@czyczk
2019-11-08T13:12:21.000000Z
字数 11594
阅读 567
Nginx
Nginx
依赖
必要
- gcc
- gcc-c++
- autoconf
- pcre
- pcre-devel
- make
- automake
工具
- vim
- httpd-tools
- wget
一、简述
Nginx 是一个开源且高性能、可选的 HTTP 中间件、代理服务。
为什么要用 Nginx
- IO 多路复用 epoll
想象一个老师和多个学生,老师出题学生答题。
老师为了检查学生是否都答完,
串行的方式是:挨个问,先问学生 A,他答完了再问学生 B……这样很大可能会有大量学生答完题闲着。
监听:多个老师,每个老师盯着一个学生。但是这样要请很多老师,会有较大的消耗。
IO 多路分用:学生主动上报,学生 A 做完了,老师过去解决。学生 B 做完了……
那现在,学生就是请求,老师就是线程。
多个描述符的 I/O 操作都能在一个线程内并发交替地顺序完成,这就叫 I/O 多路复用,这里的“复用”指的是复用同一个线程。
解释了什么是多路复用,还剩下 epoll。
epoll 模型是和 select 模型做对比。
举例来说,饭店里老板听到要结账,但是不知道是哪几桌要结。老板就要一个个去问是哪几桌,这样有遍历特征的是 select 模型的方式。而 epoll,服务员会记录下哪几桌要结账,然后把要结账的消息一并告诉老板,提高了效率。
- 轻量级
功能模块少,代码模块化
- CPU 亲和
CPU 亲和是一种把 CPU 核心和 Nginx 工作进程绑定的方式,把每个 worker 进程固定在一个 CPU 上执行,减少切换 CPU 的 cache miss,获得更好的性能。
- sendfile
静态资源从 File 到 Socket 可以直接通过 kernal space 而不需经过 user space。Nginx 充分利用了这一特性,提高了性能。
二、基础
2.1 文件与路径
如果是通过 pre-built package 安装的,则默认会有以下的结构。
| 路径 | 类型 | 作用 |
|---|---|---|
| /etc/logrotate.d/nginx | 配置文件 | Nginx 日志轮转,用于 logrotate 服务的日志切割 |
| /etc/nginx /etc/nginx/nginx.conf /etc/nginx/conf.d /etc/nginx/conf.d/default.conf |
目录、配置文件 | Nginx 主配置文件。默认读的是 /etc/nginx/conf.d/default.conf |
| /etc/nginx/fastcgi_params /etc/nginx/uwsgi_params /etc/nginx/scgi_params |
配置文件 | cgi 配置相关,fastcgi 配置 |
| /etc/nginx/koi-utf /etc/nginx/koi-win /etc/nginx/win-utf |
配置文件 | 编码转换映射转化文件 |
| /etc/nginx/mime.types | 配置文件 | 设置 HTTP 协议的 Content-Type 与扩展名对应关系 |
| /usr/lib/systemd/system/nginx-debug.service /usr/lib/systemd/system/nginx.service /etc/sysconfig/nginx /etc/sysconfig/nginx-debug |
配置文件 | 用于配置系统守护进程管理器管理方式 |
| /usr/lib64/nginx/modules /etc/nginx/modules |
目录 | Nginx 模块目录 |
| /usr/sbin/nginx /usr/sbin/nginx-debug |
命令 | Nginx 服务的启动管理的终端命令 |
