@MatheMatrix
2025-02-14T08:54:32.000000Z
字数 1369
阅读 187
显存计算器
简介
这里有两个计算器,一个是面向单机单卡、单机多卡场景,另一个面向多机多卡场景。
一般来说,建议尽量单机推理,这样没有通信损失,性能最好。
目前 NVIDIA GPU 最大显存为 141 GB(H200、H20)、AMD GPU 最大显存分别为 192 GB(MI300X),对应单机最大提供 1128GB、1536GB 显存。
注意,AIOS 允许“上下文抢占”,也就是根据计算器算出来如果支持 8 并发 4K 上下文并发,那么 4 并发 8K 上下文、2 并发 16K 上下文、1 并发 32K 上下文都是可以。
使用说明
举例 1:
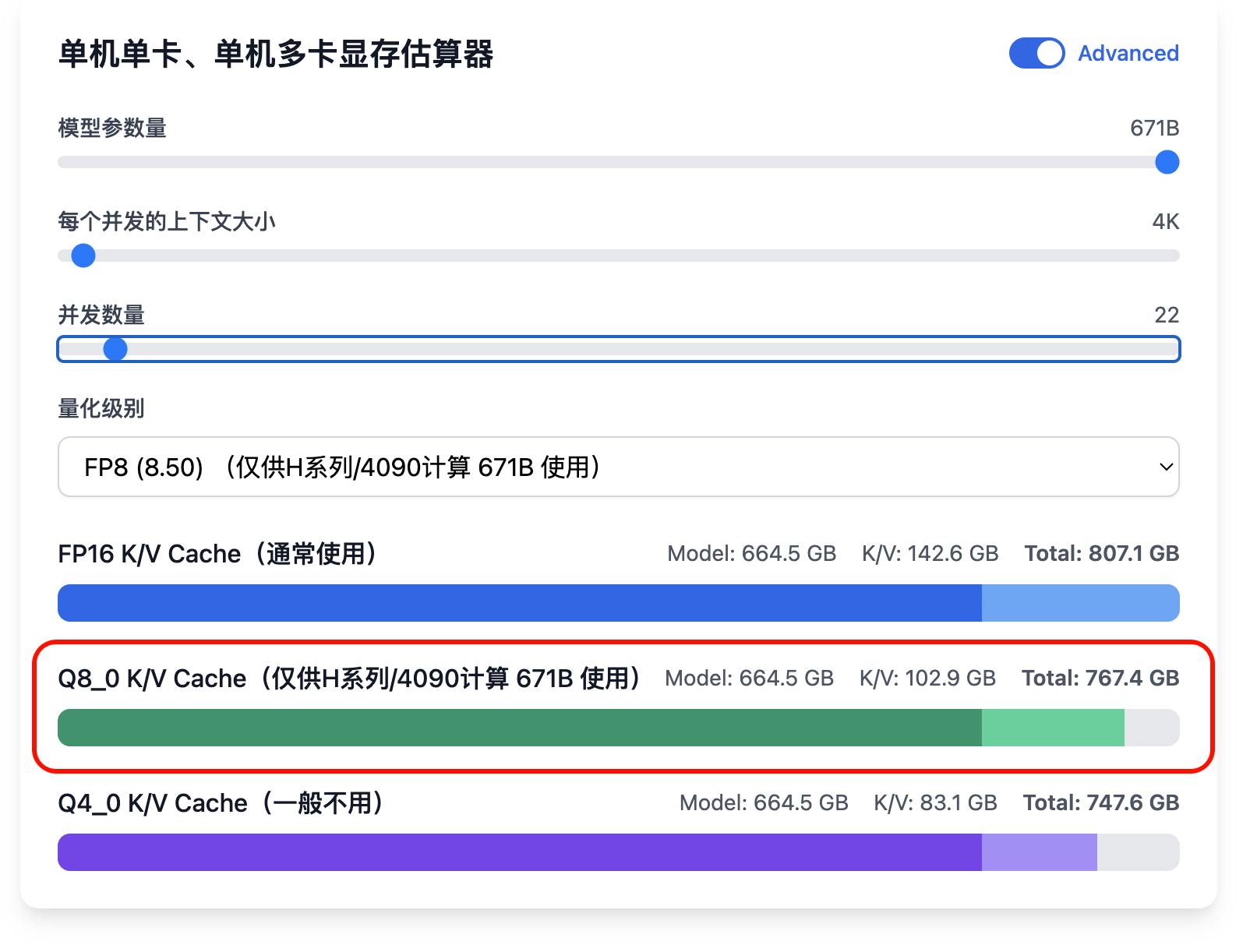
