想,模拟退火也因此被称作是随机搜索算法。这样子做的好处是,使得分子排布以一个平稳的随机概率变成较差的排列顺序,因而不会总是往一个方向不断地下降,然后陷入一个局部最优的凹陷里,如果从图像来看,它会是这个样子的。
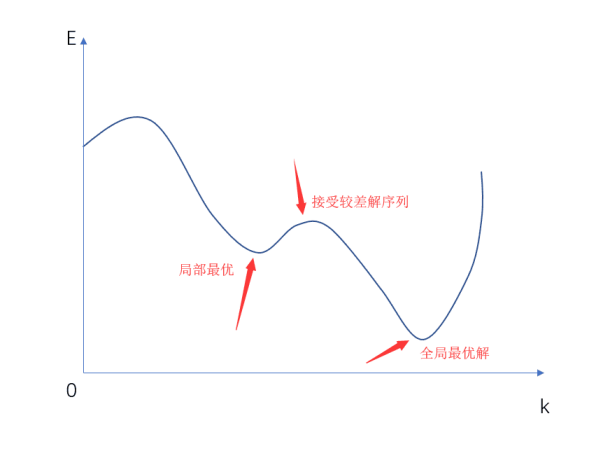
接着是温度下降的步长控制,每经过一次外循环的迭代,固体温度下降,此时就要来考虑下降的每一步长的选取。经过很多科学家的理论研究,尤其是S.Geman和D.Geman,这俩大牛从理论角度上证明了如果在上述内循环的邻域搜索中,解序列变差的的概率呈现波尔曼兹分布时,使用:
能够使得这个模型最后收敛在全局最优解。而H. Szu和R. Hartley则在他们的研究中证明如果解序列变差的概率呈现柯西分布时,使用:
能够使得这个模型最终收敛于全局最优解。
但是在实际应用中,我们很少去采用上述两种明确的已被证明的理论方法,而是采用一些更加直观的、简易的数学计算,比如等比降温或者是等差降温。
最后是外循环的终止条件,我们上面说到当 时,外循环将会终止,算法结束,这里实际上是蕴含了一种终止思路,就是说当温度达到零度时,外循环达到终止条件,结束了。也就是之前我们讲到的零度法,这里的零度法其实有两种度量,一种是摄氏度量法,另一种是绝对零度法(, 是开尔文,热力学单位)。
当然我们也可以使用预设外循环迭代次数作为算法停止的终止条件,这也是被允许的。综上便是模拟退火的详细说明,在本系统中将会被运用在智能组卷功能中。
4.1.1.3 重排序
重排序属于推荐系统在已经得到了候选序列之后,所要进行的一项核心操作,它按照一定的评分准则给予候选序列以排序,尽可能地提高推荐结果的准确度和召回率。对于重排序而言,有三种不同的模式,逐点、逐对、逐列。本系统参考 Alibaba 在 RecSys' 2019 上发表的一篇论文 Personalized Re-ranking for Recommendation[16] 中的重排序策略对智能组卷产生的候选试题集进行得分计算,并以此为依据进行重排序。具体的相关背景以及实验结果请查看原文献,这里我们只借鉴了其算法思想。
4.1.1.3.1 PRM
其个性化重排序模型的网络结构详细设计与它的子模块设计图如下:
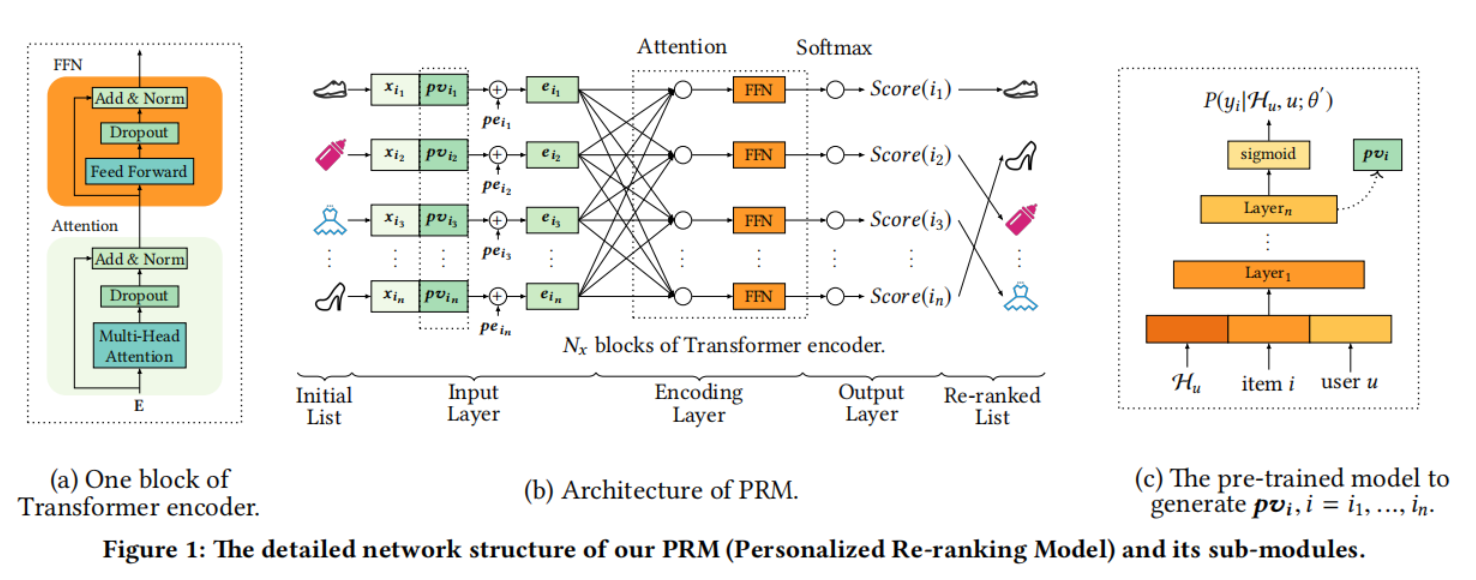
首先划分为三个层次,输入层、编码层、输出层,从一开始最早的是一串初始序列,也称为候选序列,接着候选序列经过处理变换每个项目都会得到一个 。其中 表示的是第 个项目序列中排名第 的项目的特征向量, 表示的是第 个项目序列中排名第 的项目的个性化向量,接着让 加上 得到输入层的最后结果就是 ,其中 是指这个项目的位置嵌入点,然后 则是结果。这个结果将会进入一个转换编码器,也就是进入了编码层。
编码层由注意力模块以及前向反馈网络协同构成。首先在整个输入层阶段所得到的矩阵 将进入多头注意力机制中使用下式 与 进行处理,然后进入一个 Dropout 层,以方便对抗可能带来的过拟合问题,因为在 Dropout 中,网络结构的更新只是部分的、暂时的,是一种神经网络平均化的操作。
在注意力机制模块中处理完毕之后,传递到前向反馈网络模块进行相关计算,之后再进入输出层,在输出层中,我们采用式 (23) 进行最后的得分计算:
接着按得分高低进行排序即可得到重排序后的序列。实际上在该文献所提出的观点中,尽管自注意力机制作为辅助模块,但是它所起到的作用是必不可少的,在 Google 与2017年提出的 Attention Is All You Need[17] 中就详细地提及了自注意力机制的构成,并于2020年的 Synthesizer: Rethinking Self-Attention in Transformer Models 提出了更多对于自注意力的奇思妙想,可能会给当前的重排序工作做出一些启发。
对于自注意力方法的说明我想应该是需要进行一定的阐述,尽管它所占的位置并没有很重要,但是仍然需要对其进行一定的说明。
