@ShawnNg
2017-02-05T08:10:42.000000Z
字数 7030
阅读 5496
从头学起深度学习应用于自然语言处理-词向量
深度学习 NLP
1 引言
在计算机视觉中,图片作为输入可以直接数值化。在语音识别中,音频也可以直接数值化。而自然语言处理中,文字是不可以直接数值化的,为了让机器能够处理文字,我们需要将文字映射到一个数值空间中。由于词是语义的基本单位,因此对于词的表示尤为重要,我们称词的数值表示为Word Representation,而我们现在所说的词向量经常是指Word embedding,也叫做Distributed Word Representation。为了方便,文中用词表征代表Word Representation,用词向量代表Word embedding。
2 本章介绍
从Word Representation的发展过程引入Word embedding,先从简单的SVD开始介绍,然后到NNLM、word2vec等词向量模型。
3 参考文章
- From Frequency to Meaning: Vector Space Models of Semantics
- A Neural Probabilistic Language Model
- Efficient Estimation of Word Representations in Vector Space
- Distributed Representations of Words and Phrases and their Compositionality
- CS 224D: Deep Learning for NLP - Lecture Notes: Part I
- word2vec数学原理
4 One-hot编码
这是一种十分简单的词表征方式,每个词使用一个的向量表示,是词表的大小。比如:
使用one-hot编码的词向量之间是相互独立的,因为对于每个词,所以不能比较两个词之间的相似度,丢失了关键的语义。
5 基于矩阵分解的词表征
5.1 词–文档矩阵(Word-Document Matrix)
如果我们有大量文档,我们用一个矩阵来存储所有的文档的词频信息。矩阵的行向量代表词,列向量代表文档,每个元素代表词在文档中出现的频数。比如我们有两篇文档:
1. I love NLP
2. I love deep learning
经过统计次数,我们可以得到以下矩阵:
如果两个文档有相似的主题,那么两个文档的列向量会趋于有相似类型的词数量。该模型主要用于衡量文档主题的相似性。
5.2 基于窗口的词共现矩阵(Window based Co-occurrence Matrix)
给定一个词,计算在一个限定大小的窗口中出现的其他词的次数。我们将这些计数放在一个矩阵中,矩阵的行表示词,列也是词。假如窗口大小为1,我们需要计算当前词左右两边的两个词。比如,我们两个句子:
1. I love NLP
2. I love deep learning
窗口长度为1,我们得到的矩阵为:
5.3 SVD(Singular Value Decomposition)
SVD,奇异值矩阵分解。对于任意一个矩阵都可以做奇异值分解:
其中是矩阵的奇异值。
5.4 LSA(Latent Semantic Analysis)
在上述的两种矩阵中,都存在一些问题。比如有大量的文档和词的时候,我们得到的矩阵会很庞大,而且会出现矩阵稀疏问题。后来,有人为了提高相似度的计算准确度,提出了对矩阵进行SVD分解,可以得到更好的词表征。这种方法称为LSA,潜在语义分析。LSA是为了研究词表征,另外还有类似的研究文档表征的方法叫LSI(Latent Semantic Index)。
我们通过计数统计得到了词-文档矩阵或者词共现矩阵,然后对矩阵使用SVD,取最大的个奇异值,由于每个奇异值对应于的列,因此得到,每一行代表一个词表征,因此可以得到维的词表征。
- 优点:
- 降低矩阵稀疏度
- 减少噪声
- 缺点:
- 有新词登录或者新的语料出现时,矩阵需要重新计算
- 矩阵维数过高
- 矩阵过于稀疏,因为很多词不能共现
- SVD分解计算时间度不低
- 会出现过高或者过低的词频
然而,word embedding能够解决上述的问题。
6 基于迭代的词表征(词向量)
虽然基于迭代的词表征也是得到一个稠密的向量。但与矩阵分解不同的是,词向量是通过迭代训练模型得到的。
6.1 NNLM[1]
这个模型由Bengio大神于2003年发表,可以说是Neural Language Model的开山之作。本来作者的主要目的是建立语言模型,结果发现了词向量这种副产品,由此引发了后人对词向量的火热研究。想具体了解可以阅读我的另一篇NNLM的论文阅读笔记。
模型使用了一个简单的前向神经网络,网络结构如下图:

该模型是通过上文来预测下一个词。图中的输入是上文的各个词,然后将它们的词向量连接起来。输出是每个词的概率,从而建立一个语言模型。图中虚线表示词向量层与输出层的直连。
6.2 Word2vec[2]
相信大家都很熟悉Word2vec这个工具,这是Tomas Mikolov在Google的时候出产的训练词向量的工具。其实Tomas也是一个大神啊,Bengio在NNLM的文末就曾经提到可以用RNN来做语言模型,后来Tomas就顺着这个方向发表了两篇用RNN来做语言模型的论文,然后为了专门训练词向量就研究出了Word2vec。
其实Word2vec这个工具中有两个模型(CBOW、Skip-Gram),还有两种加速训练的trick(层次Softmax、负采样),下面分别一一讲述。
首先对符号进行说明:
- 表示词
- 表示one-hot编码
- 和表示词向量
- 表示one-hot编码中对应词位置的值,取值为0或1,只有一个位置上的值为1。
6.2.1 CBOW(Continuous Bag-of-word Model)
这个模型的结构跟NNLM很像,但是用上下文预测中间的词,网络结构如下:

说明:
其实模型中存在两套词向量。- 一套称为Input词向量,用矩阵表示,是指词表大小,是指词向量维度。
- 一套称为Output词向量,用矩阵表示。
建模过程:
确定一个窗口大小。
选定目标词位置,得到该位置的上下文:
得到上下文各个词的one-hot表示:
使用矩阵,计算得到上下文的词向量(对应图中的INPUT层):
将上下文的词向量相加或者平均,得到。(对应图中的PROJECTION层):
使用矩阵,计算目的词的概率分布(对应图中的OUTPUT层)
使用负对数似然(又称交叉熵)损失函数:
训练过程:
选取batch大小
使用SGD训练,对于每个训练样本的损失函数,构造batch的损失函数:
每一轮迭代更新和
6.2.2 Skip-Gram(Continuous Skip-gram Model)
既然可以用上下文来预测目标词,那为何不能用目标词来预测上下文呢,因此Skip-Gram就应运而生。

与CBOW一样,模型中存在两套词向量和。
建模过程:
确定Context的窗口大小。
选取一个目标词,然后在目标词的Context中的选择一个词,组成训练样本:
得到训练样本的one-hot表示为:
使用矩阵,得到目标词的词向量(对应图中INPUT层):
由于只有一个词,所以不需要相加或者平均,直接复制到下一层(对应PROJECTION层):
使用矩阵,计算上下文中的词的概率分布(对应图中的OUTPUT层):
使用负对数似然(又称交叉熵)损失函数:
训练过程:
选取batch大小
使用SGD训练,对于每个训练样本的损失函数,构造batch的损失函数:
每一轮迭代更新和
6.2.3 加速技巧
Word2vec的训练是无监督的,我们只需要分好词,在训练的时候像有监督一样进行梯度下降。因此,在训练模型的时候,我们需要同时更新和。
从公式可以看出,每次迭代只需要更新矩阵中的少量向量(Skip-Gram中是一个)。然而如果我们使用简单的Softmax,我们就要每次都更新整个,假如词表大小到达千万级以上,可想而知这是多么耗时。因此,我们需要一些Trick来加速训练。
6.2.3.1 层次Softmax(Hierarchical Softmax)
层次Softmax是其中一个加速技巧,使用一棵二叉树来表示输出层的节点。我们可以通过统计每个词的词频构造一棵哈夫曼树。
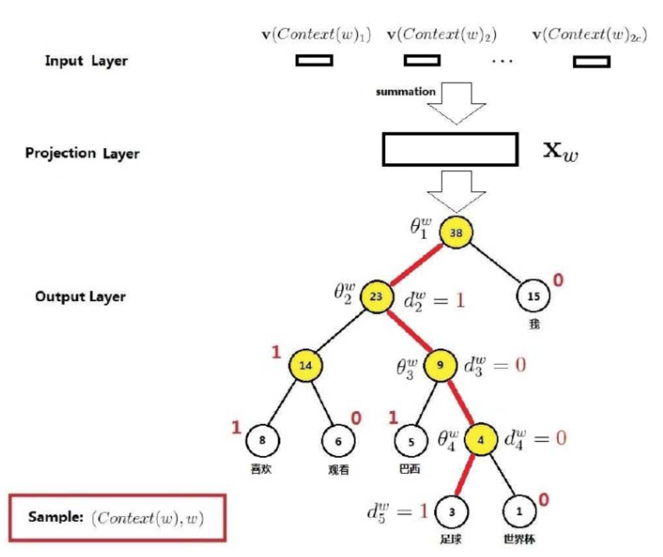
与Full Softmax不同的是,输出层是一颗Huffman树,其叶子结点有个,非叶子结点有个,每一个叶子结点代表一个词,每一个叶子结点都有唯一一条从根节点出发的路径。接下来,详细说说其前向传播的步骤:
- 按照词频构建Huffman树,并且确定哪边是正类,图中左边为正类。
- 在Projection Layer之前,和前面讲述的一样,得到向量。
- 将从根节点出发,使用辅助变量,做二分类:
- 如果,则分为正类,到达左孩子。反之,到达右孩子。
- 重复3、4步,直到到达叶子节点。
- 到达叶子节点时,这条路径的所有概率相乘就是该词的概率。
可以发现,Full Softmax在计算输出层时,要计算整个词表的概率分布。而
Hierachical Softmax不同,只要沿着一条路径计算二分类,从而得到概率最大的那个叶子节点,并且在后向传播的过程中,只需要更新路径上的辅助变量和输入的词向量。
6.2.3.2 负采样(Negative Sampling)
Negative Sampling是另一种加速方法,它在加速的同时还可以提高词向量的质量。负采样,顾名思义,就是要构造负样本。并且将模型变成了二分类问题。以下内容以CBOW模型为例子介绍负采样。
- 在语料中选择一个样本,并且通过随机采样得到几个其他词,构造几个负样本。
- 通过同样的步骤得到。
- 使用词对应的输出空间的词向量计算二分类概率:
这时完全可以将这个模型看做是二分类模型了,这样训练速度就会大大提高。