| /usr/share/doc/nginx-1.12.0 /usr/share/doc/nginx-1.12.0/COPYRIGHT /usr/share/man/man8/nginx.8.gz |
文件、目录 | Nginx 的手册和帮助文件 |
| /var/cache/nginx | 目录 | Nginx 的缓存目录 |
| /var/log/nginx | 目录 | Nginx 的日志目录 |
自定义安装的编译选项有如下几类:
| 编译选项 | 作用 |
|---|---|
| --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/run/nginx.lock |
安装目的目录或路径 |
| --http-client-body-temp-path=/var/cache/nginx/client_temp --http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp |
执行对应模块时,Nginx 所保留的临时性文件 |
| --user=nginx --group=nginx |
设定 Nginx 进程启动的用户和组用户 |
| --with-cc-opt=parameters | 设置额外的参数将被添加到 CFLAGS 变量 |
| --with-ld-opt=parameters | 设置附加的参数,链接系统库 |
2.2 基础配置
注:通过 pre-built package 安装的 Nginx 默认先读取的配置文件是 /etc/nginx/conf.d/default.conf,对其中没有定义的部分,读取 /etc/nginx/nginx.conf。
server {listen 80;server_name localhost;location / {root /usr/share/nginx/html;index index.html index.htm;}...}
一个配置文件中可以写多个 server,每个 server 可以由监听端口和服务器名来区分。
每个 server 可以写多个 location,这个就像 SpringMVC 里 RequestMapping 的匹配方式一样,从精确匹配开始,最后落到 / 的匹配。
location 中 root 定义了 index 页在文件系统中的文件夹,index 定义 index 页的文件名。
注:对配置文件做了修改后,要通过 sudo nginx -s reload 或 systemctl reload nginx.service 让 Nginx 重新加载配置文件(亦可用 systemctl restart nginx.service 重启服务)。如果只修改了静态资源(HTML 文件等)则不需重启。
server {...error_page 500 502 503 504 /50x.htmllocation = /50x.html {root /usr/share/nginx/html;}...}
这里定义了遇到错误时,返回的错误页。
location 中的 = 表示精确匹配。
2.3 日志与变量
2.3.1 日志类型
包括 error_log、access_log
...error_log /var/log/nginx/error.log warn;...
.conf 文件里这样写就配置了 error_log 存放的位置,以及错误等级。
access_log 也同理。在默认的配置中可以看到它使用了自定义变量 main。
2.3.2 变量
三大类。
- HTTP 请求变量
- arg_PARAMETER
- http_HEADER(例如
'The user agent is $http_user_agent') - sent_http_HEADER(服务端给客户端返回的 response header)
- 内置变量
- Nginx 内置的(http://nginx.org/en/docs/ -> Logging to syslog)
- 自定义变量
- 自己定义
2.4 模块
在安装时的编译参数指定了启用哪些内置模块。
