@dujun
2015-03-27T15:54:12.000000Z
字数 13078
阅读 4251
10.3.2.3 service
Kubernetes写书
什么是service以及为什么需要service
pod的生命周期是短时性的,它的行为由replication controller驱动,何时被创建以及何时被销毁是无法预测的。当给每个pod分配一个IP地址时,谁也无法保证这些IP地址是否为持久可访问的,因为这些IP地址对应的pod并非持久存在的。那么问题来了:在一个Kubernetes集群内部,如果一些pod(姑且称之为后端)向其他一些pod(姑且称之为前端)提供一些服务,那么前端pod如何找到后端pod?因此,一旦你拥有大量的pod副本,你就需要一个帮助你连接应用程序不同层级(譬如:前端和后端)的中间抽象层。而且,设想你用一个replication controller来管理你的后端pod集,你应该不希望每次replication controller对后端pod集进行调整时就要重新配置一次你的前端程序吧?同样地,如果后端pod被调度/重调度到其他机器上了,也不应该由你来重新配置前端程序。我们需要一座连通普通应用和运行于kubernetes集群内部的后端服务程序之间的桥梁,能够让用户透明地访问后端服务程序提供的功能。
这时候Kubernetes就又引入一个新的概念——service(服务),有时候我们也称之为micro-service(微服务)。Kubernetes service主要由一个IP地址和一个label selector组成。你可以把service看成是一个包含一组pod和访问这些pod规则的抽象集合。与replication controller类似,service通过label selector选择pod集,当pod集的大小超过1时,service会自动实现流量的负载均衡。我们以一个后端的图像处理程序为例,看看service带来的变化。假设该程序运行着多个实例,这些实例是可互换的且前端程序并不关心它实际使用的是哪个后端实例。当后端实例发生变化时(即包含的pod集发生改变),客户端程序依旧可以透明地使用后端程序提供的功能,因为service抽象层让前端和后端彻底解耦了。
对Kubernetes本地应用(例如Kubernetes一些系统组件),Kubernetes提供一个简单的EndpointsAPI,它会随着Kubernetes系统service内pod集的变化而动态更新访问信息;而对非Kubernetes本地应用,Kubernetes则为service提供一个基于虚拟IP的代理(即kube-prroxy,见下文),service利用这个代理将流量重定向到后端pod集。
定义一个简单的service
和pod一样,service也是一个Kubernetes REST对象,而与其他所有REST对象一样的是,客户端可以通过向kube-apiserver发送一个HTTP POST请求来创建一个新的service实例。假设你有一个pod集,该pod集中所有pod均被贴上labels:{"app": "MyApp"}且所有容器均对外暴露TCP9376端口。那么以下配置信息指定新创建一个名为myapp的service对象。
{
"id": "myapp",
"selector": {
"app": "MyApp"
},
"containerPort": 9376,
"protocol": "TCP",
"port": 8765
}
该service会将外部流量路由给labels与{"app": "MyApp"}匹配的所有pod的TCP9376端口。每个service会由系统分配一个虚拟IP地址作为service的入口IP地址(portal IP),而配置信息中的port即代表绑定到portal IP上的service port。上述portal IP和service port的组合称为service入口(portal,见下文)。需要注意的是,与replication controller不同,service对象的selector属性是可选项,即允许存在没有label selector的service(见下文)。为了更好地发挥service的作用,Kubernetes又引入了一个Endpoints对象与service协同工作。在这个例子中,名为myapp的service对象创建后,系统就会随之创建一个同样名为myapp的Endpoints对象,Endpoints对象存储了访问service的入口信息(见下文)。
不使用label selector的service
service除了能够提供一个访问后端pod集的抽象层外,也能被用作抽象任何类型的后端,典型的场景如下所示。
- 你的程序需要访问Kubernetes集群外部的一个用于生产环境的数据库。
- 你希望service能够指向其他namespace或集群的service。
- 你正在将一部分的工作负载迁移到Kubernetes集群中而另一部分后端服务还运行在Kubernetes集群外。
在上面提到的那些场景中,你可以定义一个没有 selector属性的service对象,如下所示。
