@yinzhi6367
2015-03-12T03:30:28.000000Z
字数 18192
阅读 6952
Model Thinking 模型思维 1/6
Coursera
零、为什么要使用模型
1. Use and Understanding Data
One to Many and Many to One
- Understand Patterns 理解模式
- Predict Points 预测点(如均衡点)
- Retrodict 倒推(评估有效性)
- Predict Other Outcomes 预测其它数据
- Inform Data Collection 组织数据
- Estimate Hidden Parameters 参数
- Calibrate 校准
模型能够帮助我们更好地组织信息:信息 → 模型 → 决策
聪明人采用模型,但模型不告诉他们怎么做。
2. Use Modle
(1) 确定问题
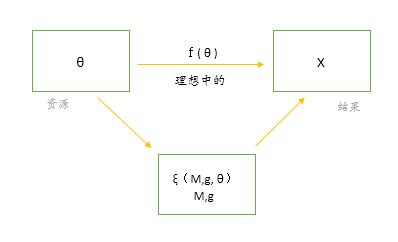
(2) 确定相关变量( 关键字、元素 )
| R1 | R2 | R3 | R4 |
|---|---|---|---|
(3) 变量间的关系
3. 模型的结果类型
- Equilibrium 均衡
- Cycle 周期性
- Random 随机
- Complex 复杂
模型思维能够让我们更好的 Understand Patterns(理解想法)
Produce:
① Points 时间
② Bounds 边界
我们可以用 Model 来 Retrodict(追溯)或 Predict(预测)
4. 模型的作用:
(1) Real Time Decison 即时决定
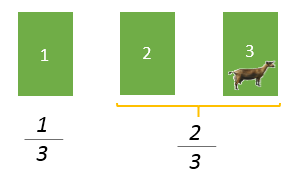
我选择了 ①,它中奖的概率是 1/3 ,把 ② 和 ③ 作为一个整体,中奖的概率是 2/3,第二次选择并非选择了②,而是选择了②、③,只是③已被告知是羊。
(2) Comparative Statics 静态分析
(3) Counterfactuals 反事实
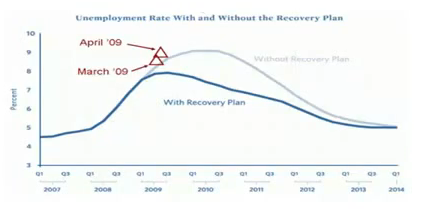
做 / 不做 => 结果区别
现实只能运行一次,我们可以通过模型来多次运行,得到不同的结果
(4) Identify and Rank Levers 识别和分级
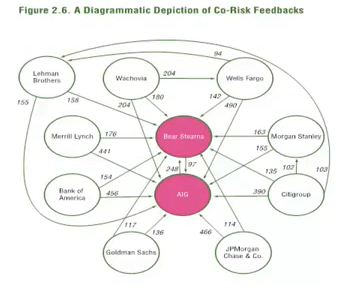
(5) Experimental Design 实验设计
(6) Institutional Design 制度设计
(7) Help Choose Among Poticies and Institutions
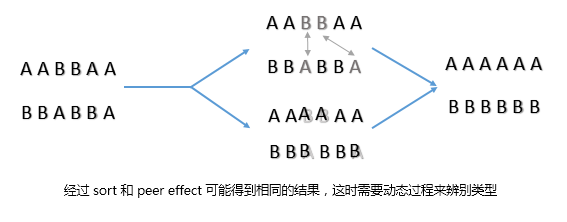
一、 Sorting and Peer Effects 分类和同群效应
1. Schelling's Segregation Model 谢林的隔离模型
衡量隔离度指数

隔离度指数 = (|5/50 - 5/30|*2 + |10/30 - 0|*2 + |10/50 - 0|*4)/2 = 0.8
人们更喜欢与那些和自己外形、行为和价值观相似的人生活和交流,然而 Micromotives ≠ Macrobehavior
- 微观上的动机不一定等同于宏观上的表现
- The tail is gonna wag the dog.
当人群有较低的阈值时,集体运动将更有可能发生;如果人们的阈值差异较大,有更多的人分布在末端,则集体运动更容易发生。
你不仅需要平均值,数据的分布、数据关系同样重要。
2. Standing Ovation Model 起立鼓掌模型
代理(Agents) → 行为(rules) → 聚合/现象(Aggregation)
紫帽子
0
1
2
2
2
Threshold: T
Quality: Q
Error/Diversity: E (误差/差异)
signal: S = Q + E > T
signal2: > 15%
在阈值的基础上,考虑了“噪音”(E)
二、Aggregation 聚合
1. Central Limit Theorem 中心极限定理
- 从抛硬币开始
P=12
Mean=N2
S.D.=N√2
Binomial Distribution 二项分布
Mean=pN
S.D.=p(1−p)N−−−−−−−−√
* 需要注意的是,N次事件均独立,有独立性才有正态性
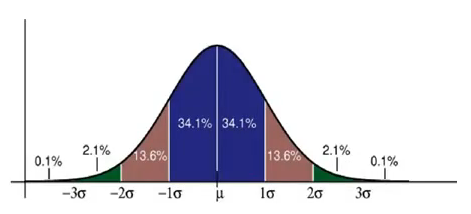
2. 六西格玛
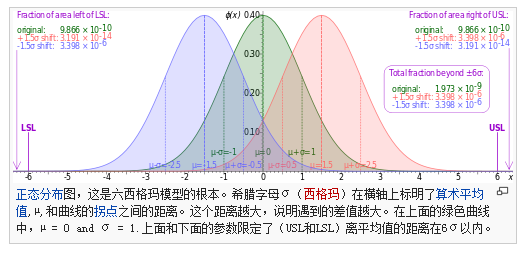
如图, ± 6σ 包含了99.99966%的范围,代表在纯数学意义上的 DPMO [1]是0.00034%,现实中表示通过对各方面的改进不断优化追求达到的一个完美目标。
σ 表示不同产品之间特定参数的离散程度(如零件尺寸的离散程度),也代表产品的一致性(只讲究一致性是没有意义的,可能是性能一致合格品,也可能是性能一致的不合格品)。
“有几个 σ ”这种语言表述一般用于描述质量控制能力,是一个综合过程的结果,不是一个单一指标,深入了解见 wiki-六西格玛
[1] DPMO(Defects per million opportunities)百万次错误率
3. Game of Life 生命游戏
规则:
1. 每个细胞有八个相邻细胞
2. 若一个细胞有且仅有3个相邻黑细胞,它会变成黑细胞
3. 若一个细胞有有2-3个相邻黑细胞,保持黑色;2个以下或4个以上相邻黑细胞,变成白色。
如下图 Netlogo-Life,一个简单的两个3×3组成的图案,经过上面规则可以形成复杂漂亮的图案:

简单图案加上简单规则构成了8种图案,循环往复

一个同样简单的初始图案也可以演绎出异常复杂的图案(在这个图案的变化过程中,可以看到类似动物毛皮的圆点)

简单图案加上简单规则,也可以形成一个自动运动的图案,课程里老师还给出了能发射图案的图案。

当遵循着简单规则的简单图像聚合在一起时,可以形成非常复杂的图像
1. 自组织模型
2. 浮现
简单的东西,经过简单的规则可以实现复杂的功能.