假设我们期望推算 671B 在 8 卡 H20 141GB 可提供并发数量(只考虑显存),因为 8 卡 H20 141GB 总计 1128 GB 显存, 单机多卡即可完成推理,因此打开单机多卡计算器:
- 模型参数量选择 671B
- 每个并发默认用 4K 上下文
- 量化级别选 FP8(因为 H20、H200、H100、H800、4090、MI300X 均支持 FP8)
- 并发量选择 64
此时发现 Q8_0 K/V Cache(仅供H系列/4090计算 671B 使用) 显示为 963.9 GB,接近于 1128 GB,因此每个并发 4K 上下文可以提供 64 并发,如果想要更精细的值,可以打开“Advanced”,并发量选择 99,发现此时显存为 1127.7 GB,正好用满————注意这样用很可能因为其他占用导致显存不足,最好留 10% 的 buffer。
举例 2:
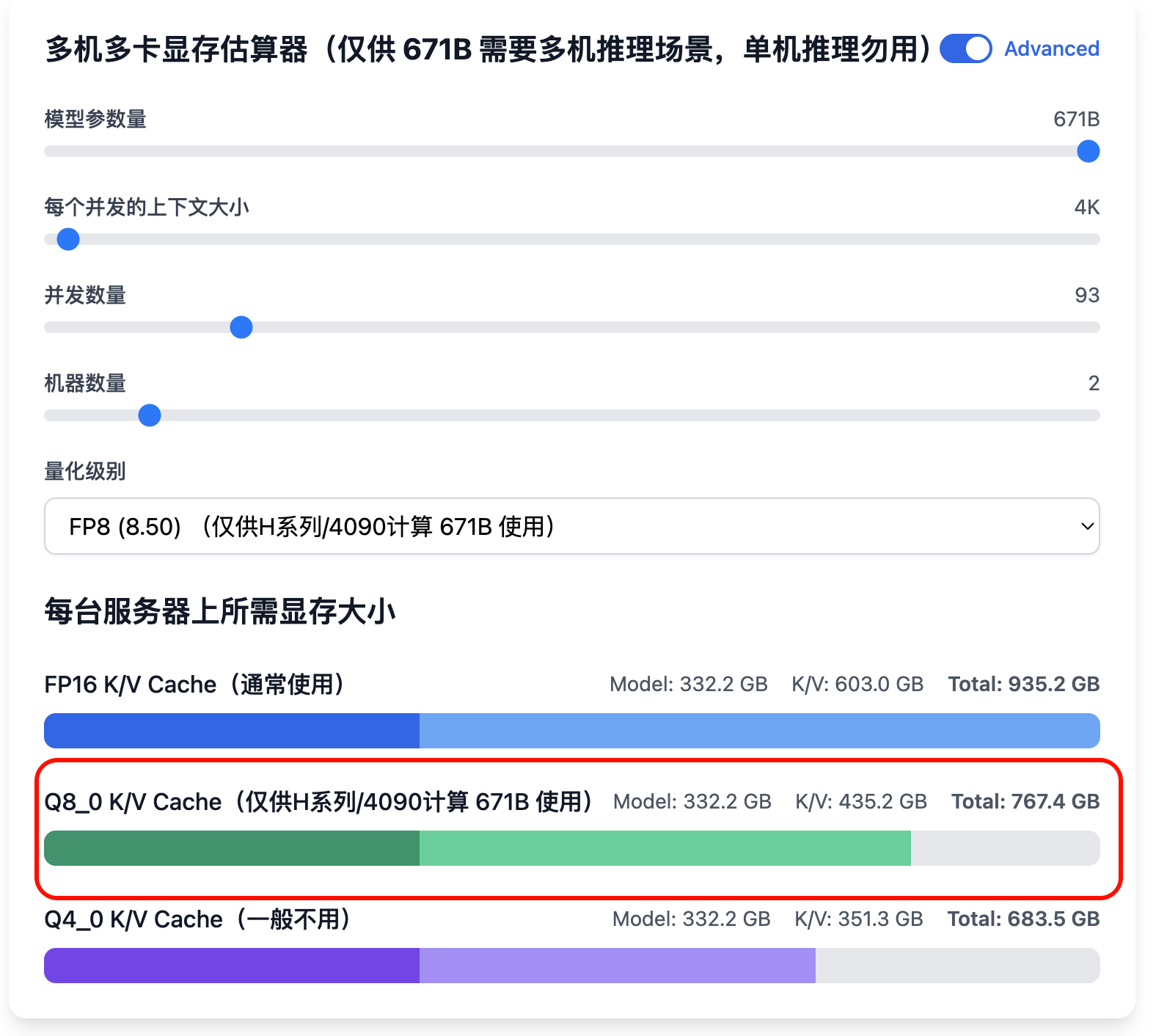
假设我们期望推算 671B 在 8 卡 H100 96GB 可提供并发数量(只考虑显存),因为 8 卡 H100 96GB 总计 768 GB 显存不太够, 需要多机多卡,因此打开多机多卡计算器:
- 模型参数量选择 671B
- 每个并发默认用 4K 上下文
- 量化级别选 FP8(因为 H20、H200、H100、H800、4090、MI300X 均支持 FP8)
- 并发量选择 64
此时发现 Q8_0 K/V Cache(仅供H系列/4090计算 671B 使用) 显示为 631 GB,接近于 768 GB,因此每个并发 4K 上下文 的话可以提供 64 