"kind": "Service",
"apiVersion": "v1beta1",
"id": "myapp",
"port": 80
然后,你可以通过自定义一个Endpoints对象显式地将上述service对象映射到一个或多个后端(endpoints,即一个IP:port数组),如下所示。
"kind": "Endpoints",
"apiVersion": "v1beta1",
"id": "myapp",
"endpoints": ["173.194.112.206:80"]
访问一个没有selector属性的service实体的方法与访问有selector的没有任何区别,流量将会被路由到用户自定义的endpoints,在上面的例子中,即:173.194.112.206:80。
service是如何工作的
Kubernetes集群的每个节点上都运行着一个服务代理(kube-proxy),它实时监测Kubernetes的master节点上etd中Service和Endpoints对象的增加和删除信息。对于每个service,kube-proxy都会在本地节点上打开一个随机端口,所有路由到该端口的流量都会随之被重定向到相应的一个后端pod。至于具体选择哪个后端pod取决于service的负载均衡策略。在最早版本的Kubernetes中,service进行流量负载均衡的策略是round-robin,即随机选择一个后端pod,而在我们撰写这本书的时候,service的流量负载均衡策略变成了AffinityPolicy。最后,kube-proxy建立起iptables规则,将流向service的portal IP上service port的流量重定向至上面描述的那个随机端口。这样带来的网络上的效果就是所有发往service的流量都经过中间代理最后重定向到合适的后端pod,这一过程对用户是完全透明的,用户甚至都不需要知道什么是Kubernetes,什么是service,什么是pod。
以上过程可以用下面这张图来描述。
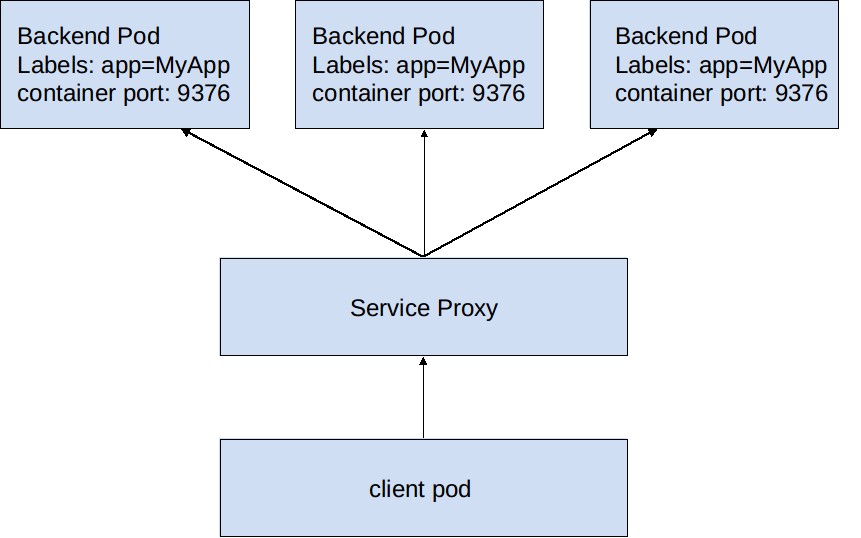
图1 service总体架构
这时候可能有读者会问:为什么不使用标准的round-robin DNS而是选择自己实现上面这套机制呢?是重复造轮子吗?Kubernetes设计者给出了以下这些原因:
- DNS函数库对DNS TTLS支持不好的问题由来已久,而且server端通常会将域名查找的结果进行缓存。
- 很多app都是进行一次域名查找然后将结果缓存起来。
- 即使app和DNS函数库进行了恰当的域名重解析操作,每个客户端频繁的域名重解析请求将给系统带来极大的负荷。
以上这些标准round-robin DNS的特点使得DNS无法敏捷地适应Kubernetes service动态伸缩的要求,这将直接导致DNS无法正确解析service域名。Kubernetes设计者极力反对用户使用DNS来解析service,但是要求Kubernetes支持service DNS的呼声还是很高的(即要求增加除portals外的其他选择)。其实service DNS也并非一无是处,下文将做更详细的解析。
发现service
Kubernetes主要支持两种service发现机制:环境变量和DNS,现逐一分析如下。
环境变量
当一个pod在一个工作节点上运行时,kubelet就会向它注入一组所有处于激活状态的service的环境变量,更具体地说是kubelet创建pod的参数里有service环境变量,然后如有需要,这些环境变量被注入pod内的容器中。这些环境变量是诸如{SVCNAME}_SERVICE_HOST和{SVCNAME}_SERVICE_PORT这样的变量,其中{SVCNAME}部分将service名字全部替换成大写且将破折号(-)替换成下划线(_)。假设serviceredis-master被分配了一个IP地址10.0.0.11并暴露一个TCP端口6379,那么将会生成以下这些环境变量。REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
客户端只需连接REDIS_MASTER_SERVICE_HOST(在这个例子中是10.0.0.11,更为一般的是$MYAPP_SERVICE_HOST)上的REDIS_MASTER_SERVICE_PORT
(在这个例子中是6379,更为一般的是$MYAPP_SERVICE_PORT)即可访问该service。
环境变量的注入过程其实蕴含着一个先后次序,即:任何想要访问service的pod都需要在service已经存在后创建,不然与service相关的环境变量就无法注入该pod的docker容器中。但如果使用DNS就不会有这样的限制,下文将会对service DNS作详细解释。
环境变量更高阶的解释
- DNS