银之个人理解,自组织指简单的东西经过简单规则组成复杂的东西;浮现则是简单的东西,经过简单规则,实现了复杂功能
4. Cellular Automata 细胞自动机
细胞自动机可以看作一维线性模型,单个细胞有开、闭两种状态,状态由相邻的两个细胞决定。
这样单个细胞和相邻两个细胞构成了23个状态,这8个状态又可以分别设置 开/闭 状态,构成 28 即256种可能结果。
[1] 把8个状态用 1、2、4、8、16、32、64、128 编号,编号加起来作为规则编号,每个规则可以得到 0 ~ 255 之间的唯一编号。
下图为单个细胞 Rule30 下前3次运行
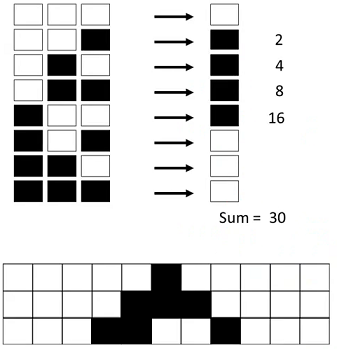
Netlogo- CA ID Rule 30 画一条垂直线,会发现是随机序列

Rule 110 形成了类似植物茎部的图样


织锦芋螺(Conus textile)的花纹神似Rule 30的结果
Rule 110 多个随机起始细胞形成的图案
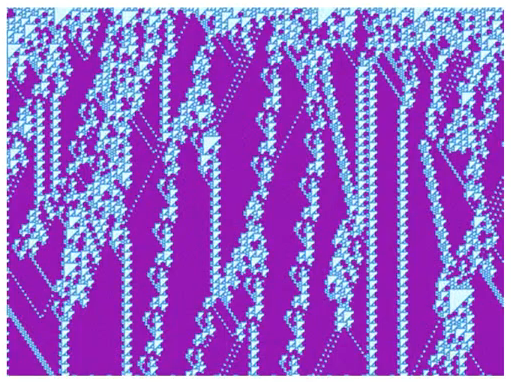
结果可以是趋于均衡的,模式化的,复杂的,陷入混沌的
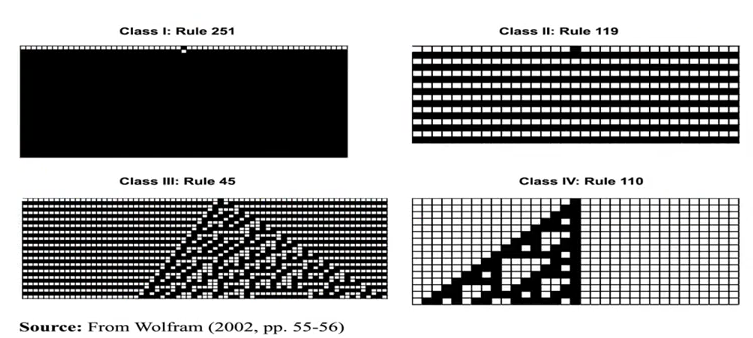
Langton's λ
郎顿只看结果有多少个“开”,用开的比例 Lmbda(0/8~8/8)归纳出下表:
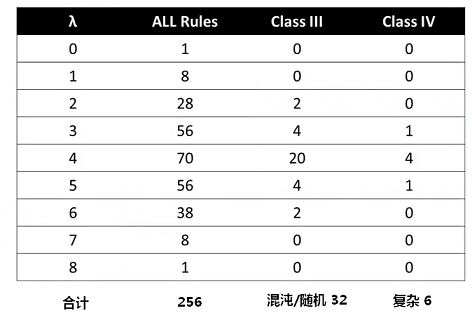
从上图可以看到,复杂的模式里通常有大量的依存关系,或者说大量的依存关系可以形成复杂的模式。
- Simple rules combine to form anything
- "it from bit"
所有的东西都从简单规则中来,我们在现实世界中所接触的复杂事物,都来自非常简单的二值的相互作用。
万物源于比特(It from bit),换言之,每一个“它”,每一个粒子,每种力场,乃至时空的连续性本身,在衍化出其功能,其含义,乃至其存在时,甚至间接的在某些场合下,都归结为简单的“是”或“否”的问题,归结到二元选择,归结到比特。“万物源于比特”象征着物理世界中所有物体在绝大多数情况下,其最本质的东西都来自于非物质的解释,也即我们所说的现实是从最刨根问底的“是”或“不是”的问题中,以及最机械的回答中浮现出来的。简言之,所有物理存在在本源上都是信息论的,这是一个参与的宇宙(participatory universe)。
—— 约翰・惠勒(John Wheeler)1990 - Complexity and randomness require interdependency 为了产生复杂性和随机性我们需要某种程度的相互依存性
5. Preference Aggregation 偏好聚合
一个简单的规则可能创造了一个复杂的现象,偏好或其它结构聚合时会有一种特殊的属性:聚合的部分所具有的某些性质,可能是聚合结果所没有的。 **Condorcet Paradox 孔多塞勃论:** Each Person Rathional,Collective NOT 每个人都是理性的,但集体是非理性的 即使在数学意义上是可传递的,在社会意义上是理性的,然而排序结果聚合的结果,未必是可传递性的和理性的。行为的本原是选择,而选择的本原是欲望和推理……没有智力和性格的结合,好或坏的行为也就不可能存在
……选择的根源在于欲望以及对结果有所预见的推理,这就是为什么选择不可能脱离理由而单独存在.
—— 亚里士多德选择就是深思熟虑的欲望。 —— 大卫・休谟
偏好聚合只是建立在同质可比性的前提下的连续性排序 —— SH-Lucien(29158394)
三、决策模型
Normative 规范性 帮助你做出决策 Positive 实证性 理解别人的决策1. Multi-Criterion Decision Making 多准则模型
多准则决策模型,衡量一种选择与另一种选择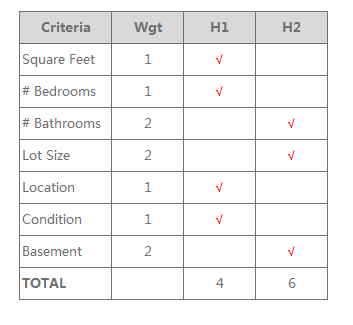 维度 × 权重(定性 × 定量)
也可以建立“I'd like”列,与选项作比较;或是通过选项差异,来反推别人的ideal points(理想点)。
比较当前选项与 ideal potins 的距离,来做决策
维度 × 权重(定性 × 定量)
也可以建立“I'd like”列,与选项作比较;或是通过选项差异,来反推别人的ideal points(理想点)。
比较当前选项与 ideal potins 的距离,来做决策
2. Spatial Choice Models 空间投票模型
L———————R 把"数据"整理为更直观的图表,辅助决策过程3. Probality:The Basics 基础概率
- Axiom1:Probability of an outcome in [0,1]
- Axiom2:Sum of all possible outcomes equals 1
- A subset of B,then Prob(B) ≥ Prob(A)
得到概率的方法:
- 古典的数学方法
- Frequency 基于统计频率
- Subjective 主观频率(猜测并进行修正)
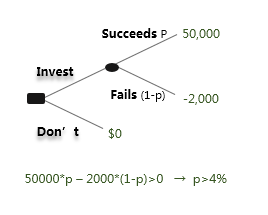
4. Decision Trees 决策树
- 用它来推测小概率事件,推测他人的选择,通过研究他的选择,来理解他对世界的看法,以及解释发生了什么事.