4.1.1.3.2 自注意力机制
Google 所发表的一篇论文 Attention Is All You Need 拉开了业界对自注意力机制的探索。下图是源自该论文的一张图样:
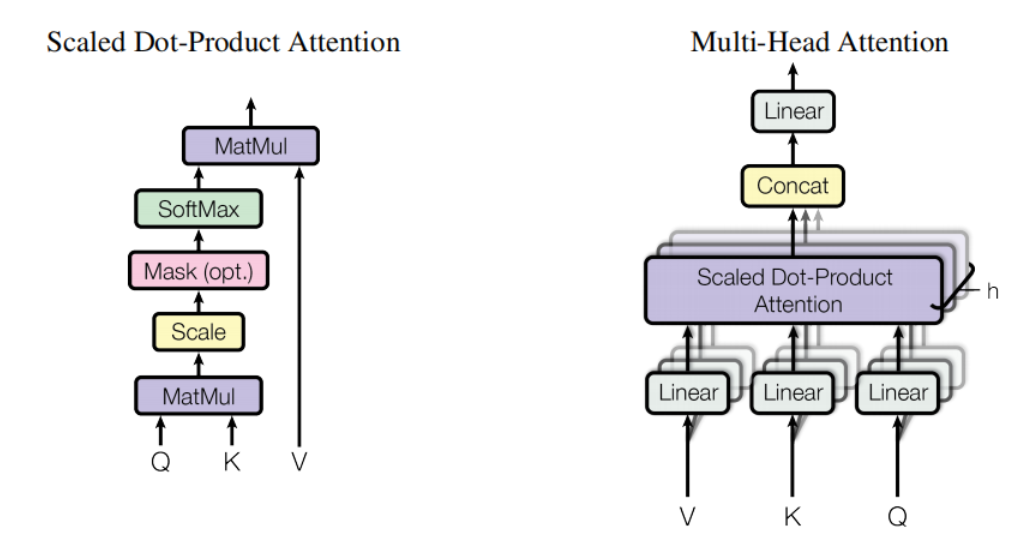
左图所示表示分部点积注意机制的内部构造,而右部则表示多头注意力机制的内部构造,实际上是将 N 组特征向量输入到分部点积注意机制内,然后得到结果之后做一个 Concat 操作,再做线性输出。
4.1.1.3.3 改进的重排序策略
我们在参考 Alibaba 的 PRM 基础上,做出了对应的改进以方便针对教师用户对于学生用户的学业情况摸排。
改进的策略将会从学生正确率高低进行入手,并且选择与错误率超过阈值的相似类型题,主要是以知识点相似、错误率相近、试题难易程度这三方面进行加权计算。
其公式如下,其中 表示知识向量, 表示错误率, 表示难易程度:
由于 为向量,因此对分部得分
接着按照降序排列即可得到最后的重排序列表。
4.1.2 自然语言处理[18]
人类的语言表达主要分为文字与语音这两大类,除此之外还有意会这类的高级表达方式,这里就不对意会做赘述,本子系统主要的处理内容是文字,在对文字内容进行自然语言处理时,可以通过词法分析、句法分析、语义分析、语用语境还有篇章分析等方法进行处理。
在本子系统中,我们采用自动文摘与知识图谱结合的方式共同完成对主观综合题的评估。下述小节将会对自动文摘与知识图谱做出详细阐述。
4.1.2.1 自动文摘
文摘是依据用户需求从源文本中提取最重要的信息内容,生成一个精简版本的过程。文摘应具有压缩性、内容完整性和可读性。文摘可以分为单档文摘和多档文摘。运用计算机自动生成的文摘称之为自动文摘,自动文摘的生成有浅层方法和深层方法。依据生成方法的不同又可以分为机械式文摘和理解式文摘,目前自动文摘的生成多半是采用机械式方法,理解式文摘是建立在对自然语言的理解的基础之上的,难度较大,实现起来还有一定困难。
机械式文摘一般采用机器学习方法来完成,其中分为监督式与非监督式。监督式的机械式文摘,一般将文本内容分为两类——积极的核心语句与消极的修饰语句;非监督式的机械式文摘则是通过文本的语义信息对句子进行打分,选择得分较高的若干句。本子系统采用非监督式的机械式文摘生成方法对学生所撰写的主观综合体题答案进行文摘生成,并比对该题的标准答案,给予相对应的评分计算。
对于非监督式自动文摘算法而言,使用最多的就是聚类分析,目前主流的聚类算法有很多,而常用的是基于划分的聚类算法和层次聚类。基于划分的聚类算法是将初始读入文档中的全部句子划分为 个部分,然后通过迭代进行划分更新,将句子从一个中间类转移到另一个类中,以改进聚类的质量。层次聚类则是对文档内的句子进行层次分解,可以分为自上而下与自底向上两种类型,本子系统所做的自动文摘是基于划分的聚类算法,采用 K-means 算法进行自动文摘生成。对于 K-means 算法而言,我想已不再需要做过多解释,因为它有点儿类似 KNN,即 K 最近邻算法,它们都是采用欧几里得距离进行计算的类别中心的,很简单呐,这个步骤将会在 Natural language process module key code 中提及。此处便就此翻篇。
4.1.2.2 知识图谱
知识图谱是 Google 提出的一种方便高效搜索的新技术,通常由一个三元组 构成,当用户询问一实体资料时,知识图谱通过遍历以该实体为节点的临近节点,得到更为广泛的另一实体信息。下图为知识图谱的技术架构图[19]:
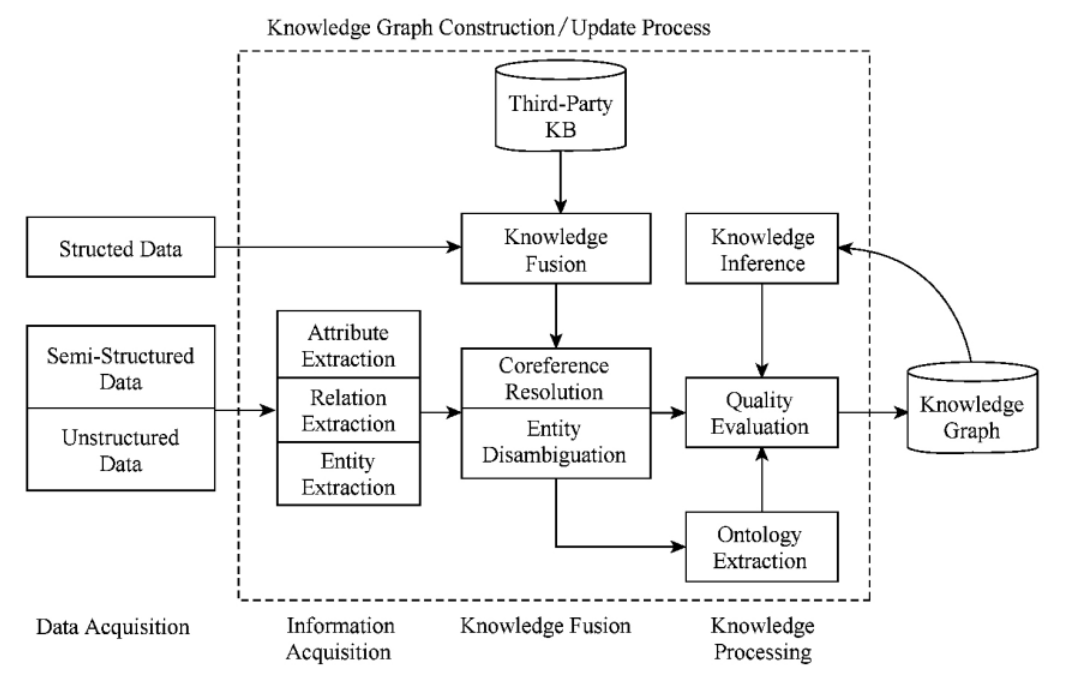
我们能够发现在知识图谱的数据输出层中,半结构化数据和非结构化数据是需要通过关系提取的,而结构化数据则直接进入知识融合模块会同共指消解、实体消歧,然后再做一系列的变换直到成为知识图谱,当然知识图谱也会给予一定的知识反馈,然后再不断的做迭代更新,以达到更好的效果。
//我们将会把自动文摘和知识图谱做一个整合,然后做出一个新的算法以方便对主观综合题的判分中不断地加以变化和改进。