Kubernetes集群现在支持增加一个可选的(尽管是强烈要求的)组件——DNS服务器。这个DNS服务器使用Kubernetes的watchAPI,不间断地监测新service的创建并为每个service新建一个DNS记录。如果DNS在整个集群范围内都可用,那么所有pod都能够自动解析service的域名。例如,假设你有一个名为my-service的service,且该service处在namespacemy-ns中,这样就形成了一条DNS记录:my-service.my-ns。在namespacemy-ns中的pod只要查找域名my-service即可发现该service,而处在其他namespace的的pod则必须指定完整的namespace前缀my-service,即:my-service.my-ns。DNS域名解析的结果就是一个service的入口IP地址(portal IP)。
headless services
用户可以通过指定service入口地址为空创建一个headless(无头)service。对于这些service,无需为之绑定IP地址或者域名也无需为之创建环境变量。另外,kube-proxy并不处理这些service而且系统为不会为这些service进行流量的负载均衡或代理。但endpoints_controller仍将为这些service在etcd中创建endpoint记录,这些endpoint同样可以通过API访问。这种类型的service同样可以使用UI、可用性检测等,与通用的service没有本质区别。但是使用headless service的代价是开发者需要选择与Kubernetes API或一个服务发现系统中的一个进行耦合。Kubernetes API支持自注册机制但是其他服务发现系统的接口一般也都建立在Kubernetes API之上。
service的入口地址和外部可路由性
以上的讨论都是基于Kubernetes集群内网环境进行的,即为service绑定的入口IP地址(portal IP,例如:10.0.0.11)是由kube-apiserver在一个特定的IP网段(portal_net)中随机选取的。该网段由Kubernetes自己维护的一个私有IP网段,除非用户自己指定,一般情况下不是外部可访问的且也不是用户内网的一个网段。但在实际情况中,一些service要求是外部可访问,例如,一个前端程序可能需要一个绑定外部IP地址(Kubernetes集群以外的IP地址,可能是一个公网IP也可能是用户内网的一个IP)的service。
如果Kubernetes集群部署在一个支持外部负载均衡器(external load balancer)的IaaS平台上(譬如GCE),则只需简单地将service对象的createExternalLoadBalancer属性设置为true即可实现我们的需求(见下文),这样IaaS平台就为你的service创建了一个基于云的负载均衡器并自动为其绑定外部IP地址。如此一来,发往外部负载均衡器的流量将被路由至后端pod,至于其中各种细节取决于具体的IaaS平台。而对于那些不支持外部负载均衡器的IaaS平台,你就需要DIY(do it yourself)外部IP地址池(publicIPs)。publicIPs是一个存储外部IP地址的数组,Kubernetes会将publicIPs数组内的IP地址与portal IP同等对待——kube-proxy同样会建立iptables规则并将发往该IP地址的流量转发至后端pod。你需要保证的是发向该外部IP的流量最终能够被导入到一个或多个Kubernetes工作节点,只要流量到达工作节点,接下来就由iptables规则负责转发。
当用户已经有一个现成的能够解析service入口IP地址的DNS服务器并且准备替换系统的DNS服务器或者service是一个已经配置好IP地址的遗留系统而且重新配置IP比较麻烦时,他们可以自己指定service入口IP地址作为创建service请求的一部分。用户自己选择的service入口IP地址必须是一个合法IP,即要求在APIserver启动时指定的portal_net的范围内。如果用户指定的service入口IP地址是非法的,则apiserver会返回一个422的HTTP状态码表明不合法。
创建service
理论讨论了这么多,接下来实践一下。首先定义两个pod,分别运行一个nginx容器,这两个pod的配置文件如下所示。
pod1内的容器打开80端口(nginx默认端口),映射到宿主机的8088端口。
$ cat pod-nginx_8088.json
{
"kind": "Pod",
"apiVersion": "v1beta1",
"id": "php-test2",
"desiredState": {
"manifest": {
"version": "v1beta1",
"id": "php-test2",
"containers": [{
"name": "nginx",
"image": "10.10.103.215:5000/nginx",
"ports": [{
"containerPort": 80,
"hostPort": 8088
}],
}]
}
},
"labels": {
"name": "service-nginx"
