@rogeryi
2016-05-10T09:28:57.000000Z
字数 10144
阅读 5686
Design and Implementation of Command Buffer
Compositor Rendering GPU
作者: 易旭昕 (@roger2yi)
说明: 访问 Cmd Markdown 版本可以获得最佳阅读体验
本文主要描述 Command Buffer 的设计和在 Chromium Android WebView (下文简称 CAW) 上的实现细节,主要内容基于官方的文档 GPU Command Buffer,GPU Accelerated Compositing in Chrome 和当前的代码(40.0.2214.89)。
Command Buffer 相当于 Chromium 对 GPU 访问的一层封装,更确切地说应该是 GL,它的内部实现只支持 GL 和 GLES(通过 ANGLE 支持 Direct3D)。它隔离了一些非安全进程,比如 Renderer,Plugin,NativeClient 对 GPU 的直接访问,将 GPU 的访问限制在自己完全控制的进程里面 —— GPU 进程或者 Browser 进程,提高了 Chromium 的安全性;另外,Command Buffer 还有助于提高系统的健壮性,一方面它可以对要执行的命令先进行验证,另外如果在使用独立 GPU 进程的情况下,就是驱动发生了崩溃也不会导致整个浏览器崩溃。
除了上面所述的安全因素外,Command Buffer 还有一些其它优点:
- 为调用者提供更好的兼容性处理,避免调用者需要自行处理不同硬件的扩展支持,驱动 BUG 等问题;
- 提高性能,性能的提高来自于两方面,一方面是 GL 命令的批量调用减少额外的 CPU 开销,一方面是 Client/Server 的跨进程或者跨线程架构有助于提高 CPU 的并发程度,Client 端更少被阻塞;
- 支持多路复用,Command Buffer 对 Client 来说有点像一个虚拟的 GL 上下文,多个 Command Buffers 可以共用同一个物理 GL 上下文;
- Chromium 通过 Command Buffer 支持纹理共享,命令同步等扩展功能,类似于 EGLImage 和 EGLSync,但是如果多个 Command Buffer 共用同一个物理 GL 上下文时,它们是纯软件的实现,不依赖于具体的硬件和驱动,更稳定可靠;
Design
跟 GL 类似,Command Buffer 也是 Client/Server 的架构,Client 和 Service 可以运行在不同进程或者同一个进程的不同线程,甚至同一个线程,Command Buffer 为 Client 的使用者提供了一套跟 GLES2 基本一致的 API,而 Service 则将缓存中的命令转化成真正的 GL 或者 GLES2 命令。
一般而言,使用 Command Buffer 的一个 GL 命令的调用链如下所示:
gl2.h->gles2_c_lib.cc->GLES2Implemetation->GLES2CmdHelper...SharedMemory...->GLES2DecoderImpl->ui/gfx/gl/gl_bindings->OpenGL
gpu 模块有 GL,ui 模块也有 GL,它们的区别是 —— gpu 模块的 GL 是基于 Command Buffer 虚拟的 GL,而 ui 模块的 GL 是真正的 GL 调用
CommandBuffer 需要协调 GLES2CmdHelper 和 GLES2DecoderImpl 之间的通讯,GLES2CmdHelper 将 Client 调用的 GL 命令序列化后保存到一个共享的 Ring Buffer 里面,而 GLES2DecoderImpl 则通过反序列化从 Buffer 中读取命令,然后调用相应真正的 GL 命令。
在跨进程 Client/Server 的架构中,Client 和 Service 都各有一个 CommandBuffer 的实例,Client 端的是 CommandBufferProxyImpl,它通过 IPC 跟 Server 端通讯,而 Server 端的 CommandBufferService 则负责调用 GLES2DecoderImpl。而在单进程 Client/Server 的架构中,Client 端 CommandBuffer 的实例是 InProcessCommandBuffer,它会直接创建一个 CommandBufferService 实例运行在 Server 端,通过它去调用 GLES2DecoderImpl。
InProcessCommandBuffer
在 CAW 上,Chromium 运行在单进程架构下,并且没有自己独立的 GPU 线程,Android 本身的 GPU 线程就是 CAW 的 GPU 线程(4.x 上是 UI 线程,5.x 上是 Android Render 线程)。CAW 有两个 cc 实例,其中子合成器运行在 UI 线程,父合成器运行在 GPU 线程,每个 cc 都拥有一个自己的 InProcessCommandBuffer。更多关于 CAW 上 cc 的设计和实现,请参考 Design and Implementation of Chromium Compositor。