- 我们可以用决策树来多了解我们自己一点点.
我们可以用决策树来辅助决策过程
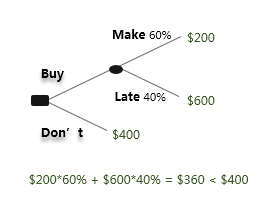
通过将复杂的分枝由末端逐步收敛到同级,使选项变得容易比较
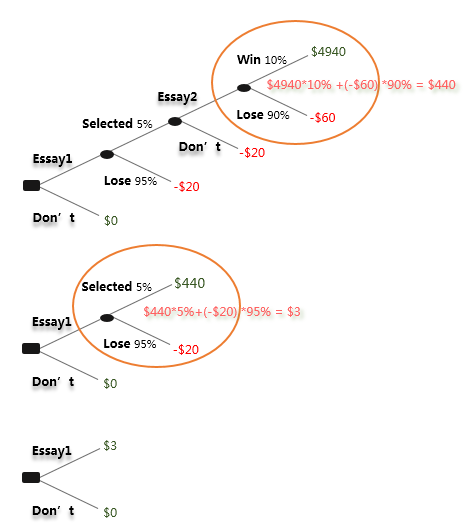
我们还可以运用决策树模型,来推测别人的想法
5. Value of Information 信息的价值
- Calculate value withiout the information
- Calculate value with the information
- Calculate the difference
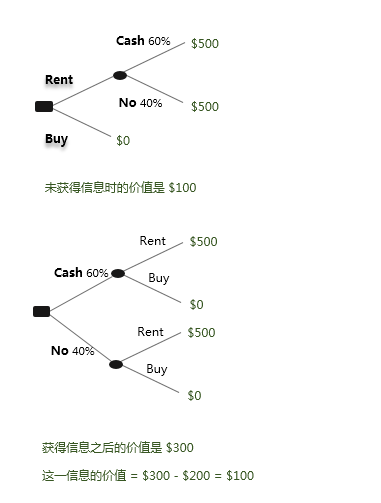
信息是一种经验商品,其价值只在使用后才被揭示 —— Shapiro and Varian
四、 Thinking Electrons:Modeling People 人类模型:电子思维
想象一下,如果电子能够思考的话,那么物理学该有多难呀!
—— Murray Gell-Mann
1. Rathinal actor model 理性人模型
假设有一个函数,理性人关注 Objective(利润、价值、选票)的最大化
optimize:Utility = C^0.5^L^0.5^
C = Consumption
L = Leisure
收益递减的特点 diminishing returns
主观上人是理性的,但是对于人类这一系统,由于自然理性和人的不确定性,结果也变得不确定起来。
动物的行为,不管是利他的或自私的,都在基因控制之下。这种控制尽管只是间接的,但仍然是十分强有力的。基因通过支配生存机器和它们的神经系统的建造方式而对行为施加其最终的影响。但此后怎么办,则由神经系统随时作出决定。
……
每当我们想要解释某种特性,如利他性行为的演化现象时,最好养成这样一种习惯——只要问问自己:“这种特性对基因库里的基因频率有什么影响?”
……
—— 《自私的基因》理查德・道金斯
索罗斯则在他的《超越金融》一书中提出了人的不确定性原则:
在参与者有思维能力的前提下,参与者对世界的看法永远是局限的和扭曲的,这就是“谬误性”。这些扭曲的观点可以影响参与者所处的环境,因为错误的看法会导致错误的行为,这就是“反射性”。
……
反射性不是人类事物中不确定性的唯一来源 …… 参与者之间的信息水平有差异,还有,不同的参与者可能有不同的利益,有些利益可能是相互冲突的。再者,各个参与者可能有多元且互不一致的价值取向 …… 我把这些因素综合在一起,称之为“人的不确定性”。
……
波普尔的科学方法论是一个简明而合理的设计,包括三个要素和三项运作。三个要素是:科学原理,以及运用这些原理的初始条件和最终条件。三项运作是:预测、解释和验证。当科学原理与初始条件相结合时,就产生预测。当原理与最终条件相结合时,则产生解释。从这个意义上来讲,预测和解释是对称的和可逆的。剩下的是验证,即将预测与实验结果进行比较。
……
人的不确定性原则破坏了波普尔模式的简明和合理 …… 初始条件和最终条件是应该包括还是应该剔除参与者的思维?这个问题很重要,因为检验要求这些条件能够重复。如果将参与者的思维包括进来,则很难观察初始条件和最终条件,因为参与者的看法只能从他们的表述或行动中推断。如果不包括,初始条件和最终条件则无法形成独特的观察,因为同样的客观情况可以与许多看法不同的参与者相关联 …… 这些困难不能阻止社会学家剔除有价值的概括,但概括很可能无法达到波普尔模式的要求,也无法与物理学定律的预断力相比。
社会科学家们感到很难接受这一结论。经济学家尤其会感受到弗洛伊德称为“物理羡慕”的苦恼。
……
有趣的是,波普尔和哈耶克在《经济学》杂志中都表示,社会科学不能得出像物理学那样的结果 …… 人们不应期望用经济学的理论找出普遍适用的规律,并可以反过来被用于解释和预测具体事件。
—— 《超越金融》乔治・索罗斯
理性人是对复杂人的一个抽象,不然无法分析经济问题。
理性人假设人倾向于最大化自身的效用。但对效用函数的形式却几乎没有限制。因而只要通过调整效用函数形式,这个分析框架就可以容纳利他行为。只要将其他人的效用放到行为人的效用函数中,对他来说,通过公益行为提升其他人效用,进而实现自身效用最大化就完全是理性的。
效用函数体现偏好关系。而一般在微观当中,一个理性的偏好关系只需要满足两个条件:完备性和传递性。前者要求个人明确知道对任意两个商品更偏好哪个,或是偏好无差异;后者则要求如果个人偏好A甚于B,偏好B甚于C,那就应当偏好A甚于C。
合理性是选择模式而不是单个选择本身的属性。想回家这件事本身没有任何不合理之处,但即想回家,又不想回家,这当中就有问题。《猜火车》里瑞顿选择海洛因这件事本身没有任何不合理之处,但如果他同时又选择避免可能的痛苦、绝望和死亡,他的选择就会显得很古怪。
—— 《牛津通识读本 选择理论》迈克尔・阿林厄姆
古典经济学的理性经济人假设,实际上是关于人的动机模式的假设。将附着于人身上的各种社会属性全部抽象掉了之后,对人的最深层次的动机模式进行假设。亚当・斯密认为,人的行为最根本的动机是自利动机,这是人的行为的最根本动力。
现代经济学不强调自利动机而强调行为规则符合逻辑,具体定义是:
- 理性人可以对任意商品的组合根据自己的偏好进行(有传递性的)排序;
- 在能够获得的所有商品组合中,理性人选择自己偏好排序最高的那一组。
这样就是理性的。(就是上周课程里的 A>B,B>C 如果 A>C 就是理性的)
目标函数 → 基于目标进行优化
2. Behavioral model 行为模型
人们会按照人的方式做事 和理性人模型系统性的偏离
(1) Think Fast and Slow
slow → 理性
fast → 直觉/情绪
(2) Prospect Theory 前景理论
情景①
+ 选项a:得到$400
+ 选择b:50%的机率得到 $1000,50%机率得到 $0
情景②
选项a:损失 $400
选择b:50%的机率损失 $1000,50%机率损失 $0