}
}
pod2内的容器同样打开80端口(nginx默认端口),映射到宿主机的8089端口。
$ cat pod-nginx_8089.json
{
"kind": "Pod",
"apiVersion": "v1beta1",
"id": "php-test",
"desiredState": {
"manifest": {
"version": "v1beta1",
"id": "php-test1",
"containers": [{
"name": "nginx",
"image": "10.10.103.215:5000/nginx",
"ports": [{
"containerPort": 80,
"hostPort": 8089
}],
}]
}
},
"labels": {
"name": "service-nginx"
}
}
创建以上两个pod。
$ kubectl create -f pod-nginx_8088.json
$ kubectl create -f pod-nginx_8089.json
查看创建的pod。
$ kubectl get pods
POD CONTAINER(S) IMAGE(S) HOST LABELS STATUS
php-test nginx 10.10.103.215:5000/nginx 127.0.0.1/ name=service-nginx Running
php-test2 nginx 10.10.103.215:5000/nginx 127.0.0.1/ name=service-nginx Running
如上所示,php-test和php-test2两个pod的labels均为name=service-nginx。
接下来定义一个service。
$ cat service_nginx.json
{
"kind": "Service",
"apiVersion": "v1beta1",
"id": "service-nginx",
"port": 8000,
"labels": {
"name": "service-nginx"
},
"selector": {
"name": "service-nginx"
}
}
service的配置文件较简单,与pod和replication controller类似,kind字段表明定义的是一个service。port字段表明可以通过8000端口访问该service。selector字段表明该service选择labels是{"name": "service-nginx"}的pod。与replication controller类似的是,出于管理的方便和概念的一致性,service对象一般也会有一组和它们管理的pod成员相同的labels属性,在这个例子中即:"labels": {"name": "service-nginx"}。service资源文件的labels字段是可选项,即使不写也不会有任何影响。
创建上面定义的service。
$ kubectl create -f service_nginx.json
查看创建的service。
$ kubectl get services
NAME LABELS SELECTOR IP PORT
kubernetes component=apiserver,provider=kubernetes <none> 11.1.1.104 443
kubernetes-ro component=apiserver,provider=kubernetes <none> 11.1.1.11 80
service-nginx name=service-nginx name=service-nginx 11.1.1.139 8000
可以看到的是,service service-nginx已经创建且分配到的入口IP地址是11.1.1.139(由apiserver自动从portal_net中随机分配),该IP地址与8000端口组成该service的入口地址(portal)。由于该service的label selector是{"name": "service-nginx"},因此该service自动选择以上创建的两个pod作为其后端pod。
细心的读者可能还发现了另外两个service:kubernetes和kubernetes-ro,这两个service是系统自定义的service,用于访问Kubernetes APIServer提供的API,在APIServer启动之初就已经存在了。其中,kubernetes支持读/写模式,需要进行用户认证;kubernetes-ro只支持只读模式,且对客户端的API请求速率有一定限制,但不需要进行用户认证。Kubernetes使用用户的service概念对Kubernetes API服务本身进行了抽象和封装。
再定义一个客户端pod,作为访问nginx web服务器的前端,该pod内有一个运行sshd的容器,其配置文件如下所示。
$ cat sshd-pod.json
{
"id": "client-pod",