合成相关的主要对象
上图展示了合成相关的主要对象,绿色背景标识的是 cc 模块对象,红色背景标识的是 gpu 模块对象。我们可以看到在 CAW 里面,为每个 cc 实例提供的 ContextProvider 实际上是 ContextProviderInProcess,而 ContextProviderInProcess 为 cc 提供的绘图上下文是 WebGraphicsContext3DInProcessCommandBufferImpl,而 WebGraphicsContext3DInProcessCommandBufferImpl 实际上是 GLInProcessContextImpl 的封装,而 GLInProcessContextImpl 内部包含了一个 InProcessCommandBuffer 的实例。
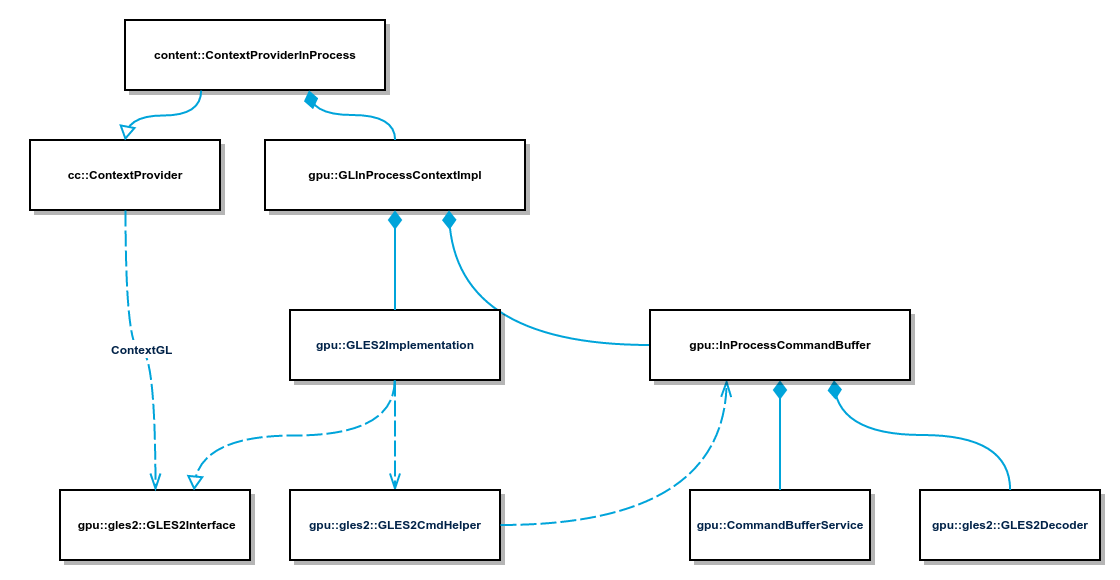
使用 InProcessCommandBuffer 的 CommandBuffer 的 Client/Server 架构
上图显示了使用 InProcessCommandBuffer 时 CommandBuffer 的 Client/Server 架构。Client 端对外的接口是 GLES2Interface,它的实现是 GLES2Implementation,cc 可以通过 ContextProvider 获取,比如下面的代码:
GLES2Interface* ResourceProvider::ContextGL() const {ContextProvider* context_provider = output_surface_->context_provider();return context_provider ? context_provider->ContextGL() : NULL;}
对 GLES2Interface 的 GL 调用,实际上会序列化后存储在 GLInProcessContextImpl 包含的 GLES2CmdHelper 的 Ring Buffer 里面(使用 base::ShareMemory,在 Android 平台是 ashmem 的封装)。
因为 InProcessCommandBuffer 是为单进程架构设计的 CommandBuffer,Client 和 Service 的交互很简单,不需要通过 IPC。InProcessCommandBuffer 提供了一个 InProcessCommandBuffer::Service 的接口,在 CAW 上实际的实现是 DeferredGpuCommandService。DeferredGpuCommandService 是一个全局的单例,意味着子合成器和父合成器实际上是共用同一个实例。当 InProcessCommandBuffer 的 Client,也就是 cc, Flush Command 或者需要执行其它 GL 任务的时候,实际上就是将要在 Server 端调用的方法包装成一个 Closure 对象放入 DeferredGpuCommandService 的队列里面,等待这个 Closure 在 GPU 线程被调用,而 DeferredGpuCommandService 会在 WebView.DrawGL 时候被调用,执行队列中的 Closure 对象。
InProcessCommandBuffer 本身就直接创建了 Server 端的对象,包括 CommandBufferService,GLES2DecoderImpl,GpuScheduler 等等,用于执行 Server 端的任务。当需要执行 cc Flush Command 的请求的时候,InProcessCommandBuffer 将请求交给 CommandBufferService 执行,CommandBufferService 使用 InProcessCommandBuffer 创建的 GLES2DecoderImpl 从 Ring Buffer 中取出命令,然后通过 ui 模块提供的 GL 上下文(gfx::GLContext)调用真正的 GL 命令,下面是 InProcessCommandBuffer::Flush 方法的代码:
void InProcessCommandBuffer::Flush(int32 put_offset) {...last_put_offset_ = put_offset;base::Closure task = base::Bind(&InProcessCommandBuffer::FlushOnGpuThread,gpu_thread_weak_ptr_,put_offset);QueueTask(task);}void InProcessCommandBuffer::FlushOnGpuThread(int32 put_offset) {...command_buffer_->Flush(put_offset);...}