在情景①下更偏向于选项a,在情景②中更偏向于选项b
人类有在收益时反冒险,损失时偏好冒险的天性
(3) Hyperbolic Disscounting 双曲贴现
情景①
选择a:现在得到1000选择b:明天得到 1001
情景②
选择a:一年以后得到1000选择b:一年以后得到 1001
人类会根据未来的得失,以及未来的远近,为远期未来进行折现的倾向。 为近期的折现会比我们在远期的未来为同样量的收益多很多。
立刻的收益更重要,人们会为近期未来打折。明显的例子就是放弃长期的减肥计划,现在吃掉面前的巧克力蛋糕 ^_^
(4) Status Quo Bias 现状偏差
- 美国的器官捐献:点击以不捐献器官
- 英国的器官捐献:点击以捐献器官
美国的器官捐献率接近 80%,英国则只有 25%。
人类有继续当前状况,不做改变的倾向
(5) Base Rate Bias 基础率偏差
即锚定偏差
为盒子估计年份的数字,变成了为盒子估价的价格锚
It's WEIRD(诡异)
建立模型 → 偏差 → 评估 → 修正 → 理性+ / 理性-
3. Rule Based Model 规则模型
假定人们遵循某些规则,我们可以建立规则
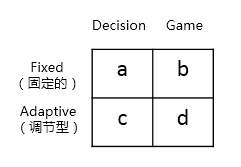
4. When Does Behavior Matter?行为什么时候重要?
理性的可以变成非理性的(理性人的行为不一定是理性的),同时受到反馈的影响,因此把偏差包括进来也非常重要。
在理性人模型的基础上,通过行为模型来理解和消除自然理性(如对保持现状的偏好,或是锚定),然后建立规则,规则可以被不断调整以减小偏差,越来越接近「理性选择」
例1. Two side Market 喊价
Buyers : [0 ,100]
Sellers: [50,150]
成交的价格区间为 [50,100],如果买卖双方都是理性人,均寻求最优化行为,最后的平均成交价应当接近75;如果买卖双方是非理性的(zero-inteligence trader),当市场足够大的时候,最后的平均成交价格依然是75(在各个价位上的分布也是相似么?)例2. Race to the Bottom 竞次游戏
在0-100之间任选一个数字,谁选的最接近平均值的 2/3 谁就赢
1. Rational
每个人都是理性的,且信息均衡,假设每个人都选 R ,平均值也是 R ,最优解是 2/3*R → 但每个人都选 2/3*R 时,最优解变成了 4/9*R → 以此类推最优解应当为0
2. Bias 带有偏差
在行为过程中,以前玩类似游戏时“赢的数字接近50”成为锚,使一些人做出客观上非理性的选择
有些人选50,某些人多想了一层选择 50*2/3≈33 ,某些人再多想一层 33*2/3=22 …… 当游戏次数足够多时,这个数字也会接近0
3. Rule Based
如果有两个理性人,一个非理性人。理性人会根据非理性人的决策做出决策。如果非理性人出的数字为X,理性人应当出R,R=(R+R+X)/3*2/3,即R=2/5*X
当非理性人出50时,最优解变成了20
五、Categorical Models 分类模型
把亚马逊当作 在线销售+物流 的投资者失去了机会,看到了 O2O 模式的投资者得到了机会
| INFO | DELIVERY |
|---|---|
| Amazon | × |
你的选择反映出你怎样对事物分类,你的分类将会影响你对这些事物的思考,还会影响你所做出的决定。
我们在生活中会使用各种分类,例如将手机分为“苹果手机”“Android手机”“WP手机”。分类让我们更有效率的做出选择,但也会导致偏差(聚合后的整体特征和其中的个体不一定一致,对Android手机这一整体的特征做出的决策可能导致错过性价比高的特定个体机型)
水果甜点的例子
| Food | Cal |
|---|---|
| Pear | 100 |
| Cake | 250 |
| Apple | 90 |
| Banana | 110 |
| Pie | 350 |
| Mean(平均值) | 180 |
Total Variation(总方差) = (100-180)² + (250-180)² + (90-180)² + … = 6400 + 4900 + 8100 + 4900 + 28900 = 53200
使用方差可以放大偏离程度 (当|数值|>1 时),这时候的总方差为 53200
让我们把这些食物分为水果类和甜点分类
| Data | Fruit | Dessert |
|---|---|---|
| - | Pear、Aplle、Banana | Cake、Pie |
| Cal | 100,90,110 | 250,350 |
| Mean | 100 | 300 |
| Variation | 200 | 5000 |
How did I explain?我解释了多少离散性?
(53200-5200)/53200 = 1- 5200/53200 = 90.2%
R-Squared(Coefficient of determination 拟合系数)
总变异(SST)= 组内变异(SSE)+ 组间变异(SSA)
R = 1-SSE/SST
R-square 代表了能解释的变异比例,其余是由干扰(误差)造成的,R值越大代表拟合度越高(误差小)
专家和非专家之间的一个区别是,专家倾向于更多的盒子,他们一般会把东西放到正确的盒子里去,也有建立正确盒子的能力。所以如果你想在预测事情或理解世界方面变得更出色,你需要的是很多的类别,你需要那些类别是正确的类别。
Correlation ≠ Causaton 相关性 ≠ 因果性
模型的R值高不等同模型是正确的,
1. Linear Models 线性模型
y = ax + b
- Sign:does y increase or decrease in x ?
- Magnitude:how much does y increase for each one unit increase in x ?