"kind": "Pod",
"apiVersion": "v1beta1",
"desiredState": {
"manifest": {
"version": "v1beta1",
"id": "client-pod",
"containers": [{
"name": "client-container",
"image": "10.10.103.215:5000/sshd",
"cpu": 100,
"ports": [{
"containerPort": 22,
"hostPort": 1314
}]},
]
}
},
"labels": {
"name": "client-sshd",
"uses": "service-nginx",
}
}
创建上面定义的pod。
kubectl create -f sshd-pod.json
这样,一个简单的前端pod和service后端pod都搭建好了。通过ssh的方式进入前端pod容器,再在该容器内通过service的入口地址(11.1.1.139:8000)访问后台nginx web服务器。
$ ssh root@127.0.0.1 -p 1314
root@127.0.0.1's password:
Welcome to Ubuntu 12.04 LTS (GNU/Linux 3.13.0-32-generic x86_64)
* Documentation: https://help.ubuntu.com/
Last login: Mon Jan 12 12:42:46 2015 from 172.17.42.1
#访问service IP地址的8000端口
root@client-pod:~# curl 11.1.1.139:8000
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx on Debian!</title>
...
接下来我们将解析service的数据结构定义为更好地撰写service资源配置文件提供帮助,service数据结构定义如下所示。
type Service struct {
TypeMeta `json:",inline"`
Port int `json:"port"`
Protocol Protocol `json:"protocol,omitempty"`
Labels map[string]string `json:"labels,omitempty"`
Selector map[string]string `json:"selector"`
CreateExternalLoadBalancer bool `json:"createExternalLoadBalancer,omitempty"`
PublicIPs []string `json:"publicIPs,omitempty"`
ContainerPort util.IntOrString `json:"containerPort,omitempty"`
PortalIP string `json:"portalIP,omitempty"`
ProxyPort int `json:"proxyPort,omitempty"`
SessionAffinity AffinityType `json:"sessionAffinity,omitempty"`
}
现逐一解释除TypeMeta外各属性含义。
| 字段 | 是否必需 | 含义 | 备注 |
|---|---|---|---|
| Port | 是 | service对外暴露的端口号 | / |
| Protocol | 否 | 访问service端口的传输层协议 | 有两种选择:TCP和UDP,如不指定,默认是TCP |
| Labels | 否 | service对象的labels | / |
| Selector | 否 | service对象的label selector | / |
| CreateExternalLoadBalancer | 否 | 用于指定是否在service的外部IP上创建一个基于云的负载均衡器 | 要求工作节点上运行在IaaS上且IaaS支持创建负载均衡器 |
| PublicIPs | 否 | 用于为service分配外部可访问IP的IP池 | / |
| ContainerPort | 否 | service后端pod中容器对外暴露的端口 | / |
| PortalIP | 否 | service入口的IP地址 | 用户不自己指定则由kube-apiserver从portal_net中随机选取一个 |
| SessionAffinity | 否 | Used to maintain session affinity | 必须是ClientIP或None中的一个,默认值是None |
表x service数据结构各属性含义
通过研究上表,读者可以发现很有意思的一个细节,service可能是Kubernetes那么多REST对象中最“开放”的一个对象,因为它必需的字段只有一个,即service的访问端口Port!