| 编译选项 | 作用 |
|---|---|
| --with-http_sub_status_module | Nginx 的客户端状态 |
| --with-http_random_index_module | 目录中选择一个随机主页 |
| --with-http_sub_module | HTTP 内容替换 |
等等。
2.4.1 模块配置
以下的配置在修改完成后,可使用 nginx -tc /etc/nginx/nginx.conf 检查语法是否正确。
- http_stub_status_module
Syntax:stub_status;
Context:server,location
例如:
location /mystatus {stub_status;}
random_index_module
Syntax:random_index on;|random_index off;
Default:random_index off;
Context:location
注意点是它只会调用 root 中非隐藏页面,而忽略隐藏页面。http_sub_module
语法有很多,常见的如:
替换页面中所有字符串。
Syntax:sub_filter {{string}} {{replacement}};
Context:http,server,location跟 HTTP 头中的 last_modified 有关,
on时对每个请求校验服务器内容是否发生变更,从而更好利用缓存。
Syntax:sub_filter_last_modified on | off;
Default:sub_filter_last_modified off;
Context:http,server,locationon时只对这类操作的匹配只匹配第一个。
Syntax:sub_filter_once on | off;
Default:sub_filter_once on;
Context:http,server,location
2.4.2 访问限制类模块配置
连接频率限制:limit_conn_module
请求频率限制:limit_req_module
基于 IP 的访问控制:http_access_module
基于用户的信任登录:http_auth_basic_module
附:HTTP 协议的连接与请求
| HTTP 协议版本 | 连接关系 |
|---|---|
| HTTP 1.0 | TCP 不能复用 |
| HTTP 1.1 | 顺序性 TCP 复用 |
| HTTP 2.0 | 多路复用 TCP 复用 |
常用语法:
Syntax: limit_conn_zone {{key}} zone={{name:size}};
Context: http
以 IP 做 key,就是按 client 的 IP 来限制。
创建一个 zone 以便下一步 ↓↓ 方便引用。zone 里 name 是这个 zone 的名称,size 是 zone 的大小。
要注意的是,zone 的定义必须在 server 之外,即 http 那一层里。
Syntax: limit_conn {{zone}} {{number}};
Context: http, server, location
限制请求频率的也相似,
Syntax: limit_req_zone {{key}} zone={{name:size}} rate={{rate}};
Context: http
Syntax: limit_req zone={{name}} [burst={{number}}] [nodelay];
Context: http, server, location
详细例:
limit_conn_zone $binary_remote_addr zone=conn_zone:1m;limit_req_zone $binary_remote_addr zone=req_zone:1m rate=1r/s;// 为什么这里用 binary_remote_addr?// 因为如果每个 req 保存其 remote_addr,会比这样多 10 个字节,对于成千的请求到来时更浪费分配的空间。server {...location / {root ...index ...limit_conn conn_zone 1;limit_req zone=req_zone burst=3 nodelay;// burst=3 是可选的,意思是虽然定义了每秒只能有 1 个请求,但可以暂存 3 个请求放在下一秒执行,起到访问限速的作用。// nodelay 是可选的,跟在 burst=3 之后,意思是对于暂存的 3 个请求以外的请求,直接返回 503 错误。}...}
对其的测试可以使用 ab,如
ab -n 50 -c 20 http://{{ip here}}/{{some page}}
这样一共发 50 个请求,最多 20 个并发。如果出现 timed out 等错误,考虑可能是网络通信的问题,可以适当调小请求总数。
Syntax: allow {{address}} | {{CIDR}} | unix: | all;
Context: http, server, location, limit_except
允许某个地址/某个网段/unix socket/所有的访问。
把 allow 改成 delay 就是拒绝的请求定义。
详例:
server {...location ~ ^/admin.html {root /opt/app/code;deny 222.128.189.17;allow all;index index.html index.htm;}...}
~ ^/admin.html 表示模式匹配,所有根目录下 admin.html 开头的请求。
只禁止某个 IP 地址,就先 deny ip_addr 再 allow all。
类似地,只允许某个网段,就先 allow 222.128.189.0/24 再 deny all。
http_access_module 的局限性:
如果 IP 1 是通过 IP 2 访问目标 IP 3 的话,通过 http_access_module,IP 3 只能知道 $remote_addr 是 IP 2,从而无法达到禁止或允许 IP 1 的目的。
http_x_forwarded_for 可以解决这个问题(是解决这个问题的方法之一,在第六节 - 代理中有例)。
附:
IP 1 -> IP 2 -> IP 3
IP 2 {remote_addr: IP 1http_x_forwarded_for: IP 1}IP 3 {remote_addr: IP 1http_x_forwarded_for: IP 1, IP 2(即 client, proxy 1, proxy 2... 的 IP)}
总的来说,解决知道最原初的 client IP 的方式有这些:
1. 采用别的 HTTP 头信息,如 http_x_forwarded_for(但是这只是协议所要求的,不一定被实现,或按规矩填写)
2. 结合 GEO 模块(Nginx 的另外一个模块,后谈)
3. 通过 HTTP 自定义变量传递
Syntax: auth_basic {{string}} | off;
Default: auth_basic off;
Context: http, server, location, limit_except
Syntax: auth_basic_user_file {{file}};
Context: http, server, location, limit_except
利用存有帐号和密码的文件来认证,但是这个文件的格式有所要求:
name1:password1name2:password2:commentname3:password3
还有一些和密码加密方式相关的选项,详见:http://nginx.org/en/docs/http/ngx_htp_auth_basic_module.html
密码文件一般考虑存放在 /etc/nginx 下,通过 htpasswd -c ./auth_conf {{username}},再提示中输入密码创建。