4.1.3 计算机视觉
计算机视觉是指使用计算机设备通过分类或者回归的方式对图像进行标注,目前较为广泛被采用的算法框架有卷积神经网络、深度神经网络或者是模糊神经网络,当然这类神经网络均可以同自注意力机制结合使用。在本子系统中,我们采用卷积神经网络做人脸识别与汉字书写识别及其美感评估。本小节内容分别参考了人脸识别中若干关键问题的研究[20]与基于深度学习的手写汉字识别与美感评分[21]。
4.1.3.1 图像识别
图像识别在本系统中的运用有两个方面,一是人脸识别,二是汉字识别并关联下一节的美感评估,本节将针对这两个识别方向做出详细阐述。
- 人脸识别
在建立人脸识别系统时,因首先考虑原始注册图像,即用户初始导入人脸数据。一般来说,公安系统等检测违法犯罪行为的公职机构所获取的罪犯人脸数据信息一般不是通过罪犯本身主动配合所得到的,而是通过一些其他的摄像手段,例如公共场所的监控设备。但本系统作为一考试软件系统,本身是可以要求用户配合的,并且也存在用户自愿配合的情况,因此用户原始注册图像可以在用户注册时进行采集,或者是直接通过教务处所存放的人脸数据进行录入。对于考试软件系统而言,选取合适的原型图像是非常关键的,对于原始图像而言,存在以下几个关键因素:
1. 原始图像的样本数量
对于一个识别模块而言,其实首先需要建立的就是识别模型,如果存在有较多的已经打好标签的原始人脸图像作为训练集势必能够提高识别模型的识别性能,但是如果识别算法的选择不理想,过多的原始图像数据可能会造成干扰,导致模型出现过拟合的现象,即提高了识别模型的错误识别率。而且原始图像样本的增多,还会时间复杂度与空间复杂度造成一定的影响,最终增加用户的注册时间与交互响应时间,使得系统的友好性与可用性下降,用户的耐心也会受到一定的打击。因此,原型图像的数量一般控制在 3~10 幅左右,这其实也有对系统空间的一定考虑所在,后续在算法选择时会有所提及。
2. 原始图像的样本设置
原始图像的采集应该尽可能地包含多样化的表情、多元化的姿态角度以及不同的摄像距离等单一变量控制,但是需要仍需考虑所选择算法是否包含姿态估计与面部校正能力,否则加入上述控制变化可能会适得其反。
3. 原始图像的样本有效性
对于一个实用的考试软件而言,用户原始注册图像通过全自动化采集,但是很难达到百分百准确的面部特征定位,而且我们也不希望用户通过自身手动操作来修改校正这个费时费力的程序,因此识别系统必须具备有自动得原始注册图像的有效性测试功能。在本考试系统的人脸识别模块中,我们通过计算新进人脸图像到人脸子空间的距离来判断原型图像的有效性。
4. 原始图像的样本差异性
实际上很好去做一个分析,如果同时同角度同光照条件下所连拍得到的原始注册图像必然是极其相似的,那完全可以当作是是两张全等图像进行识别,这对识别模型的提高没有半点儿益处。而且我们的原始图像是通过全自动化采集,如果没有加以控制,那么连拍是必然的,这对识别系统性能的提升毫无意义。因此我们可以采用新进图像与该人脸的其他图像进行匹配,只有超过一定阈值的并且有效的圆形图像才允许加入原始注册图像序列。
对于算法的选择,不能仅仅是停留在识别率的高低、识别速度的快慢,更应该进行综合考量尤其是在对于识别率、系统响应时间、存储空间限制、系统拓展能力等方面进行有机组合式的考量。而且由于是考试软件,操作的主体是学生、教师以及管理员这三类活体用户,因此进行活体判别是必不可少的,对于活体判别而言,有眨眼判别、嘴部张合判别以及视差分析方法。
整个的人脸登陆框架如下图所示:
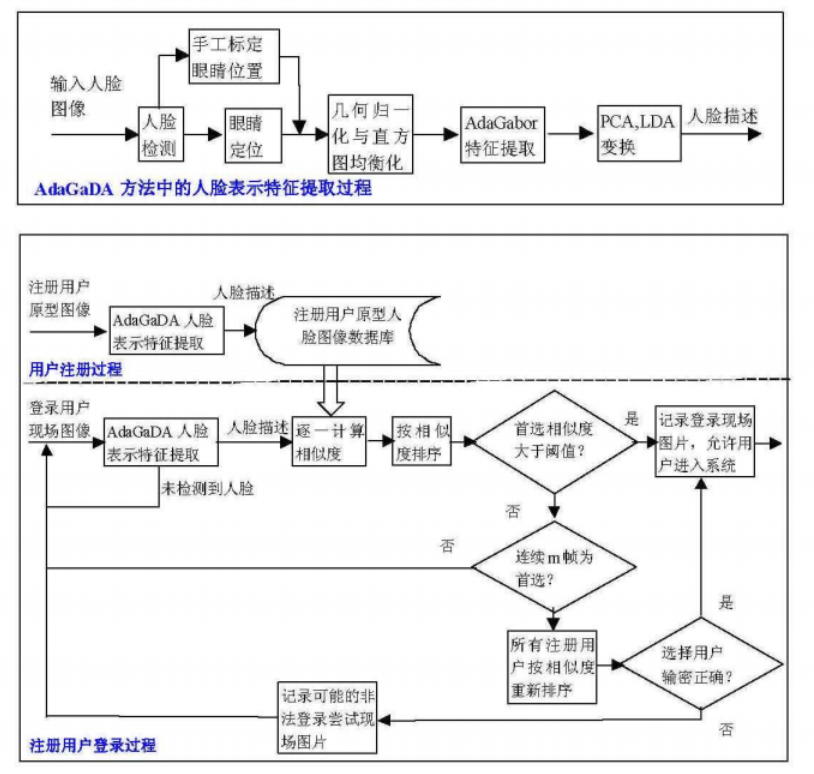
首先采用 AdaGaDA 方法进行人脸特征提取,然后进入到用户注册过程,这一步在本考试软件系统中可以选择略过,因此教务处的人脸信息是存在更新的,能够进行相应的导入。然后当用户使用人脸识别进行登录时,首先系统获取相机权限录入登录用户的现场图像,然后通过 AdaGaDA 进行人脸特征提取得到人脸描述之后同原型数据库内的注册图像进行相似度计算,并按相似度进行排序,当首选相似度大于阈值时,并且用户信息核实方可记录下现场图片,并允许进入系统,否则应进行多次连续拍摄继续计算相似度,超过额定拍摄次数仍无建树,则应提醒用户采用传统的用户名+密码的方式进行登录,如果密码错误则记录非法现场图片,反之则允许登入。