设计细节
以上的内容对于那些只想知道如何使用Kubernetes service的人已经足够,但是还有一些有意思的技术细节值得深究。
如何避免service端口冲突
Kubernetes的主要设计哲学之一就是:用户永远不应该处于一个即使他们没有犯错也可能导致他们操作失败的境地。网络端口冲突就是用户在其他系统使用过程中经常会碰到的一个场景。如果端口隔离做得不好,用户很有可能会因为选择一个其他用户已经使用过的端口号而引发端口冲突问题。但我们在上面的讨论中并没有强调用户必须“小心翼翼”地选择service端口号,相反用户有自由地为各自的service选择端口号的权利。Kubernetes通过为每个service分配一个独一无二的Portal IP,并使用IP:port的组合访问一个service以避免端口冲突。而每个servicePortal IP的唯一性则是由Kubernetes APIServer保证的,对用户完全透明。事实上,保证service的端口不会与其他的冲突更本质的原因是kube-proxy会为每个service映射一个不会重复的随机端口,而在工作节点上实际打开的正是这个随机端口而非service自己定义的访问端口。
service入口
pod的IP地址与pod是一一对应且确定的关系,即发送给任意pod的IP地址的流量会路由到相应的pod。但service则不同,因为service背后对应的pod可能不止一个。我们将service的IP:port二元组称为service入口(portal),当客户端连接上service入口时,它的流量会自动地转发到合适的service后端pod(这个过程由linux的iptables机制来实现)。service的环境变量和DNS记录实际上都是为解析service入口的IP地址和端口服务的。
我们再次使用上文描述的图像处理程序作为举例说明的例子。当后端service创建后,Kubernetes的APIServer为其分配一个入口IP地址,譬如:10.0.0.1,并假设服务端口号是1234,那么service入口即:10.0.0.1:1234。Kubernetes的APIServer在etcd中存储这些信息以便让实时监测etcd中service对象变化的kube-proxy来读取。当kube-proxy发现一个新的service入口时,就会打开一个新的随机端口,建立一条iptables规则将发送到service入口的流量重定向到该随机端口,同时开始监听随机端口上的连接。
当一个客户端连接上service入口时,iptables负责将流量导向kube-proxy的随机端口上,然后kube-prxoy选择一个后端pod,将流量转发给该pod,kube-proxy在整个过程中扮演了一个流量中转站的角色。这样客户端就能够简单地通过IP+port的方式透明地使用service提供的功能,而无需知道到底是哪个pod在为它服务。
可以用下面这张图说明以上过程。
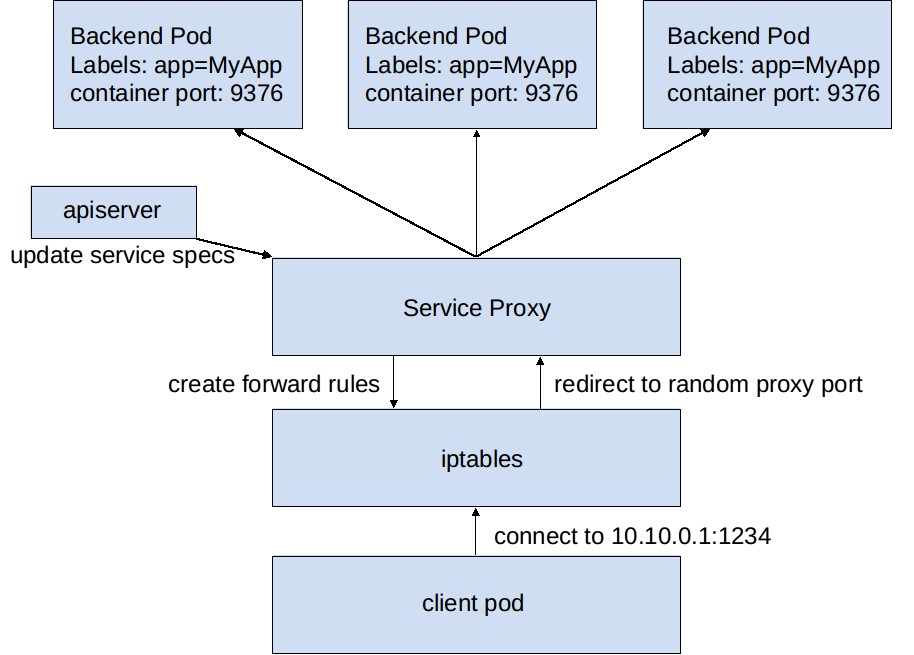
图2 service details
再看service环境变量