并发,两台机器合计 128 并发,如果想要更精细的值,可以打开“Advanced”,并发量选择 93,发现此时显存为 767 GB,正好用满。
举例 3:
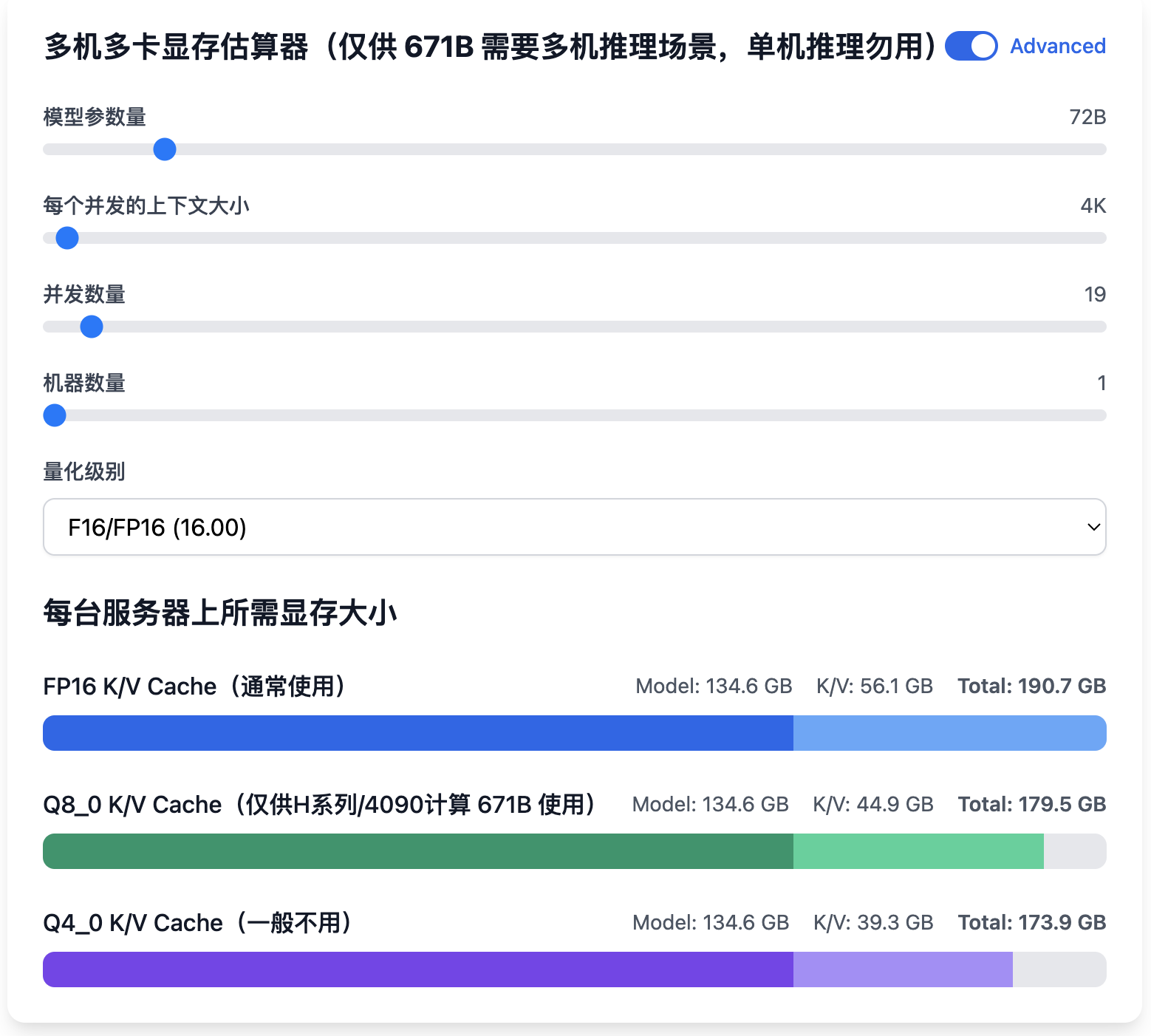
假设我们期望推算 72B 在 4 卡 L20 48GB 可提供并发数量(只考虑显存),因为 4 卡 L20 48GB 总计 192 GB 显存,单机单卡即可,因此打开单机多卡计算器,打开 Advanced:
- 模型参数量选择 72B
- 每个并发默认用 4K 上下文
- 量化级别选 FP16
- 并发量选择 19
此时发现 Q8_0 K/V Cache(仅供H系列/4090计算 671B 使用) 显示为 190.7 GB,接近于 192 GB,因此每个并发 4K 上下文 的话可以提供 19 并发。