- 汉字识别
汉字识别有两种识别方案,一个是分类,另一个是回归,本汉字识别系统采用分类的方式来进行汉字识别,首先招募一批志愿者,人数大致为三十人左右,让他们认真地写出一百个不同的汉字,并对其进行盲审评估,将这三千个汉字样本划分为五个不同的等级——甲乙丙丁戊。接着采用卷积神经网络对这三千个汉字进行特征训练,以获取预训练模型,方便后续使用。
接着当学生用户上传该书写试题包时,将图片内容挨个输入到预训练模型中以进行特征提取,然后从先前我们所准备好的三千个汉字样本中取出相同字的 N 个不同等级的样本图像,计算其卷积神经网络的特征距离,对这 N 个距离通过 softmax 函数计算出样本的概率值,然后求这 N 个样本的期望——即该学生用户所撰写的汉字书写的美感分数,具体的流程图将在下一节的美感评估中体现。
4.1.3.2 美感评估
本模块的美感评估策略如同上述所示,参考了基于深度学习的手写汉字识别与美感评分,其算法流程如下:
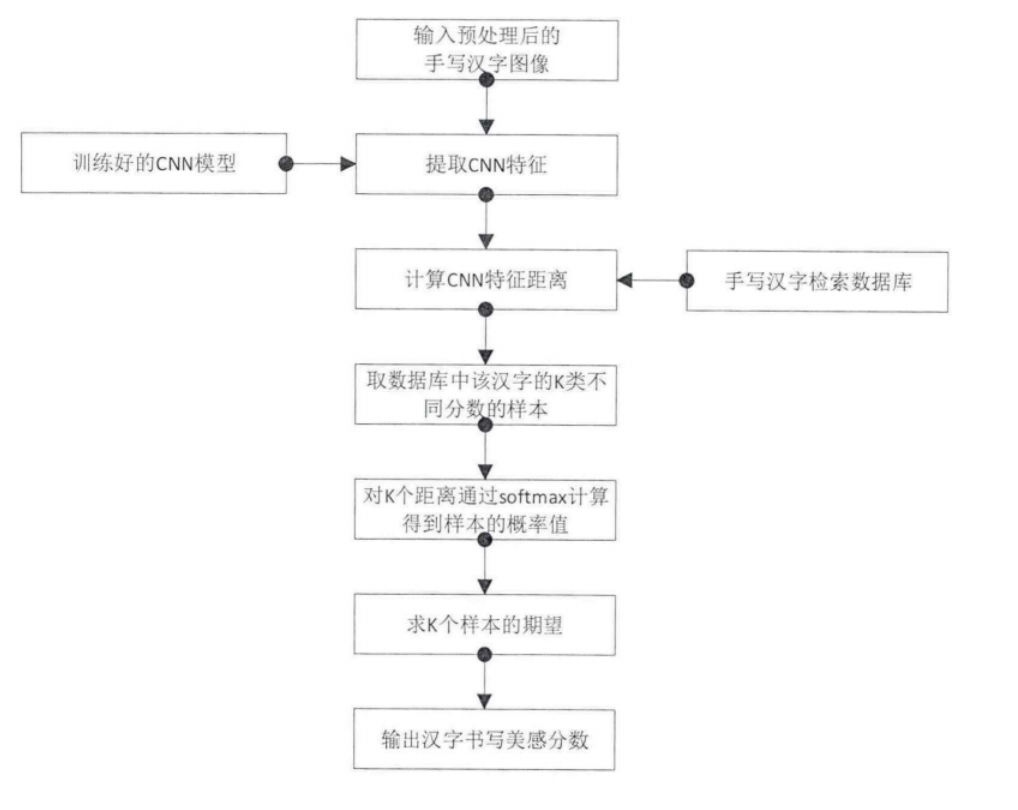
其中汉字相似度计算采用余弦相似度进行计算:
其中, 表示手写汉字特征向量。但是不同汉字之间的相似分数是参差不齐的,比如说"一"和"壹",明明是表示同一个意思,但是它们之间的相似度就非常低,因此我们应该尽可能地选择相同汉字来进行相似度计算。例如说取出 N 个,然后对这 N 个样本做距离计算,并将距离置为负数,然后通过 softmax 计算得到概率值,如下式所示:
最后计算这 N 个样本的期望值,四舍五入得到待测汉字的美感得分:
其中 表示对余弦相似度的结果取负值, 是表示第 个类别的美感分数,例如甲类为 90 分, 表示四舍五入函数。
4.1.4 排序
排序总是一件令人感觉心旷神怡的事情,尤其是在对于一串无序的序列进行有序化排序的可视化过程,看起来是多么的和谐。本子系统模块采用十种不同的排序策略对无序序列进行有序排列,分别是直接插入排序、折半插入排序、起泡排序、直接选择排序、快速排序、希尔排序、归并排序、堆排序、基数排序以及外部排序,并且需要帮助推荐系统模块实现重排序。
4.1.4.1 传统排序
在传统排序模块中,主要是针对爬虫所导入的内容进行排序,而且有时候需要处理海量数据,因此可以选择不同的排序算法进行组合排序。其中关键代码演示将在第五章核心模块编码演示中进行展示说明。
4.1.4.2 多权排序
多权排序是指对某个序列进行多维度权重分配排序,举个例子,如下表所示:
| 用户姓名 | 语文成绩 | 数学成绩 | 英文成绩 |
|---|---|---|---|
| 张小明 | 78 | 99 | 60 |
| 李小飞 | 85 | 70 | 95 |
| 陈小东 | 80 | 80 | 80 |
接着我们对各科成绩做出权重分配,例如:语文学科占比30%,数学学科占比40%,英文学科占比30%,共计100%。然后对其进行加权计算,得到总体得分,并进行名次排序,如下表所示:
| 用户姓名 | 加权得分 | 排名 |
|---|---|---|
| 李小飞 | 82 | 1 |
| 张小明 | 81 | 2 |
| 陈小东 | 80 | 3 |
可用下式表示:
其中 表示第 门学科的成绩, 则表示第 门学科的对应权重,累加即为最终加权得分,上述是本排序模块的多权排序方案。
4.2 系统工程实现
工程实现之前对项目设计的一些思考。
我今天撰写项目设计文档的时候,思考了一个小问题,就是如何设计好一个网站的界面,我思考了半个小时,在网上冲浪的时候也翻看查阅了一些相关网站,我在思考关于“考试”这个话题能够有什么精彩绝伦的点子出现,我带着这个疑问向离我最近的那个人询问,她说:“会一下子想到‘腾讯课堂’。”我让她再好好想一下,她说,“我想起2018年的那场高考,我进门的时候,抬眼看见一个长得好帅的男孩子,很巧那场语文考试我坐在他的斜对面,就一直盯着他看,试卷掉了三次,他帮我捡了三次,还被老师误认为是要作弊哈哈哈哈哈哈。”