对子合成器的 cc 实例来说,CommandBuffer 的 Client 运行在 UI 线程,Service 运行在 GPU 线程,父合成器的 CommandBuffer,Client 和 Service 都运行在 GPU 线程。无论是子合成器还是父合成器,它们 CommandBuffer 的 Service 都运行在同一个 GPU 线程,所以实际上它们是共用同一个物理 GL 上下文(这个 GL 上下文由 Android 提供),它们通过 Chromium 的纹理共享机制共享纹理,通过命令同步机制进行同步。
TransferBuffer
所谓 TransferBuffer,就是 CommandBuffer 在 Client/Server 之间的进程间共享内存缓存,TransferBuffer 实际上是 gpu::Buffer,而 gpu::Buffer 的 Backing 实际上是 base::SharedMemory,base::SharedMemory 在 Android 平台的实现使用了 ashmem。虽然理论上 CAW 不存在跨进程的 CommandBuffer,所以使用普通内存而不是 base::SharedMemory 作为 gpu::Buffer 的 Backing 应该也可以,不过目前的代码还是使用了 base::SharedMemory。
分配和释放 TransferBuffer 的 API 在 CommandBuffer 接口里面定义,InProcessCommandBuffer 的实现则直接调用了内部的 CommandBufferService,所以在 InProcessCommandBuffer 里面,TransferBuffer 的分配是不需要 Client 和 Service 之间的通讯:
// Create a transfer buffer of the given size. Returns its ID or -1 on// error.virtual scoped_refptr<gpu::Buffer> CreateTransferBuffer(size_t size,int32* id) = 0;// Destroy a transfer buffer. The ID must be positive.virtual void DestroyTransferBuffer(int32 id) = 0;
真正的实现在 CommandBufferService & TransferBufferManager 里面:
scoped_refptr<Buffer> CommandBufferService::CreateTransferBuffer(size_t size,int32* id) {*id = -1;scoped_ptr<SharedMemory> shared_memory(new SharedMemory());if (!shared_memory->CreateAndMapAnonymous(size))return NULL;static int32 next_id = 1;*id = next_id++;if (!RegisterTransferBuffer(*id, MakeBackingFromSharedMemory(shared_memory.Pass(), size))) {*id = -1;return NULL;}return GetTransferBuffer(*id);}
在 CommandBuffer 的实现里面,一些需要在 Client/Server 之间共享的缓存都通过 TransferBuffer 来分配,包括:
- 用来缓存 Client 调用的 GL Command 的 Ring Buffer;
- Client GL Command 里面包括的 Buffer Data;
- cc 光栅化时 Resouece 需要的 PixelBuffer;
- 需要在 Client/Server 之间同步的各种 Token 和 Query,Client 可以直接查询这些 Token 是否被 Service 触发,Query 是否被 Service 设置,这样比使用同步 IPC 效率要高;
每一块分配的 TransferBuffer 都会有一个对应的 ID 作为 Handle 使用,可以通过这个 ID 获取 TransferBuffer 的 Address 和 Size。另外像 PixelBuffer,Token 和 Query 实际上不是直接分配 TransferBuffer,而是 GLES2Implementation 通过 MappedMemoryManager 管理多块按需分配固定大小的 MemoryChunk(每一个 MemoryChunk 对应一个 TransferBuffer),PixelBuffer,Token 和 Query 实际上是在 MemoryChunk 上再进行分配,这样可以提高小块内存的分配和释放效率。
CHROMIUM_texture_mailbox