配置文件详例:
location ~ ^/admin.html {root /opt/app/code;auth_basic "Auth access test!";auth_basic_user_file /etc/nginx/auth_conf;index index.html index.htm;}
http_auth_basic_module 局限性:
1. 用户信息依赖文件方式。
2. 操作管理机械,效率低下。
解决:
1. Nginx + LUA
2. Nginx + LDAP(nginx-auth-ldap 模块)
三、常见 Nginx 中间架构
- 表态资源 WEB 服务
- 代理服务
- 负载均衡调度器 SLB
- 动态缓存
3.1 文件读取
Syntax: sendfile on | off;
Default: sendfile off;
Context: http, server, location, if in location
(在新的版本中还有 --with-file-aio 异步文件读取的方式。)
在 sendfile 开启情况下,可以通过打开这个来提高网络包的传输效率。特别对于大文件的传输是推荐的。
Syntax: tcp_nopush on | off;
Default: tcp_nopush off;
Context: http, server, location
它不着急将数据传出,而是积累到一定程度一并发出。
与之相反的是 tcp_nodelay
Syntax: tcp_nodelay on | off;
Default: tcp_nodelay on;
Context: http, server, location
它在 keepalive 连接下,提高网络包的传输实时性。
3.2 压缩
压缩(推荐)
Syntax: gzip on | off;
Default: gzip off;
Context: http, server, location, if in location
与之配套使用的是压缩等级
Syntax: gzip_comp_level {{level}};
Default: gzip_comp_level 1;
Context: http, server, location
以及压缩版本
Syntax: gzip_http_version 1.0 | 1.1;
Default: gzip_http_version 1.1;
Context: http, server, location
压缩模块扩展:
http_gzip_static_module 预读 gzip 功能
它在资源的同级目录下找,有没有这个资源的 .gz 压缩过的版本,并优先利用,以节省 CPU 的消耗,但是多消耗了硬盘的占用。
.gz 文件要预先生成,通过系统命令 gzip {{file}} 来压缩。(这个命令会删除原文件)
http_gunzip_module 应用支持 gunzip 的压缩方式(很少应用,针对不支持 gzip 压缩的浏览器使用的)
3.2.1 示例
location ~ .*\.(jpg|gif|png)$ {gzip on;gzip_http_version 1.1; #as defaultgzip_comp_level 2;gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;root /opt/app/code/images;}location ~ .*\.(txt|xml)$ {gzip on;gzip_http_version 1.1; #as defaultgzip_comp_level 1; #as defaultgzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;root /opt/app/code/doc;}location ~ ^/download {gzip_static on;tcp_nopush on;root /opt/app/code;}