我听着她的描述,脑子里荡出一个画面,那是青春的校园,少女们背着书包,走进明亮教室的一瞬间,惊奇地发现有个慵懒少年刚好抬起眼和她们四目相对,金色的阳光不加修饰地照在他的身上,他嘴角扬起一抹极其甜蜜的笑意:“你们来啦!快进来一起考试吧!”我突然爱上这样子的画面,清爽、阳光、富有活力。
再后来,我想到我的用户群体是一群 19~23 岁的青年,其中女性居多,因此采用日漫美男子的画风是最容易引起她们的关注,于是……
本考试系统最初仅仅是面向文学院的师生用户,但我认为它的未来绝不止步于此。由于用户存在性别,要么男性要么女性,而且年龄层次普遍位于 19~23 周岁之间,因此我们将采用青春明亮的风格作为用户欢迎界面,并且针对不同性别会有对应的异性 NPC 存在,开场欢迎页面如下图所示:
4.2.1 界面设计
当师生用户通过欢迎页面点击登录注册时,会出现下图这样的登录注册弹窗:

当我们登录成功之后,整个画面会从中间裂开,然后向两边展开,接着用户选项卡会从侧边拉出形成一个左侧边栏,当用户点击其中某一功能时,该功能按钮会下陷,如同“用户中心”所展示的那样,并且右侧会出现若干如下图所示:
当学生用户开始使用“考试管理”时,意味着能够进入其中展开考试,因此我们的考试界面如下:

整个考试界面设计一改前面的红白撞色,直接上满屏深黑,让人更有精神感、冷静感,沉浸在缜密考试的环境中能够更好的呈现出一份完美的答卷。
余下的界面设计仍处于开发状态或保密状态不宜公开,敬请期待。
5 核心模块编码演示
本章专门讲述核心模块的关键编码,并对其中核心代码行做出相关注解。
5.1 Recommender System Key Code Demo
本小节讲述推荐系统的相关编码,尤其是一些关键函数编码,特别是在本系统中所用的协同过滤算法,本小节将会以注释的方式,进行关键代码分析。
5.1.1 Collaborative filtering
//Collaborative filtering key code
5.1.2 Simulated annealing
模拟退火核心过程:
while(K<T) {while(Loop<N) {copy(Snbr,this.S);//将当前解复制一份,为后续获取邻域解做准备reverse(Snbr);//执行一次逆转,获取邻域解edif=eva(Snbr)-eva(this.S);//eva表示评价函数if(edif<=0) {Loop++;copy(this.S,Snbr);this.e=eva(Snbr);//让这个邻域解的评价值取代旧解,并且把终止序列也一并取代}else {if(Math.exp(0-(edif/tem))>Math.random()) {count++;Loop++;copy(this.S,Snbr);this.e=eva(Snbr);}else {Loop++;copy(this.S,this.S);this.e=eva(this.S);}}}K++;tem=q*tem;//等比例降温,有需要时,此温度能作为跳出外循环的控制条件}
邻域解的求序过程:
public int[] reverse(int[]s) {int p=(int)(Math.random()*this.lengths);//int q=(int)(Math.random()*this.lengths);if(p>q) {int t=p;p=q;q=t;}for(int i=p,j=q;i<j;i++,j--) {int t=s[i];s[i]=s[j];s[j]=t;}return s;}
评价函数的关键代码:
while(index<this.lengths) {nextPoint=S[index];nextPointIndex=nextPoint-1;if(nowPoint==0) {sum=sum+this.center[nextPointIndex];nowPoint=nextPoint;nowPointIndex=nextPointIndex;index++;}else {sum=sum+this.dencetens[nowPointIndex][nextPointIndex];nowPoint=nextPoint;nowPointIndex=nextPointIndex;index++;}}
5.2 Natural Language Process Key Code Demo
5.3 Computer Vision Key Code Demo
5.4 Rank Algorithms Key Code Demo
5.5 Crawler Key Code Demo
6 测试
系统测试是使用相应的测试工具,把每个模块结合起来,并处于一定压力下对系统运作效果的测试,其中包括了功能测试和性能测试,软件系统只有通过一系列的压力测试后,才能投入使用[22]。
6.1 系统测试计划
进行系统测试之前,得先规定好测试计划,计划得规定好系统瑕疵定义,并且根据瑕疵程度划分级别;还需要规定性能指标,保证系统运行性能在用户可接受的程度之内;最后要规定测试内容的通过程度。
1.系统瑕疵定义:
- 级别 1 :勉强允许,比如说用户友好度不行、功能布局不合理、没有统一好界面文字、色彩搭配不够突出等。
- 级别 2 :一般允许,主要是说系统容易使用程度不够。比如用户界面有个 motto 框,这个地方没有给长度限制导致超出边界,或者是用户信息没有提示必填项目,导致后续出错又一直提醒等。
- 级别 3 :不允许,会影响到系统基本的功能使用。比如说数据显示不良、功能操作流程可跳跃等。
- 级别 4 :绝对不允许,系统存在有些正常功能无法使用,存在严重 BUG,比如死循环、数据库发生严重错误、严重的计算错误等。
2.系统性能指标定义
- 普通接口操作,系统响应时间不超过 0.5 秒
- 特别接口操作,系统响应时间不超过 30 秒
- 并发 200 以内系统响应时间不超过 3 秒
- 并发 1000 以内系统响应时间不超过 30 秒
3.测试用例通过率
应当严格按照计划规定,每个子模块按照其内部功能划分,设计全面多样的测试用例进行测试,测试用例规定测试输入内容,验证测试输出内容,并且测试用例的通过率不能少于 95%。
6.2 系统业务功能测试
尚未展开
6.3 系统性能测试
尚未展开
7 总结
终于是来到了最后这一章节。本章是对本软件的预研过程、开发过程以及整个最后文档的编辑总结,对计算机辅助考试软件的项目优势进行分析,并对接下来的后续工作提出期望,以使得将来变得更好。
7.1 全文总结
从第一章开始,我们进行了可行性分析,介绍了考试软件对于当前业界会产生一系列怎样的影响,并对于业务背景做出详细地阐述。然后我们分析计算机辅助考试软件的系统规模及其目标之后,展开对相关系统的详细地调查与研究,最后发现几乎所有市面上的软件系统都无法解决主观综合题的自动化处理,因此在本文所设计与实现的计算机辅助考试软件系统恰恰就把这个难点,通过自然语言处理技术中的自动文摘生成结合知识图谱的三元关系取得自动化处理的解决方案。在模型设计上,我们用六个不同的模块架构起整个软件系统的详细模型式样,详见第一章中的系统逻辑模型。在系统开发的过程中,我们制定好系统开发计划及其 UML 流程图,对系统开发进度做出详细地规划与分析,并给出具体的实现时间段。同时采用 IFPUG 功能点分析法对系统的代码规模做出估算,大约需要五万行左右,但是实际上会超过五万行,因为仅对于当前而言,无法做出详细的功能判断,仅仅只能是给出当前所考虑到的功能。最后我们还介绍系统软件开发的解决方案,即分工如何、实现的工具是什么等。
第二章则是需求分析,简要提及了需求分析的目的、过程及其原理,主要提及了产品特征与用户特征的相关分析,接着从功能需求分析与非功能需求分析两方面入手展开讲述。功能需求分析把系统看作是对于用户的一个接口机器,把系统整体解剖为三个用户群体:学生、教师、管理员,并从这三者的行为、需要进行分析。非功能需求分析则是对系统的流畅程度、精美程度等方面提出指导性意见。
