@hongchenzimo
2018-06-03T16:41:29.000000Z
字数 3798
阅读 1031
DeepLearning - Forard & Backward Propogation
博客园 MLAlgo DeepLearning.ai
In the previous post I go through basic 1-layer Neural Network with sigmoid activation function, including
How to get sigmoid function from a binary classification problem?
NN is still an optimization problem, so what's the target to optimize? - cost function
How does model learn?- gradient descent
Work flow of NN? - Backward/Forward propagation
Now let's get deeper to 2-layers Neural Network, from where you can have as many hidden layers as you want. Also let's try to vectorize everything.
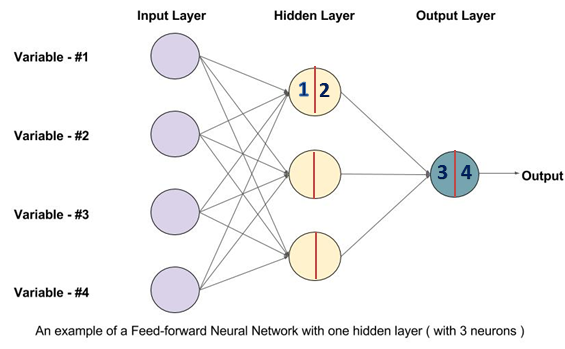
1. The architecture of 2-layers shallow NN
Below is the architecture of 2-layers NN, including input layer, one hidden layer and one output layer. The input layer is not counted.
(1) Forward propagation
In each neuron, there are 2 activities going on after take in the input from previous hidden layer:
- a linear transformation of the input
- a non-linear activation function applied after
Then the ouput will pass to the next hidden layer as input.
From input layer to output layer, do above computation layer by layer is forward propagation. It tries to map each input to .
For each training sample, the forward propagation is defined as following:
denotes the input data. In the picture n = 4.
is the parameter in the first hidden layer. Here k = 3.
is the parameter in the output layer. The output is a binary variable with 1 dimension.
is the intermediate output after linear transformation in the hidden and output layer.
is the output from each layer. To make it more generalize we can use to denote
*Here we use as activation function for hidden layer, and sigmoid for output layer. we will discuss what are the available activation functions out there in the following post. What happens in forward propagation is following:
(2) Backward propagation
After forward propagation, for each training sample is done ,we will have a prediction . Comparing with , we then use the error between prediction and real value to update the parameter via gradient descent.
Backward propagation is passing the gradient descent from output layer back to input layer using chain rule like below. The deduction is in the previous post.
2. Vectorize and Generalize your NN
Let's derive the vectorize representation of the above forward and backward propagation. The usage of vector is to speed up the computation. We will talk about this again in batch gradient descent.
stays the same. Generally has dimension and has dimension
where is the input vector, each column is one training sample.
(1) Forward propogation
Follow above logic, vectorize representation is below:
Have you noticed that the dimension above is not a exact matched?
has dimension , has dimension .
However Python will take care of this for you with Broadcasting. Basically it will replicate the lower dimension to the higher dimension. Here will be replicated m times to become
(1) Backward propogation
Same as above, backward propogation will be:
In the next post, I will talk about some other details in NN, like hyper parameter, activation function. To be continued.