Fitting Lines to Data
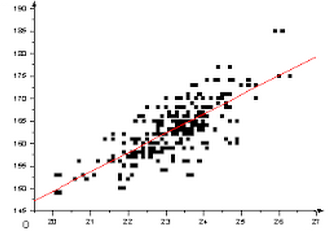
2. Reading Regression Output 读取回归输出
R-Squared:0.72
Standard Error:24.21
Observations:50
| - | Coeff | SE | P-value |
|---|---|---|---|
| Intercept(截距) | 25 | 2 | 0.000 |
| x1 | 20 | 1 | 0.000 |
| x2 | 10 | 4 | 0.014 |
我们做出期望 y = ax1 + bx2 + m ,教学质量随教师质量提高而增大,a应该大于0;教学质量随班级规模增大而减小,b应该小于0
截距告诉我们,拟合的模型是 y = 20x1 + 10x2 + 25
R值是0.72,这个模型的解释能力还不错,但是和期望不符,是期望错了还是模型有问题?
首先,样本总量 Observations 只有50,这并不是一个很大的样本量,再来看看SE
Standard Error(标准差)告诉我们离平均值有多远。最初数据的SE是24.21,系数25的SE是2,由钟形曲线那章学到的知识,我们可以知道截距有68%的概率在[23,27],有98%的概率在[21,29]
x1的系数几乎可以肯定是大于零;x2的系数则有98%的可能性在[2,18]之间,有至少2%的可能性小于2
P-value 告诉我们系数符号正确的可能性,截距和x1系数几乎可以肯定是正确的,x2系数则有1.4%的可能性是错的
回归输出告诉了我们能解释多少的差异,系数的符号和量级,系数出错的概率
3. From Linear to Nonlinear 从线性到非线性

把数据分为不同区间,用多段线性来拟合非线性,近乎可以解释非线性数据的部分。
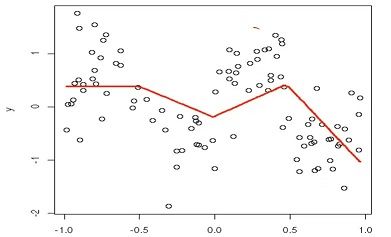
各个区间内的线性模型解释了多少?线性如果是非连续的,这中间发生了什么?
或者简单的把非线性关系包含进来,当作线性关系处理
y = ax2 + b → y = az + b and z = x
4. The Big Coefficient vs The New Reality
模型的基本流程:
- Construct Model
- Gater Data
- Identify important variables
- Change those variables
有关 Big Data
y = ax1 + bx2 + cx3 + …
- Big data does not obviate the uses of models
- Correlation is not Causation
- Linear models tell sign and magnitude of changes in independent variables within data range
此外:
- Feedbacks(反馈) 当模型研究的对象有参与能力时,数据很可能在某个区间失效
- 多峰效应 我们的认知能力有限,数据统计的样本也是有限的,在样本区间外可能有意想不到的现象
所有的模型都是错的
所有的大数据都是错的
六、临界点 Tipping Points
临界点和指数增长不同,临界点更像是量变引起质变
1. Percolation Model 渗透模型
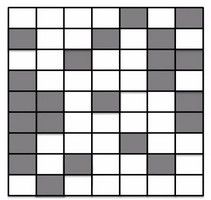
这个模型中每个方块都有1/2的概率为开,水能够从上端渗透到下端的临界点是0.592746
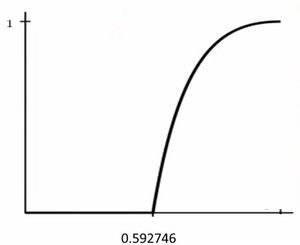
① NetLogo - Fire P = 58% (这里为树的密度值)

②NetLogo - Fire P = 59%

同样的,可以建立一个木材收成的模型:
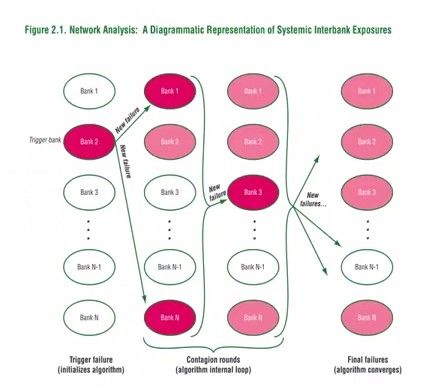
渗透模型也可以用于银行系统
或是用来理解信息传播
信息同样通过网络传播,当信息具有什么样的特性(非常重要,娱乐性高等,病毒传播),信息会被引爆呢?
科学技术也是一种信息,我们用渗透模型可以理解技术的突破:随着信息和知识的积累,我们会填充更多的格子,到最后有些人可以找到一条路径,一旦我们超过阈值,会有很多条路径,看起来就好象是突然间的科学活动的爆发
2. Contagion Models 1:Diffusion 传染病模型1:扩散
基本再生数 Basic reproduction number 如果基本再生数大于1,那么所有人都会被这种疾病传染;
不稳定疾病模型(wobbliness)
Wt 表示在 t 时刻被感染的人数,N 表示人口总数(可以是一个社区或全世界)
现在增加一个 Contact rate,人们接触的频率c
t时刻两人相遇时另一人感染的概率
t+1 时刻的感染人数
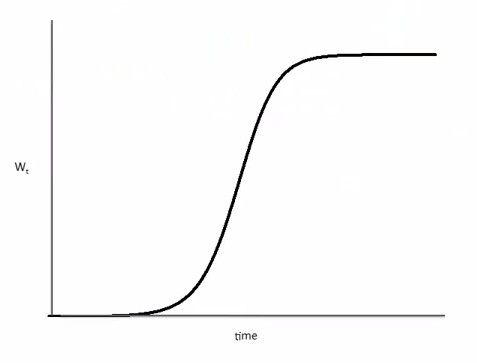
在这个疾病扩散模型中,初期感染人数非常小,扩散速度慢;中期较大的
这是一个自然扩散的结果,其中没有临界点,Kink ≠ Tip
3. Contagion Model 2:SIS Model 传染病模型2:SIS模型
SIS模型中,健康者被感染的同时也有感染者被治愈,感染者有a的概率恢复成无区别的健康者(假定他们不会产生免疫,或疾病像流感一样快速变异)
公式可以间化为
在疾病传播初期,最初的感染人数
这里的
Measles(麻疹) ≈ 15
Mumps(腮腺炎) ≈ 5
Flu(流感) ≈ 3
这些疾病的R0 都大于1
在制定政策时,多少人需要接受疫苗?