第三章是系统软件的概貌设计,即整体设计。从设计目标、设计概貌、软件系统的技术架构三方面入手,详略得当地描绘了整个软件基本概貌。然后从数据库设计与接口设计两方面对本系统进行一定地描述,尽管每个数据库表单的特征维度很大,但是大且详细是我们做软件开发所必须考虑的问题。在接口设计中,我们以图表的形式对软件接口做出指导设计。
第四章是系统软件的详细设计,分为算法设计与界面设计。在算法设计中,我们从四个不同的模块进行入手,对其中的推荐系统模块、自然语言处理模块、计算机视觉模块、排序模块进行原理讲述,然后提出四个不同的改进算法,分别是对协同过滤、重排序、自动文摘与知识图谱相结合、美感评估这四个方向的算法提及。
第五章是系统软件的关键编码设计,主要是五个模块的编码设计,即本系统除去基础模块之外的其他模块的关键编码。
第六章则是系统软件的测试计划,主要是对于测试计划的定制、系统功能测试与系统性能测试。
通过本系统的开发与文档撰写,我们收获了大量的前沿知识,强化了自身的工程能力,对于一些技术栈的综合学习与使用得到了升华。并且收获了一个虽然不完美但是全心全意去实现的系统软件,我爱它,满心欢喜。
8 参考文献
[1] 宁静峰,童旅杨. 软件项目功能点估算[J].长春工业大学学报(自然科学版),2014,35(03):309-314. ↩
[2] 曹烨. 基于遗传算法的智能组卷在线考试系统设计与实现[D].中国科学院大学(工程管理与信息技术学院),2014. ↩
[3] 郭素蓉. 学校通用考试系统的设计与实现[D].电子科技大学,2007. ↩
[4] 王国霞,刘贺平. 个性化推荐系统综述[J].计算机工程与应用,2012,48(07):66-76. ↩
[5] 刘青文. 基于协同过滤的推荐算法研究[D].中国科学技术大学,2013. ↩
[6] Mukund Deshpande and George Karypis. 2004. Item-based top-N recommendation algorithms. ACM Trans. Inf. Syst. 22, 1 (January 2004), 143–177. DOI:https://doi.org/10.1145/963770.963776 ↩
[7] Chee S.H.S., Han J., Wang K. (2001) RecTree: An Efficient Collaborative Filtering Method. In: Kambayashi Y., Winiwarter W., Arikawa M. (eds) Data Warehousing and Knowledge Discovery. DaWaK 2001. Lecture Notes in Computer Science, vol 2114. Springer, Berlin, Heidelberg ↩
[8] Salton G,McGill M J. Introduction to modern information retrieval. 1986.. ↩
[9] Su X, Khoshgoftaar T M, Greiner R A mixture imputation-boosted collaborative flter. Proceedings of the 21th Intermational Florida Artificial Intelligence Research Society Conference (FLAIRS' 08), 2008. 312 -317. ↩
[10] Nakamura A. Abe N. Collaborative fltering using weighted majority prediction algorithms. Proceedings of the Fifteenth International Conference on Machine Learning, 1998. 395- 403. ↩