CHROMIUM_texture_mailbox 是 Chromium 基于 Command Buffer 提供的一个 GL 扩展,用于在不同的 Command Buffer 之间共享纹理数据。比如说,ComBuf A 拥有一个 Texture A,并且已经分配了 Image data,如果我们希望在 ComBuf B 的 Texture B 跟 Texture A 共享同样的 Image data,通过 Mailbox 机制我们可以这样做:
- 产生一个 Mailbox name(GenMailboxCHROMIUM);
- 将这个 Mailbox name 跟 Texure A 相关联(ProduceTextureCHROMIUM);
- 将这个 Mailbox 发送给 ComBuf B,在 ComBuf B 的上下文跟 Texture B 相关联(ConsumeTextureCHROMIUM);
当 ComBuf A 和 ComBuf B 的 Service 是在同一个 GPU 线程共享同一个物理 GL 上下文的情况下,Mailbox 的实现可以是一个纯软件的实现。如果 ComBuf A 和 ComBuf B 的 Service 是在不同的 GPU 线程和使用不同的物理 GL 上下文,Mailbox 的实现通常依赖于特定的 GL/EGL API,比如在 Android 上就需要使用 EGLImage。
CHROMIUM_texture_mailbox 主要的 API —— GenMailboxCHROMIUM,ProduceTextureCHROMIUM 和 ConsumeTextureCHROMIUM,具体的实现由 Mailbox 和 MailboxManager 提供。MailboxManager 在新的代码中变成了一个抽象的接口,它有两个实现 —— MailboxManagerImpl 和 MailboxManagerSync。在 CAW 里面,InProcessCommandBuffer 使用的是 MailboxManagerSync,MailboxManagerSync 支持在多个物理 GL 上下文中共享纹理数据,其实如果不是因为需要支持加速 Canvas 和 WebGL,对普通的网页渲染,使用 MailboxManagerImpl 其实就可以了。
CAW 父子合成器架构在当前的设计下,它们的 Command Buffer Service 共用同一个的 GPU 线程和物理 GL 上下文,所以实际上是共享同一个 MailboxManager,对于它们的 Command Buffer 的 Service,同样的 mailbox name 实际上指向同一个 Texture 对象,通过这种方式子合成器和父合成器的 Command Buffers 在不需要使用 EGLImage 的情况下就可以方便地通过同一个 Mailbox name 来共享纹理数据。
Texture* MailboxManagerSync::ConsumeTexture(const Mailbox& mailbox) {base::AutoLock lock(g_lock.Get());TextureGroup* group = TextureGroup::FromName(mailbox);if (!group)return NULL;// Check if a texture already exists in this share group.Texture* texture = group->FindTexture(this);if (texture)return texture;// Otherwise create a new texture.texture = group->GetDefinition().CreateTexture();...return texture;}
从上面的代码看,如果调用 ProduceTexture 和 ConsumeTexture 的是同一个 MailboxManagerSync,返回的实际上是同一个 Texture 对象。如果不是的话,它需要通过原来的 Texture A 创建的 TextureDefinition 创建一个新的 Texture B 对象返回,TextureDefinition 的内部实现其实就是通过 EGLImage 来实现纹理数据共享,Texture B 和 Texture A 共享同一个 NativeImageBufferEGL,而 NativeImageBufferEGL 则是 EGLImage 的一个封装。
scoped_refptr<NativeImageBufferEGL> NativeImageBufferEGL::Create(GLuint texture_id) {...const EGLint egl_attrib_list[] = {EGL_GL_TEXTURE_LEVEL_KHR, 0, EGL_IMAGE_PRESERVED_KHR, EGL_TRUE, EGL_NONE};EGLClientBuffer egl_buffer = reinterpret_cast<EGLClientBuffer>(texture_id);EGLenum egl_target = EGL_GL_TEXTURE_2D_KHR; // TODOEGLImageKHR egl_image = eglCreateImageKHR(egl_display, egl_context, egl_target, egl_buffer, egl_attrib_list);...return new NativeImageBufferEGL(egl_display, egl_image);}void NativeImageBufferEGL::BindToTexture(GLenum target) {...glEGLImageTargetTexture2DOES(target, egl_image_);...}