V = % Vaccinated 接受疫苗的人的比例
我们希望
我们可以根据病毒变异的快慢,以一种容易理解的方式,调整疫苗的接种比例
这里的
4. Classifying Tipping Points 划分临界点
Direct Tips 直接临界
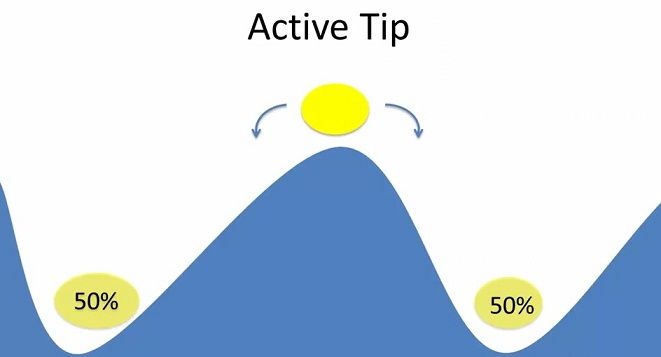
微小的动作或者事件会对最终的结果产生很大的影响,或者说变量做出很小的改变,对后续结果产生巨大影响
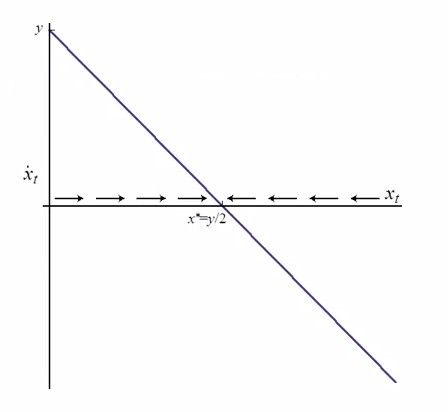
变量本身的变化引爆自身的状态
Contextual Tips 关联临界
关联临界是环境上的改变,在渗透模型中就相当于放进更多的方块,在森林模型中种植更多的树,在社区网络模型中建立更多链接,这样的改动使得直接临界性发生的可能性提高了
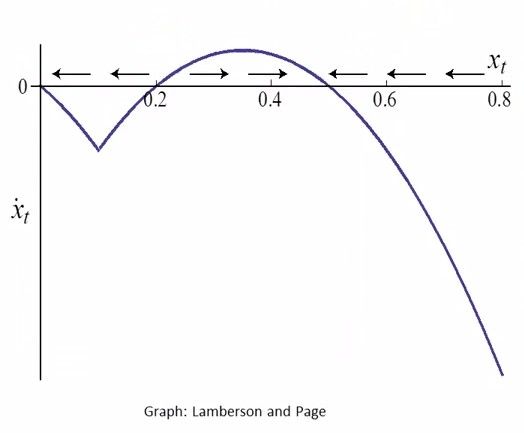
函数在y轴方向的变化引起了临界点的变化
环境中某个因素导致某事发生的条件成熟,环境中的某些改变会令整个系统的状态发生转变

均衡的,周期性的,随机的,复杂的
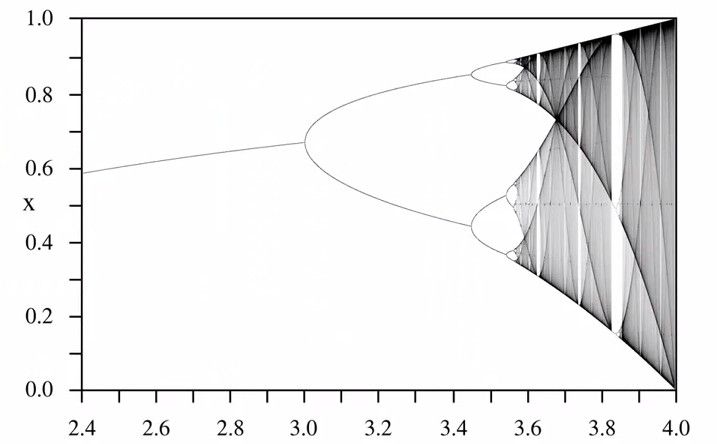
类内的临界点,使系统从目前稳态转移到另一个新的稳态
类间的临界点,使系统从平衡态转移到一个更复杂的阶段
使蜜蜂冬眠的温度是一个直接临界点,改变环境温度是关联临界
5. 测量临界点 Measuring Tips
Diversity Index 多样性指数
可以理解为对一些集合的分散程度的一个度量,告诉我们有多少种结果,举例来说,[
假设有ABCD四类人,他们在整个群体中的分布分别为 P
① 当
多样性指数
② 当
多样性指数
可以理解为,一开始有
熵 Entropy 测量不确定的度
在①中,熵为
熵告诉我们我们知道多少条的信息和我们必须知道多少的信息以确定结果。在①的例子里,我们要问两个问题来确定到底是哪个结果,Q1:[A、B]、[C、D]两组的结果是[A、B]?Q2:是A? (这里只是假定的情况)
多样性指标大致的告诉你类型的数目,熵告诉你需要多少的信息来决定类型
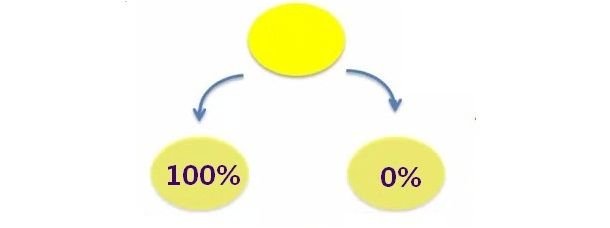
事件发生后,多样性为1,熵为0,系统已经没有不确定性了
七、Economic Growth 经济增长
GDP(Gross Domestic Product):Total market vlue of all goods and services.
一个经济体所有商品和服务的市场价值之和.
1. Compounding 复利
The Magic of Interest
| Year | 2% | 6% |
|---|---|---|
| 0 | 1,000 | 1,000 |
| 1 | 1,020 | 1,060 |
| 10 | 1,219 | 1,791 |
| 35 | 2,000 | 7,686 |
| 100 | 7,245 | 339,302 |
Rule of 72: 用72除以增长率,所得答案为使本金翻倍所需年数
在年均2%增长率的国家GDP翻倍时(72/2 = 36年),年均6%增长率的国家GDP翻了8倍(72/6=12)。从2%到6%并不只是在增长率上增加了4%!,它导致翻倍所需的时间的3倍差异。
2. Basic Growth Model 简单的增长模型
经济体:椰子、工人、机器、机器折旧
投资就是机器 —— 促进(经济)增长也限制(经济)增长.
Lt = Workers at time t
Mt = Machines at time t
Ot = Output of Coconuts at time t
Et = Number consumed at time t (时间t时被消费的椰子量)
It = Number invested at time t(时间t时用于投资的椰子量)
s = saving rate
d = Depreciation rate(折旧速率)
Assumption1: Output isincresing and concave in labor and machines
Assumption2: Output is consumed or invested
Assumption3: Machines can be built but depreciate
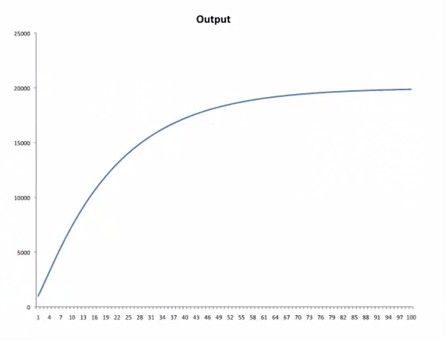
假设开始时有100个劳动力,4台机器,折旧率是0.25,储蓄利率是30%.