service环境变量是Kubernetes服务发现机制的基石,尽管原理简单,但使用过程中还是发现不少trick。正如上面讨论的那样,每新创建一个pod,Kubernetes就会将所有处于活动状态的service的环境变量注入该pod(通在过创建pod时传入参数的方式)。这样,pod内的容器可以使用这些环境变量。以上面的client pod为例,通过docker ps查询到该pod内部容器的ID,然后通过docker inspect CONTAINER_ID获取该容器的详细信息,service service-nginx相关的环境变量如下所示。
$ docker inspect ca4b26d8d7ab
"Env": [
...
"SERVICE_NGINX_SERVICE_HOST=11.1.1.139",
"SERVICE_NGINX_SERVICE_PORT=8000",
"SERVICE_NGINX_PORT=tcp://11.1.1.139:8000",
"SERVICE_NGINX_PORT_8000_TCP=tcp://11.1.1.139:8000",
"SERVICE_NGINX_PORT_8000_TCP_PROTO=tcp",
"SERVICE_NGINX_PORT_8000_TCP_PORT=8000",
"SERVICE_NGINX_PORT_8000_TCP_ADDR=11.1.1.139",
...
]
但是,如果ssh登入该容器,在终端键入env命令并不能看到上面这些环境变量。如果希望在容器内使用这些环境变量(譬如:SERVICE_NGINX_SERVICE_HOST和SERVICE_NGINX_SERVICE_PORT组合成一个NGINX_SERVER_ENDPOINT),需要在Dockerfile中添加类似下面这条命令。
"command": ["sh", "-c", 'NGINX_SERVER_ENDPOINT="http://$SERVICE_NGINX_SERVICE_HOST:$SERVICE_NGINX_SERVICE_PORT" /run.sh']
即把环境变量作为shell的参数传入Docker容器。
每新创建一个pod,就将所有处于活动状态的service的环境变量注入该pod,这一做法会带来明显的副作用:如果Kubernetes集群中的service数量庞大(1000+),则每个pod可能会被注入1000+组环境变量,而这些环境变量中有很多是用不到的。因此,Kubernetes支持service DNS是一个明智之举,这可以在一定程度上解决service环境变量泛滥的问题。
service目前存在的不足
Kubernetes使用iptables和kube-proxy解析service的入口地址(portals)在小/中规模的集群中运行良好,但是在大规模集群(尤其当service的数量超过一定规模时)却表现得不是那么尽如人意,首当其冲的便是service环境变量泛滥以及service与使用service的pod两者创建时间先后的制约关系等。而且使用kube-proxy做流量转发会隐藏发往service的IP包的源地址。