3.3 缓存
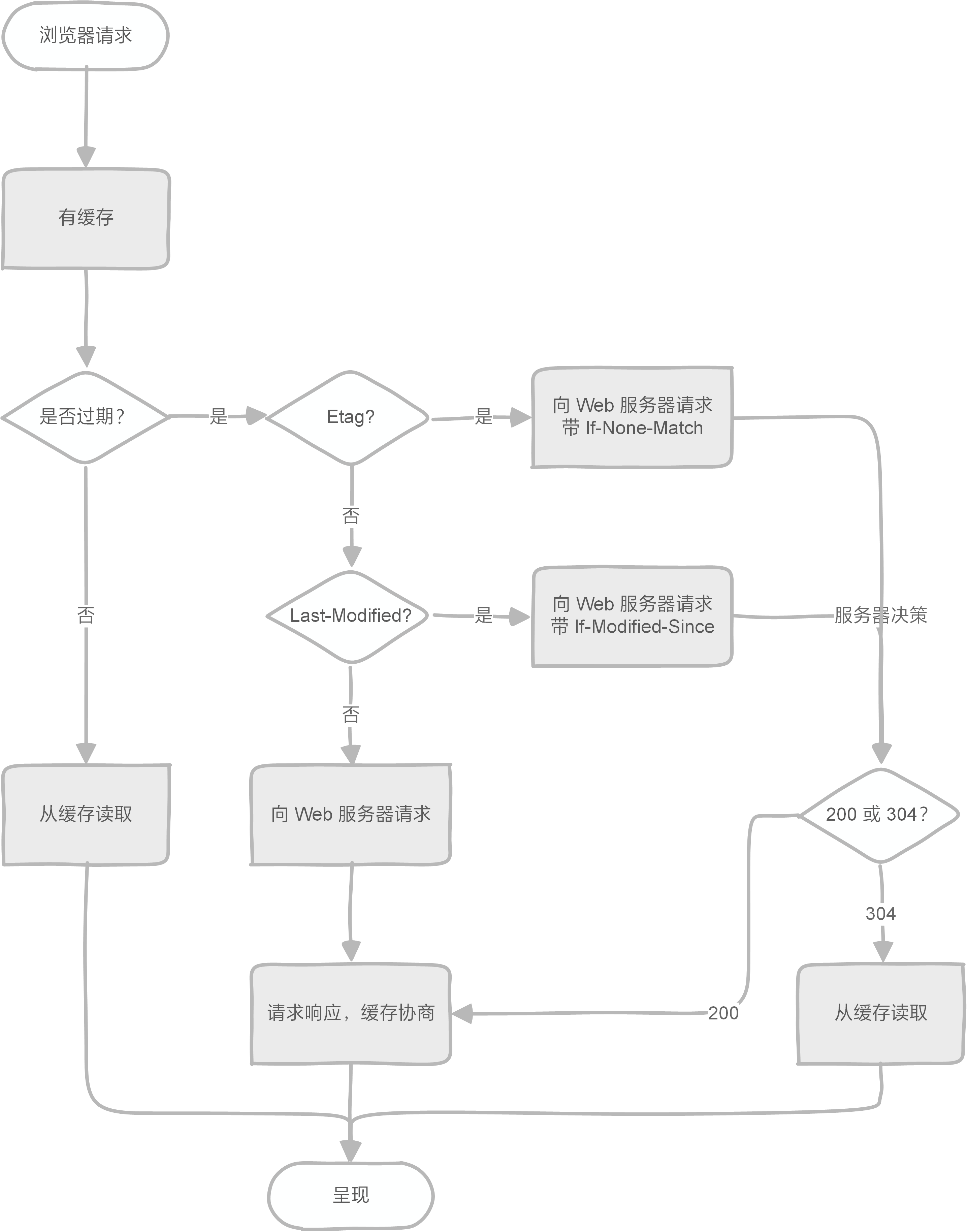
3.3.1 基本浏览器缓存知识
HTTP 协议定义的缓存机制(如:Expires, Cache-Control 等)
首次:
浏览器请求 → 无缓存 → 请求 WEB 服务器 → 请求响应,协商 → 呈现
第二次:
浏览器请求 → 有缓存 → 校验是否过期 → 呈现
校验过期机制:
| 类型 | 字段 |
|---|---|
| 校验是否过期 | Expires (HTTP 1.0)、Cache-Control (HTTP 1.1) (max-age) 没超期,就当缓存可用。如果超期了就会触发以下验证。 |
| 协议中 Etag 头信息校验 | Etag 与 Last-Modified 类似,但可以解决秒内更新问题。比 Last-Modified 优先校验。 |
| Last-Modified 头信息校验 | Last-Modified 一个具体的年月日时分秒。请求发往服务器,如果服务端更新了,就会更新这个时间。当发现与请求所携带的这个信息不同,就认为服务端有更新的版本,从而传回新的内容。 |
附:缓存原理
3.3.2 配置与示例
Syntax: expires [modified] {{time}};
expires {{epoch}} | max | off;
Default: expires off;
Context: http, server, location, if in location
location ~ .*\.(htm|html)$ {expires 24h;root /opt/app/code;}
四、跨域
4.1 为什么浏览器默认禁止跨域访问
先来看看跨域访问为什么危险(CSRF 攻击)。
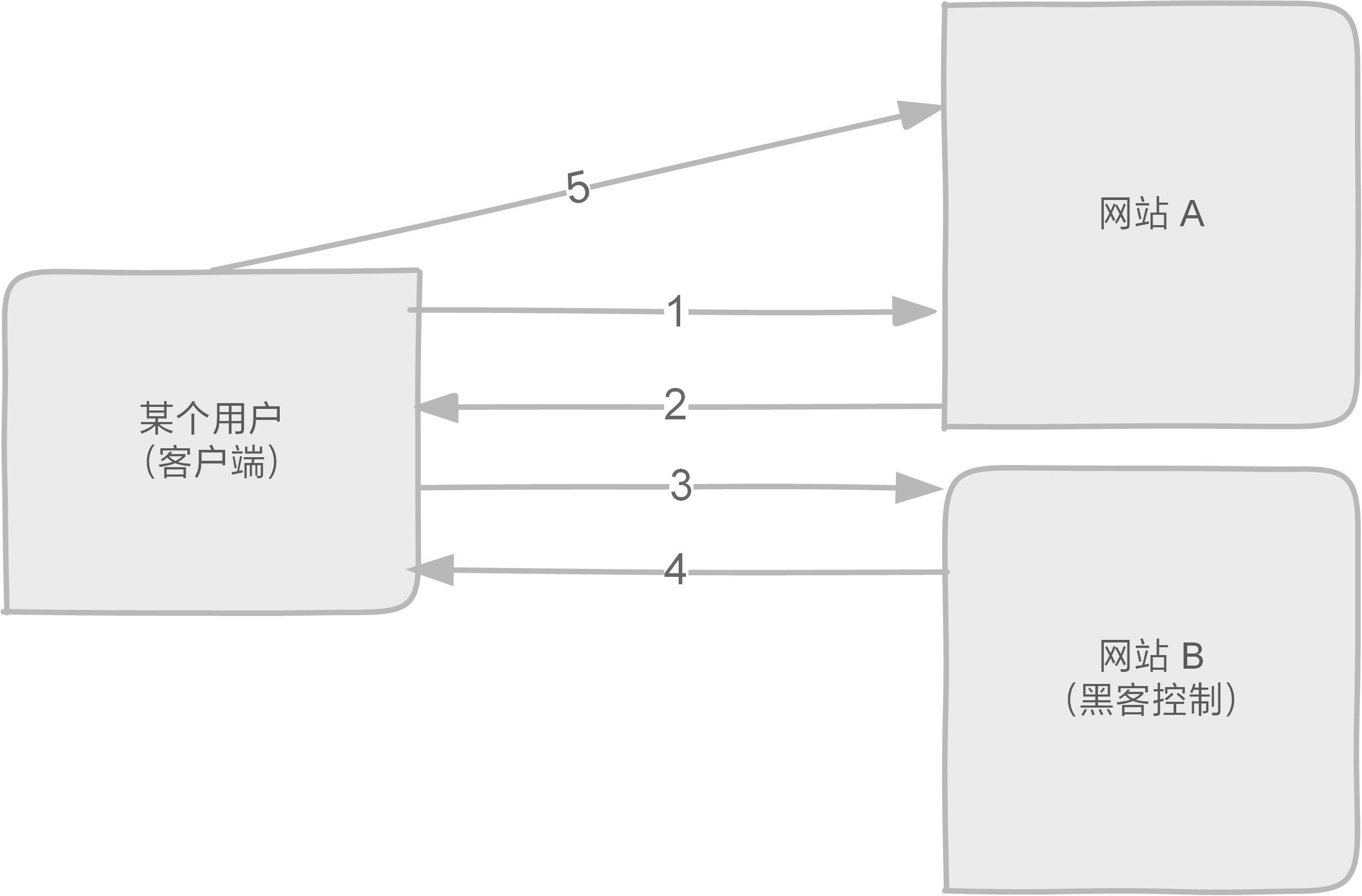
1、2:用户先正常地访问网站 A。网站 A 给了它一些 cookies,客户端留存了。
3、4:用户不小心访问了黑客控制的网站 B。网站 B 给了它带有恶意的请求,目的是让用户访问网站 A。
5:用户访问了网站 A(可以造成对网站 A 的注入攻击,或加重网站 A 的负载等)。
但有时打开这个限制是必要的。
4.2 如何跨域
Syntax: add_header {{name}} {{value}} [always];
Context: http, server, location, if in location
通过这个启用 Access-Control-Allow-Origin 的话(value 就填允许的站点,如果是所有站点就填 *),服务器传回的响应就会告诉客户端它接受跨域请求。
如果服务端允许了访问,那浏览器就不会限制。
4.3 示例
location ~ .*\.(htm|html)$ {add_header Access-Control-Allow-Origin http://www.jesonc.com;add_header Access-Control-Allow-Methods GET, POST, PUT, DELETE, OPTIONS;root /opt/app/code;}
允许来自 www.jesonc.com 的请求访问这个站点里的 htm 和 html 资源,并指定了允许的方法。
五、防盗链
5.1 为什么防盗链与设置思路
用来防止来自其他网站的爬虫等爬取走自己网站的信息。
关键在于区别哪些请求是正常用户的请求。
5.2 基于 http_referer 的防盗链配置模块
Syntax: valid_referers none | blocked | {{server_names}} | {{string}} ... ;
Context: server, location
在日志的 main 格式中,就有 $http_referer(在 user-agent 之前的那个)。
5.3 示例