那么在t时刻,Qt=20,It=6,机器净增长=6-0.25*4=5,机器总数=9
在t+1时刻,Qt=30,It=9,机器净增长=9-0.25*9=7,机器总数=16
……
如果Mt=400呢?Mt+1=360
自然增长终有极限,决定机器增长的是什么?在这个例子里一个是取决于利率的投资,一个是折旧
平衡时,应当有
Solow Growth Model 索洛增长模型
Lt = Labor at time t
Kt = Capital at time t (技术水平)
At = Technology at time t
Ot = Output
if
索洛增长模型考虑了技术水平A的影响,并将基础模型中劳动力和资本的指数修改为β和1-β,以加入对劳动力和资本权重的衡量.
同样假设有100单位劳动力,储蓄利率为30%,折旧率为0.25,假设β为1/2,再考虑一下情况.
Q1:中国会持续增长吗?
中国的快速增长很大程度来自人口红利,以
Q2:为何一些国家没有增长?
索洛模型是真实世界的一个高度抽象,因此不包括很多因素.
例如,政府的“质量”,政府是否真的重视科技发展?如果政府不重视科技发展,A可能会减小,甚至小于1.根据乘数效应,者会让最后达到均衡时候的Q变得更小.
再例如,政府是否真的可以把可用资源配置在有用的地方,还是收为已用?资本的去向也是一个问题.
高的A真的一定会让GDP变高么?从短期看并不一定如此,在短期甚至中期的视角,科技发展可能导致大量失业,在一定时间段内显示为GDP的倒退.
索洛增长模型可以应用在其他的问题上,例如个人的发展问题。个人的发展终会遇到瓶颈,解决的办法之一就是不断学习,提高自我。
Diversity and Innovation 多样性和创新
对解决问题的过程进行建模:问题标准化 F(a)
Perspectives 视角
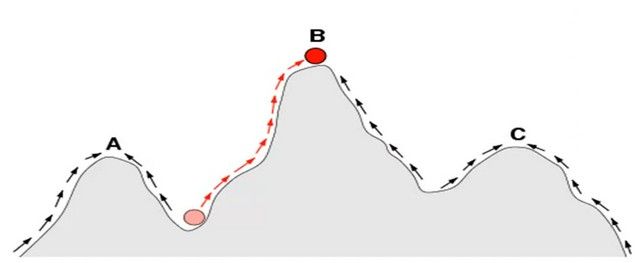
如何对问题进行编码,一旦你对问题进行了编码,你就创造了一个“地形”(用“寻找至高点”的比喻,你的编码就是x轴,每个可能的解决方案都有一个收益数.)
视角(Perspectives)就是在解决问题时对所有可能方案的呈现
Heuristics 启发式探索
你是如何在地形上移动的?如何避免被卡在A点和C点(局部最优)而爬上B点(全局最优)
Local Optima 局部最优点
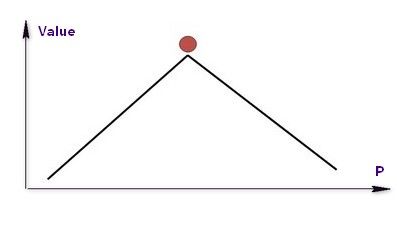
Mt Fuji Landscape 富士山模型
视角决定问题对你来说有多难,好的视角将难以琢磨的事物变得容易理解.(呈现信息的方式改变了理解信息的难易度)
e.g. Herb Simon 的和为15游戏
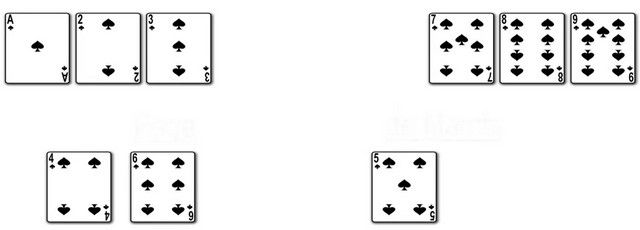
当我们用普通的排列来玩和为15时,思考起来很麻烦.

转变为幻方呢?
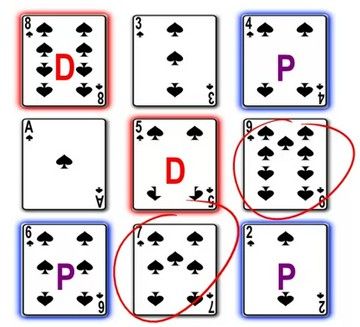
很容易就理解了游戏模式和游戏策略
Savant Exitstence Theorem :
For any problem there exists a perspective that creates a Mt Fuji Landscape (in fact many do).
学者存在性定理:
对于任何问题,都存在某种表述它的方式,可以把它变成"富士山模型".
几种不同的启发式探索法:
“爬山”(Hillclimb):左右试探“寻找最高点”的方法也是一种启发式探索,但有时我们会陷入局部最优解。
对于任何问题,你都可以把最坏的解决方法放在两侧,把最优的方法放在中间,把它变成富士山模型
“反其道而行之”(Do the Opposite):在面对问题时先思考现有的解决方法然后反其道而行。比如定价问题,在我们买东西时都是卖家给商品定价,反其道而行就是由顾客告诉商家自己的心理价位。再比如我们一般认为制造公司总致力于降低成本,也可以反其道而行之,主动提高产品的成本来彰显其品质。所以“反其道而行”这种战略有时会产生非常有趣的创新。
“从大石头开始”(Big Rocks First):假如你要在一个篮子里放一堆大小不一的石头,并尽可能地多放一些石头。如果先放小石头,那么最后篮子里就会塞满小石头,如果这个时候再放大石头那么根本放不下;但是如果我们从大石头开始,先把大石头放进去,再放小石头填满里面的缝隙,那么一切都很顺利。所以应该先放大石头再放小石头。
大石头其实代表了对我们来说重要的事情,想要在成功之路上走得更远,一定要先完成重要的事,这是成功者必备的品质。所以当你面对繁忙的工作时,运用这种启发式探索方式,先完成重要的事情,这样会让你更加游刃有余。
“从大石头开始”对所有的管理问题非常有效。
“没有免费午餐”(No Free Lunch)定律
All algorithms that search the same number of points with the goal of locating the maximum value of a function defined on a finite set perform exactly the same when averaged over all possible functions.
“没有免费午餐”定律表明,不存在一种能有效解决所有问题的启发式探索方法。或者说,如果你对所面临的问题完全无从下手,那么对你来说所有启发性探索法能起到的作用都是一样的。
比如,填满篮子要“从大石头开始”,但相反地,取出石头就需要“从小石头开始”,否则大石头根本取不出来.