[11] Miyahara K, Pazzani M J. Collaborative filtering with the simple Bayesian classifier. Proceedings of PRICAI 2000 Topics in Artificial Intelligence. Springer, 2000: 679 -689. ↩
[12] Shen B, Su X, Greiner R, et al. Discriminative parameter learning of general Bayesian network classifiers. Proceedings of 15th IEEE International Conference on Tools with Artificial Intelligence, 2003. IEEE, 2003. 296 -305. ↩
[13] Chee S H S, Han J, Wang K. Rectree: An efficient collaborative filtering method. Proceedings of Data Ware-housing and Knowledge Discovery. Springe, 2001: 141-151. ↩
[14] Vucetic s, Obradovic Z. Collaborative filtering using a regression-based approach. Knowledge and Information Systems, 2005, 7(1):1-22. ↩
[15] 蔡延光,钱积新,孙优贤.多重运输调度问题的模拟退火算法[J]. 系统工程理论与实践,1998(10):12-16+38. ↩
[16] Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, Junfeng Ge, Wenwu Ou, and Dan Pei. 2019. Personalized re-ranking for recommendation. In Proceedings of the 13th ACM Conference on Recommender Systems (RecSys ’19). Association for Computing Machinery, New York, NY, USA, 3–11.DOI:https://doi.org/10.1145/3298689.3347000 ↩
[17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N Gomez, Lukasz Kaiser, and Ilia Polosukhin. 2017. Attention is all
you need. In Advances in Neural Information Processing Systems.5998- -6008. ↩
[18] Foundations of Statistical Natural Language Processing by Manning C.D., Schütze H. ↩
[19] 刘峤,李杨,段宏,刘瑶,秦志光. 知识图谱构建技术综述[J].计算机研究与发展,2016,53(03):582-600. ↩
[20] 山世光. 人脸识别中若干关键问题的研究[D].中国科学院研究生院(计算技术研究所),2004. ↩
[21] 庄子明. 基于深度学习的手写汉字识别与美感评分[D].北京邮电大学,2019. ↩
[22] 冯尧. 仓储管理系统设计与实现[D].北京交通大学,2019. ↩
