@jk88876594
2017-07-04T13:34:50.000000Z
字数 1297
阅读 4354
DataFrame——数据创建与导入
阿雷边学边教python数据分析第3期——pandas与numpy
1.什么是DataFrame
DataFrame是一种表格型的数据结构。
2.DataFrame的特征
(1)第一行为字段,即列名,从第二行开始为一行一行的记录
(2)每列可以是不同的值类型(数值,字符串,布尔值等)
(3)既有行索引也有列索引
3.获得DataFrame的两种方式
(1)自己创建DataFrame
- 通过字典创建DataFrame
开始之前我们要先导入pandas库,同时为了方便起见,也导入numpy库
import pandas as pdimport numpy as np
第一种方式:通过单层字典创建DataFrame
df1 = pd.DataFrame({"a":range(100,111),"b":range(200,211)})df1
第二种方式:通过嵌套字典创建DataFrame
dict_1 = {"b":{2015:3,2016:4,2017:7},"a":{2015:10,2016:20,2017:27}}df2 = pd.DataFrame(dict_1)df2
我们发现了一些有趣的事情:
1.外层字典的键(即b和a)作为了列,内层键(即2015,2016,2017)则作为了行索引
2.列名和行索引的排列方式按照升序排列了,和创建dict_1时的顺序不一样,这说明了用字典创建DataFrame时,索引和列名会默认地按照由小到大即升序的方式来排列
那么问题来了,我们能否显式地去指定索引和列名的顺序呢?
dict_1 = {"a":{2016:4,2015:3,2017:7},"b":{2017:27,2016:20,2015:10}}df2 = pd.DataFrame(dict_1,index=[2017,2015,2016],columns=["b","a"])df2
事实说明是可以的,由此我们又收获到了一个知识点:
在用字典创建DataFrame时,我们可以指定索引和列名的排列顺序。
- 通过数组创建DataFrame
df3 = pd.DataFrame(np.arange(12).reshape(3,4),index=[2015,2016,2017],columns=["产品1","产品2","产品3","产品4"])df3
相关解释:
arange(12):其实和range()差不多,只不过arange是在数组意义上的快速生成数列的方法。
reshape(3,4):将数组对象按照3行4列的方式排列
index:索引
columns:列名
(2)从外部导入DataFrame
导入的文件必须存放在python当前的路径里
- 导入csv文件
对于windows系统,在导入数据时可能会遇到一些编码问题,添加参数encoding="gbk"就可以解决大部分的情况了
文件里如果没有中文
pd.read_csv("1.csv")
如果文件包含中文,则添加encoding="gbk"
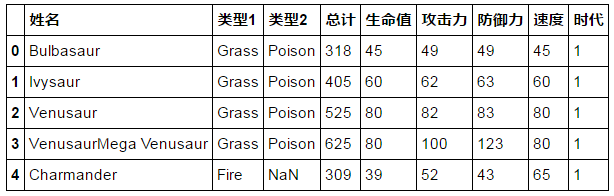
pd.read_csv("pokemon_data.csv",encoding="gbk")

4.导出csv文件
df.to_csv(".csv")