location ~ .*\.(jpg|gif|png)$ {gzip on;gzip_http_version 1.1;gzip_comp_level 2;gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;valid_referers none blocked 116.62.103.228 ~/google\./;if ($invalid_referer) {return 403;}root /opt/app/code/images;}
允许 none(不带 http_referer 信息的)、blocked(非标准,如不以 http:// 开头的 htp_referer 信息的),以及来自特定 IP 地址的信息的请求,最后可使用正则表达式允许一些来自搜索引擎的访问。
执行完后可以使用 $invalid_referer 变量,如果它是非 0 (true) 的话,则跳转 403 页面。
可以通过 curl -I http://116.62.103.228/wei.png 发送一个服务器接受的请求,并打印响应头信息来校验。
然后通过 curl -e "http://www.baidu.com" -I http://116.62.103.228/wei.png 发送一个服务器不接受的请求,并打印响应头信息。
可以清楚的看出,这种防盗链机制的局限是,请求可以伪造自己的头信息,从而使机制失效。
六、代理
正向代理与反向代理的区别在于,代理的对象不一样。
正向代理是为客户端服务的,代理为客户端发请求,并将服务器传回的请求送回客户端。
反向代理是为服务端服务的,代理为服务端分发来自客户端的请求,并回应统一传回给客户端。
6.1 proxy_pass
Syntax: proxy_pass {{URL}};
Context: location, if in location, limit_except
URL 可以写如
http://localhost:8000/uri/https://192.168.1.1:8000/uri/http://unix:/tmp/backend.socket:/uri/
6.2 例
location / {if ( $http_x_forwarded_for !~* "^116\.62\.103\.228") {return 403;}}
如果代理的客户源不是指定的 IP 地址,则禁止访问。
6.3 proxy_buffering
Syntax: proxy_buffering on | off;
Default: proxy_buffering on;
Context: http, server, location
on 时尽可能缓冲一定的请求响应,再发回客户端。
扩展:proxy_buffer_size, proxy_buffers, proxy_busy_buffers_size
6.4 proxy_redirect
Syntax: proxy_redirect default | off | redirect {{replacement}};
Default: proxy_redirect default;
Context: http, server, location
6.5 http_header
当后端 server 需要读取头信息的时候,它可以在代理时负责传入请求。
Syntax: proxy_set_header {{field}} {{value}};
Default: proxy_set_header Host $proxy_host;
proxy_set_header Connection close;
Context: http, server, location
扩展:proxy_hide_header、proxy_set_body
6.6 proxy_connect_timeout
作为代理时的请求连接超时。
Syntax: proxy_connect_timeout time;
Default: proxy_connect_timeout 60s;
Context: http, server, location