每种启发式探索法的效果都是等价的,除非我们对问题有一定的了解。一旦我们对问题有了些许了解,那么我们就能找到更合适的启发式探索方法。比如,如果你不知道你看待问题的方式是否正确,那么就使用“爬山法”(随便挑一种方法就行),然后一旦你对这个问题的了解更加深入了,你可能就会发现这是个“从大石头开始”问题。
对一个问题,一个人可能用“四面看看”的启发式探索方法,换一个人可能会从不同的方向探索,如果综合他们的想法,就会发现更多的选择,所以不同的启发式探索方法让我们拥有更多的可能性。
Teams and Problem Solving 团队与问题解决
一个团队是一个 More to One 的整体,不同的看问题的方式和不同的寻找方案的方式构成了多元化.
团队的局部最优是所有成员的局部最优的交集,对于一个团队,唯一会被困住的地方是团队里所有人都会被困住的地方.
团队的问题:
- 沟通
- 偏差(错误的评估)
重组增长:信息积累
重组
我有对某个问题的一些解决方案,你有对另一个问题的解决方案,那么有时候我可以借鉴你的解决方案并把它和我的解决方案进行组合,这样就会获得一个更好的解决方案。
就像复杂的产品是由各种各样的部件组合起来一样,通过重组子问题的解决方案来获得更好的解决方案是创新的一个重要来源。
经济增长依赖于持续的创新,创新源自视角和方法的多样性,以及观点的重组.
Markov Models 马尔科夫模型
- 事物所处的状态,包括任何我们能想象到的状态.
- 转移概率,各状态间相互转移的概率.
Markov Transition Matrix 马尔列夫转换矩阵
假设A为上课时认真的同学,B为上课时不认真的同学,A在下一刻有80%的概率仍是认真的,有20%的概率变成不认真的.B在下一刻有25%的概率转变成认真的,有75%的概率依然是不认真的.
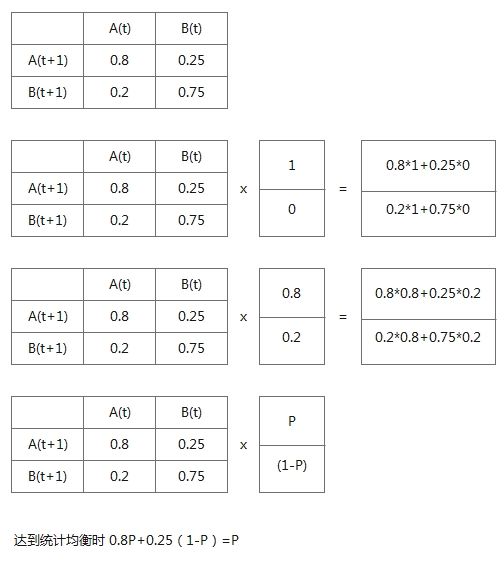
这个模型无论从所有人都是认真的开始,还是从所有人都不认真开始,最后都会达到统计均衡.
对于有三个以及更多状态的情况也可以使用这个模型:
比如对国家在民主、中立、不民主之间的数量统计情况:
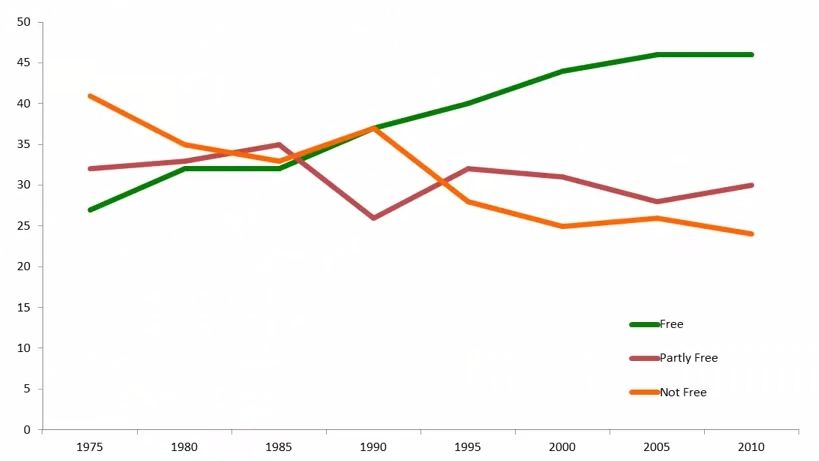
我们由前几年的统计数据做出预测

均衡时 Free:62.5% Partly Free:25.0% Not Free:12.5%
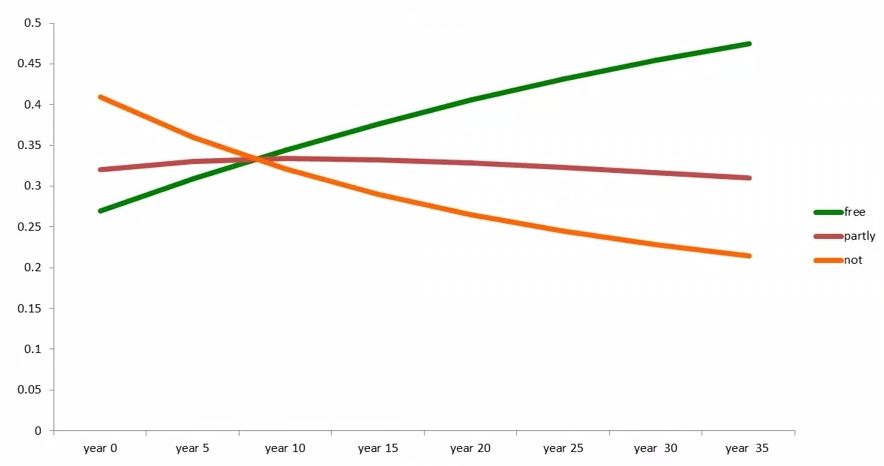
最终结果的相似性非常高.
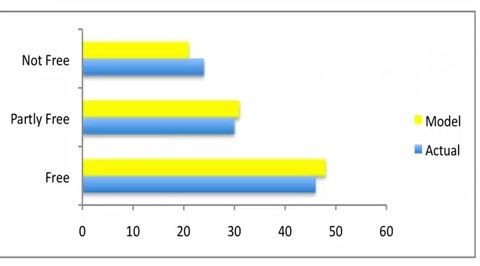
Markov Converagence 马尔科夫收敛定理
马尔科夫过程的均衡存在所必需的条件:
- Finite states 可能的状态数量是有限的
- Fixed transition probabilities 转移概率固定不变
- Can eventually get from any one state to any other 你最终总能从任意一个状态变到任意其它一个状态从A到C的概率可以是0,但可以从A先转化为B再转化为C
- Not a simple cycle
简单概括就是 有限状态、固定概率、可以从任意状态变到任意其它状态.
对于一个马尔科夫过程,无论初始状态是怎样的,无论历史过程是怎样的,或者有中途干预,最终我们都会达到均衡的结果.
然而这并不意味初始状态、历史过程、中途干预不重要:
- 马尔科夫均衡是一个长期过程的统计均衡,对于一个固定的马尔科夫均衡,这些改变影响到达均衡的时间.
- 并非所有历史过程都是马尔科夫收敛的,当中途干预越过了临界点,也有可能转移到另一个马尔科夫收敛.