上面的代码显示当 Texture A 创建 NativeImageBufferEGL 时,实际上就是用它的 texture id 创建了一个 EGLImageKHR 对象,而 Texture B 通过 NativeImageBufferEGL::BindToTexture 里面对 glEGLImageTargetTexture2DOES 的调用,把自己的 texture id 跟这个 EGLImageKHR 对象绑定,从而共享 Texture A 的 Image data。
CHROMIUM_sync_point
CHROMIUM_sync_point 是 Chromium 基于 Command Buffer 提供的一个 GL 扩展,用于在多个 CommandBuffers 之间对命令的执行顺序进行同步。
CHROMIUM_sync_point 的 API —— InsertSyncPointCHROMIUM 和 WaitSyncPointCHROMIUM,具体的实现由 GpuControl 接口的实现者提供,而 InProcessCommandBuffer 同时实现了 CommandBuffer 和 GpuControl 接口,它实现的 CHROMIUM_sync_point 很简单,跟 CHROMIUM_texture_mailbox 一样,当两个 Command Buffer Service 都处于同一个 GPU 线程和物理 GL 上下文时,使用全局的线程锁和条件量就足够了。
bool InProcessCommandBuffer::WaitSyncPointOnGpuThread(unsigned sync_point) {g_sync_point_manager.Get().WaitSyncPoint(sync_point);gles2::MailboxManager* mailbox_manager =decoder_->GetContextGroup()->mailbox_manager();mailbox_manager->PullTextureUpdates(sync_point);return true;}void SyncPointManager::WaitSyncPoint(uint32 sync_point) {base::AutoLock lock(lock_);while (pending_sync_points_.count(sync_point)) {cond_var_.Wait();}}
因为 CHROMIUM_sync_point 通常是跟 CHROMIUM_texture_mailbox 一起使用,用于对共享的纹理读写进行同步,所以当两个 Command Buffer Service 有不同的 GPU 线程和物理 GL 上下文时,单纯使用 CPU 锁机制是不够的,还需要使用 GL/EGL 提供的 GPU 锁机制,在 Android 上就是使用 EGLFenceSync,CPU 锁和 GPU 锁需要同时使用才能真正满足跨物理 GL 上下文共享纹理的读写同步问题。
在 InProcessCommandBuffer::WaitSyncPointOnGpuThread 的代码里面需要调用 MailboxManager::PullTextureUpdates,跟踪它的实现会发现,它需要使用一个在 MailboxManagerSync::PushTextureUpdates 调用过程中创建的跟 sync point 对应的 GLFenceEGL 对象,调用 GLFenceEGL::ServerWait 方法进行同步,而 GLFenceEGL 其实就是 EGLFenceSync 的封装。
void MailboxManagerSync::PullTextureUpdates(uint32 sync_point) {base::AutoLock lock(g_lock.Get());AcquireFenceLocked(sync_point);...}void AcquireFenceLocked(uint32 sync_point) {g_lock.Get().AssertAcquired();SyncPointToFenceMap::iterator fence_it =g_sync_point_to_fence.Get().find(sync_point);if (fence_it != g_sync_point_to_fence.Get().end()) {fence_it->second->ServerWait();}}