举例 4:
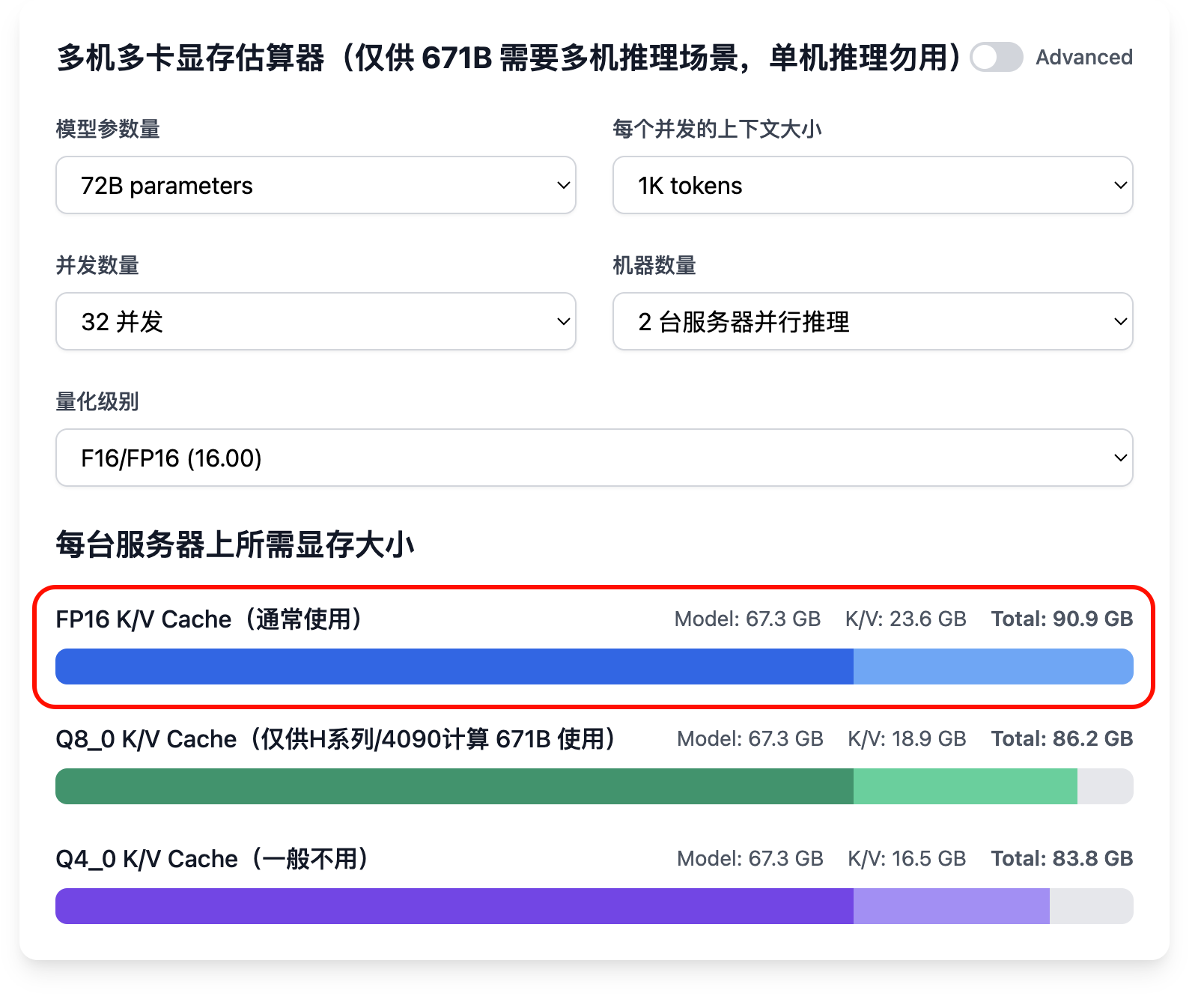
已知条件:300 并发,每个并发平均 1K 上下文,模型为 72B,采用 4 卡 4090 24GB 推理,需要多少服务器?
首先计算需要多少服务器可以装载模型:4 卡 4090 24GB 可提供 96 GB 显存,无法装载 72B 全精度模型,因此需要两台服务器并行推理。
参考前面举例 3 算得每台机器上可以支撑 32 路并发,那么两台服务器共支撑 64 路并发,300 并发需要 300/64=4.68,所以就是 4.68*2 ≈ 10 台。
高级用法
如果你了解了模型的量化、显存的量化(AIOS 目前支持比较有限)则可以更为灵活的使用本计算器,但由于计算器并没有花很多时间测试,因此使用时最好用直觉过一下,防止代码有 bug。
